什么是数据标签
标记(或注释)是识别值得建模的输入和输出(而不仅仅是可以建模的内容)的过程。
- 使用目标作为指导来确定必要的信号。
- 探索创建新信号(通过组合特征、收集新数据等)。
- 迭代地添加更多功能以证明复杂性和工作量。
warning
注意不要在数据集中包含预测期间不可用的特征,从而导致数据泄漏。
还能学到什么?
这不仅仅是识别和标记初始数据集。还能从中学到什么?
显示答案
这也是可以利用对问题、流程、约束和领域专业知识的深刻理解来:
- augment the training data split
- enhance using auxiliary data
- simplify using constraints
- remove noisy samples
- improve the labeling process
过程
无论有自定义标签平台还是选择通用平台,标签过程及其所有相关工作流程(QA、数据导入/导出等)都遵循类似的方法。
预备步骤
[WHAT]确定需要标记的内容:- 识别您可能已经拥有的自然标签(例如时间序列)
- 咨询领域专家以确保您标记了适当的信号
- 为您的任务决定适当的标签(和层次结构)
[WHERE]设计标注界面:- 直观、依赖于数据模式且快速(键绑定是必须的!)
- 通过允许标记者更深入地挖掘或建议可能的标签来避免选项瘫痪
- 测量和解决贴标签者之间的差异
[HOW]撰写标签说明:- 每个标签场景的示例
- 差异的行动方案
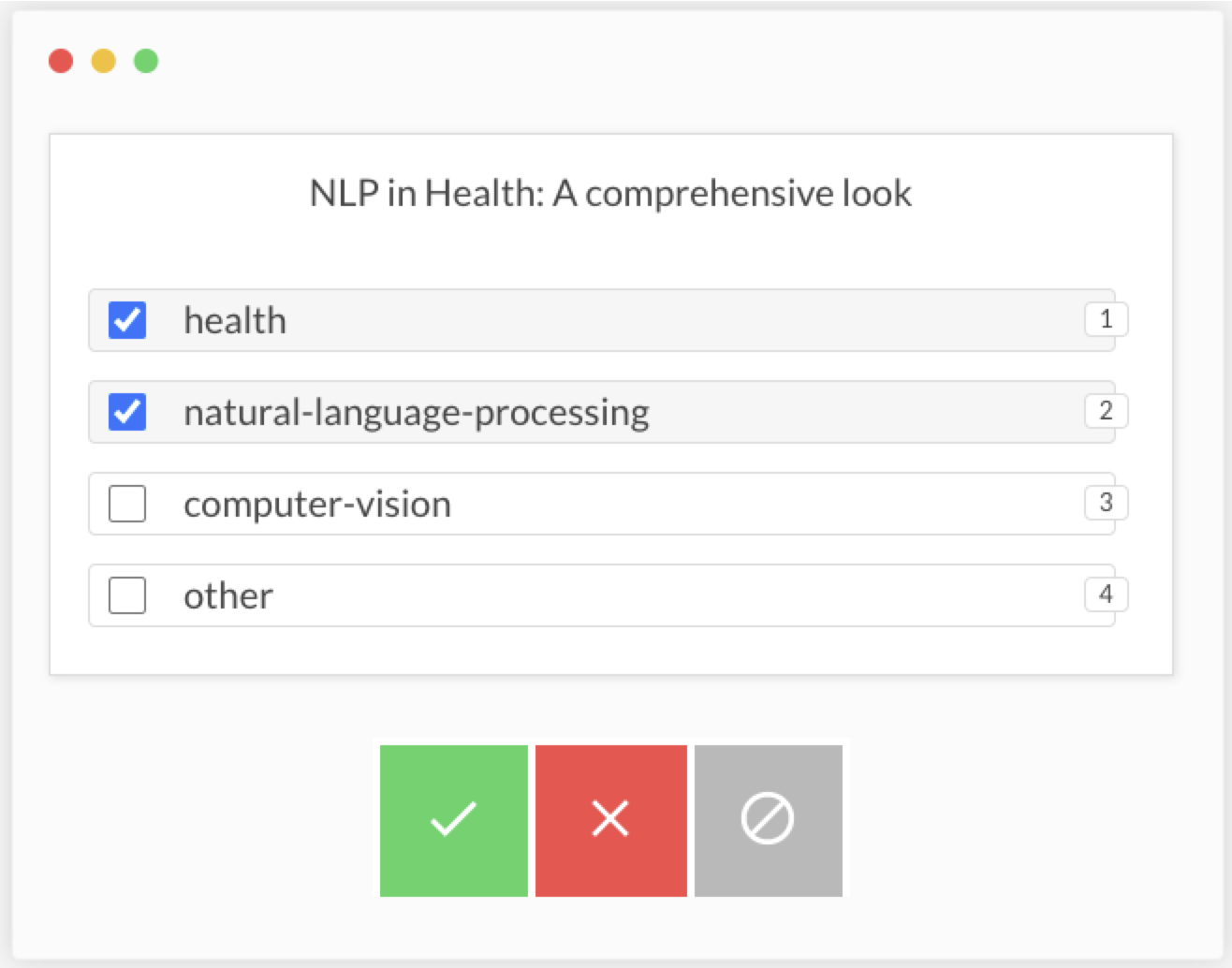
使用Prodigy(标签 + QA)为任务进行多标签文本分类
工作流程设置
- 建立数据管道:
[IMPORT]用于注释的新数据[EXPORT]用于 QA、测试、建模等的注释数据。
- 创建质量保证 (QA) 工作流程:
- 与标签工作流程分开(无偏见)
- 与标签工作流程沟通以升级错误
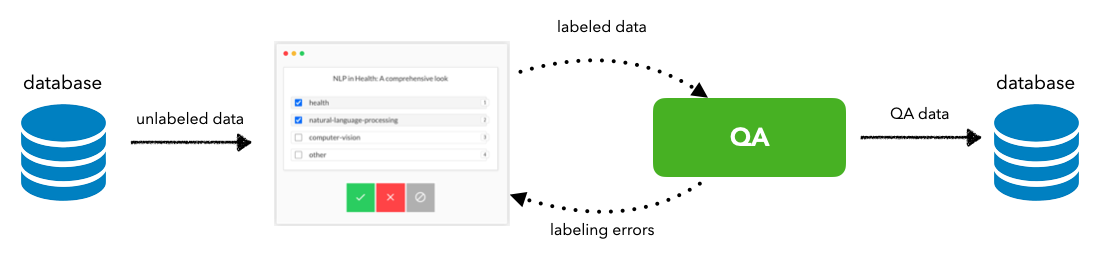
迭代设置
标记数据
出于本课程的目的,数据已经被标记,因此将执行基本版本的 ELT(提取、加载、转换)来构建标记数据集。
- projects.csv:带有 ID、创建时间、标题和描述的项目。
- tags.csv:项目的标签(标签类别)按 id。
回想一下,目标是对传入的内容进行分类,以便社区可以轻松发现它们。这些数据assert将作为第一个模型的训练数据。
提炼
将从来源(外部 CSV 文件)中提取数据开始。传统上,数据assert将在数据库、仓库等中存储、版本化和更新。稍后将详细了解这些不同的数据系统,但现在,将以独立的 CSV 文件形式加载数据。
import pandas as pd
# Extract projects
PROJECTS_URL = "https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv"
projects = pd.read_csv(PROJECTS_URL)
projects.head(5)
| ID | 创建于 | 标题 | 描述 | |
|---|---|---|---|---|
| 0 | 6个 | 2020-02-20 06:43:18 | YOLO和RCNN在真实世界上的比较… | 将理论用于实验很酷。可以 … |
| 1个 | 7 | 2020-02-20 06:47:21 | 显示、推理和讲述:C 的上下文推理… | 作品的美妙之处在于它的拱形方式…… |
| 2个 | 9 | 2020-02-24 16:24:45 | 很棒的图分类 | 重要图嵌入的集合,类… |
| 3个 | 15 | 2020-02-28 23:55:26 | 很棒的蒙特卡洛树搜索 | 蒙特卡洛树搜索论文的精选列表…… |
| 4个 | 19 | 2020-03-03 13:54:31 | 扩散到矢量 | Diffusion2Vec 的参考实现(Com… |
还将为项目加载标签(标签类别)。
# Extract tags
TAGS_URL = "https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv"
tags = pd.read_csv(TAGS_URL)
tags.head(5)
| ID | 标签 | |
|---|---|---|
| 0 | 6个 | 计算机视觉 |
| 1个 | 7 | 计算机视觉 |
| 2个 | 9 | 图学习 |
| 3个 | 15 | 强化学习 |
| 4个 | 19 | 图学习 |
转换
应用基本转换来创建标记数据集。
# Join projects and tags
df = pd.merge(projects, tags, on="id")
df.head()
| ID | 创建于 | 标题 | 描述 | 标签 | |
|---|---|---|---|---|---|
| 0 | 6个 | 2020-02-20 06:43:18 | YOLO和RCNN在真实世界上的比较… | 将理论用于实验很酷。可以 … | 计算机视觉 |
| 1个 | 7 | 2020-02-20 06:47:21 | 显示、推理和讲述:C 的上下文推理… | 作品的美妙之处在于它的拱形方式…… | 计算机视觉 |
| 2个 | 9 | 2020-02-24 16:24:45 | 很棒的图分类 | 重要图嵌入的集合,类… | 图学习 |
| 3个 | 15 | 2020-02-28 23:55:26 | 很棒的蒙特卡洛树搜索 | 蒙特卡洛树搜索论文的精选列表…… | 强化学习 |
| 4个 | 19 | 2020-03-03 13:54:31 | 扩散到矢量 | Diffusion2Vec 的参考实现(Com… | 图学习 |
df = df[df.tag.notnull()] # remove projects with no tag
加载
最后,将在本地加载转换后的数据,以便可以将其用于机器学习应用程序。
# Save locally
df.to_csv("labeled_projects.csv", index=False)
library
本可以使用用户提供的标签作为标签,但如果用户添加了错误的标签或忘记添加相关标签怎么办。为了消除这种对用户提供黄金标准标签的依赖,可以利用标签工具和平台。这些工具允许对数据集进行快速、有组织的标记,以确保其质量。而不是从头开始并要求标签提供给定项目的所有相关标签,可以提供作者的原始标签并要求标签根据需要添加/删除。特定的标记工具可能需要定制或利用生态系统中的某些东西。
随着平台的发展,数据集和标签需求也会增长,因此必须使用支持所依赖的工作流程的适当工具。
一般的
- Labelbox:用于 AI 应用程序的高质量训练和验证数据的数据平台。
- Scale AI:提供高质量训练数据的 AI 数据平台。
- Label Studio:具有标准化输出格式的多类型数据标记和注释工具。
- 通用数据工具:在简单的 Web 界面或桌面应用程序中协作和标记任何类型的数据、图像、文本或文档。
- Prodigy:Prodigy 的食谱,完全可编写脚本的注释工具。
- Superintendent:一个基于 ipywidget 的交互式标签工具,用于为您的数据启用主动学习。
自然语言处理
计算机视觉
- LabelImg:图形图像注释工具和标记图像中的对象边界框。
- CVAT:一种免费的在线交互式视频和图像注释工具,用于计算机视觉。
- VoTT:用于从图像和视频构建端到端对象检测模型的电子应用程序。
- makesense.ai:一个免费使用的在线照片标记工具。
- remo:用于计算机视觉中的注释和图像管理的应用程序。
- Labelai:一种用于标记图像的在线工具,可用于训练 AI 模型。
声音的
- Audino:用于语音活动检测(VAD)、二值化、说话人识别、自动语音识别、情感识别任务等的开源音频注释工具。
- audio-annotator:用于注释和标记音频文件的 JavaScript 接口。
- EchoML:一个网络应用程序,用于播放、可视化和注释您的音频文件以进行机器学习。
各种各样的
- MedCAT:一种医学概念注释工具,可以从电子健康记录 (EHR) 中提取信息并将其链接到 SNOMED-CT 和 UMLS 等生物医学本体。
通用标签解决方案
应该使用什么标准来评估使用什么标签平台?
显示答案
重要的是选择一个通用平台,该平台具有适用于您的数据模态的所有主要标记功能,并且能够轻松定制体验。
- 连接到数据源(数据库、QA 等)有多容易?
- 进行更改(新功能、标签范例)有多容易?
- 处理数据的安全程度如何(本地、信任等)
然而,作为一种行业趋势,这种泛化与特殊性之间的平衡是很难达到的。如此多的团队投入了前期工作来创建定制标签平台或使用特定于行业的利基标签工具。
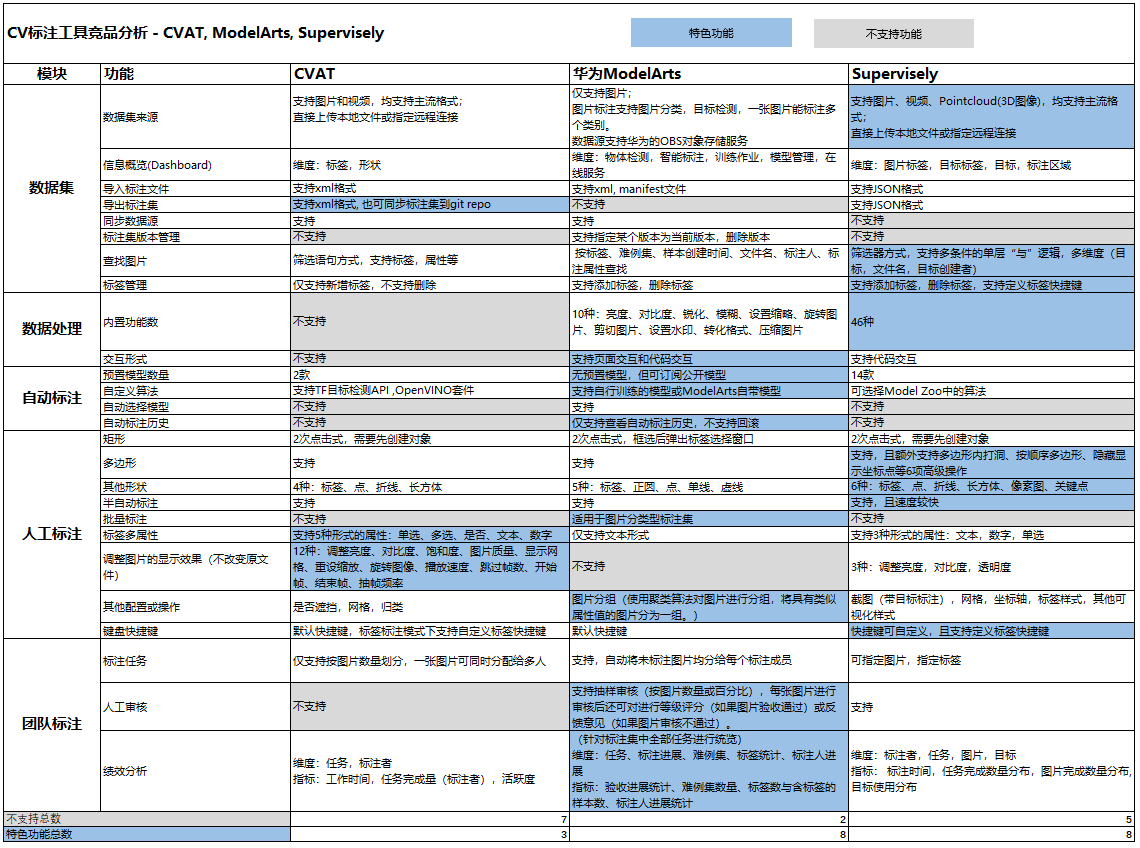
国内标注产品的功能总结
主动学习
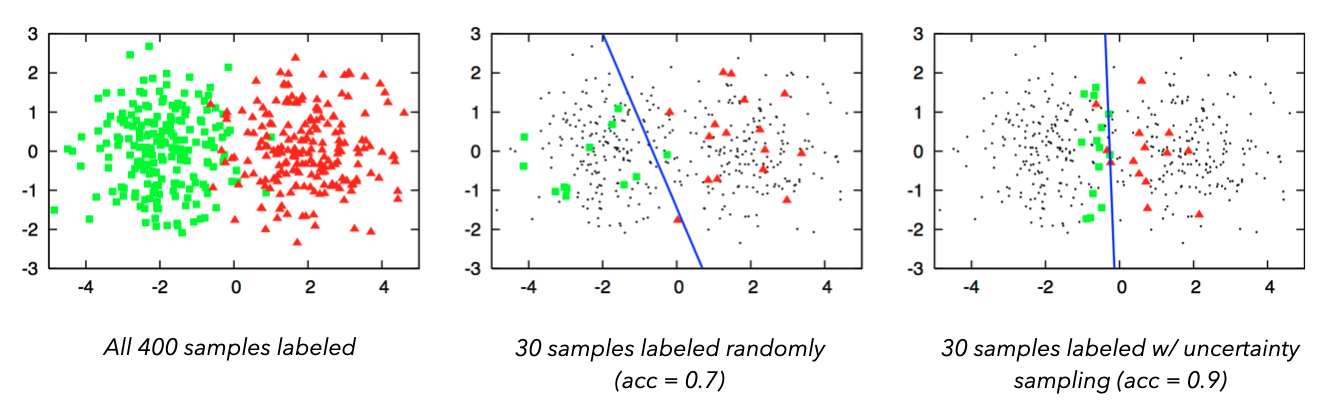
即使使用强大的标签工具和既定的工作流程,也很容易看出标签的复杂性和昂贵性。因此,许多团队采用主动学习来迭代标记数据集并评估模型。
- 标记一个小的初始数据集来训练模型。
- 要求经过训练的模型对一些未标记的数据进行预测。
- 根据以下内容确定未标记数据中要标记哪些新数据点:
- 预测类别概率的熵
- 预测、校准、置信度最低的样本(不确定性抽样)
- 训练模型集合的预测差异
- 重复直到达到所需的性能。
与标记整个数据集相比,这可以显着提高成本效益和速度。
library
- modAL:Python 的模块化主动学习框架。
- libact:Python 中基于池的主动学习。
- ALiPy : 主动学习 python 工具箱,可以让用户方便地评估、比较和分析主动学习方法的性能。
Weak supervision
如果有需要标记的样本,或者如果只是想验证现有标签,可以使用弱监督来生成标签,而不是手动标记所有标签。可以通过标签功能利用弱监督来标记现有的和新的数据,可以在其中创建基于关键字、模式表达式、知识库等的结构。可以随着时间的推移添加标签功能,甚至可以减轻不同数据之间的冲突标签功能。将在评估课程中使用这些标记函数来创建和评估数据切片。
from snorkel.labeling import labeling_function
@labeling_function()
def contains_tensorflow(text):
condition = any(tag in text.lower() for tag in ("tensorflow", "tf"))
return "tensorflow" if condition else None
验证标签(在建模之前)的一种简单方法是使用辅助数据集中的别名为不同的类创建标签函数。然后可以寻找假阳性和假阴性来识别可能被错误标记的样本。在仪表板课程中,实际上将实施一种类似的检查方法,但使用经过训练的模型作为启发式方法。
迭代
标签不仅仅是一次性事件或重复相同的事情。随着新数据的可用,将希望战略性地标记适当的样本并改进缺乏质量的数据片段。一旦标记了新数据,就可以触发工作流来启动(重新)培训过程以部署系统的新版本。
更多干货,第一时间更新在以下微信公众号:

您的一点点支持,是我后续更多的创造和贡献

转载到请包括本文地址 更详细的转载事宜请参考文章如何转载/引用
本文主体源自以下链接:
@article{madewithml,
author = {Goku Mohandas},
title = { Made With ML },
howpublished = {\url{https://madewithml.com/}},
year = {2022}
}