创建一个交互式仪表板以使用 Streamlit 直观地检查应用程序。
intution
在开发应用程序时,有很多技术决策和结果(预处理、性能等)是系统不可或缺的。如何才能有效地将其传达给其他开发人员和业务利益相关者?一种选择是 Jupyter notebook,但它经常被代码弄得乱七八糟,对于非技术团队成员来说访问和运行并不容易。需要创建一个无需任何技术先决条件即可访问并有效传达关键发现的仪表板。如果仪表板是交互式的,甚至为技术开发人员提供实用程序,那将更加有用。
streamlit
有一些很棒的工具选项,例如Dash、Gradio、Streamlit、Tableau、Looker等,用于创建仪表板以提供面向数据的见解。传统上,交互式仪表板是专门使用 HTML Javascript、CSS 等前端编程语言创建的。但是,鉴于许多从事机器学习工作的开发人员都在使用 Python,因此工具环境已经发展到弥合这一差距。这些工具现在允许 ML 开发人员在 Python 中创建交互式仪表板和可视化,同时通过 HTML、JS 和 CSS 提供完全自定义。将使用Streamlit创建仪表板,因为它具有直观的 API、共享功能和提高社区采用率。
设置
使用 Streamlit,可以快速创建一个空的应用程序,并且随着开发,UI 也会更新。
# Setup
pip install streamlit==1.10.0
mkdir streamlit
touch streamlit/app.py
streamlit run streamlit/app.py
您现在可以在浏览器中查看您的 Streamlit 应用程序。
本地网址:http://localhost:8501
网络网址:http://10.0.1.93:8501
这将在http://localhost:8501上自动为打开流光仪表板。
请务必将此包和版本添加到
requirements.txt文件中。
API 参考
在为特定应用程序创建仪表板之前,需要了解不同的 Streamlit 组件。不要在本课中全部阅读它们,而是花几分钟时间阅读API 参考。它很短,保证您会惊讶于仅使用 Python 就可以创建多少 UI 组件(样式文本、乳胶、表格、绘图等)。将详细探讨不同的组件,因为它们适用于为下面的特定仪表板创建不同的交互。
Sections
streamlit/app.py将首先通过编辑脚本来概述希望在仪表板中包含的部分:
import pandas as pd
from pathlib import Path
import streamlit as st
from config import config
from tagifai import main, utils
# Title
st.title("MLOps Course · Made With ML")
# Sections
st.header("🔢 Data")
st.header("📊 Performance")
st.header("🚀 Inference")
要在仪表板上查看这些更改,可以刷新仪表板页面(按R)或设置它Always rerun(按A)。
数据
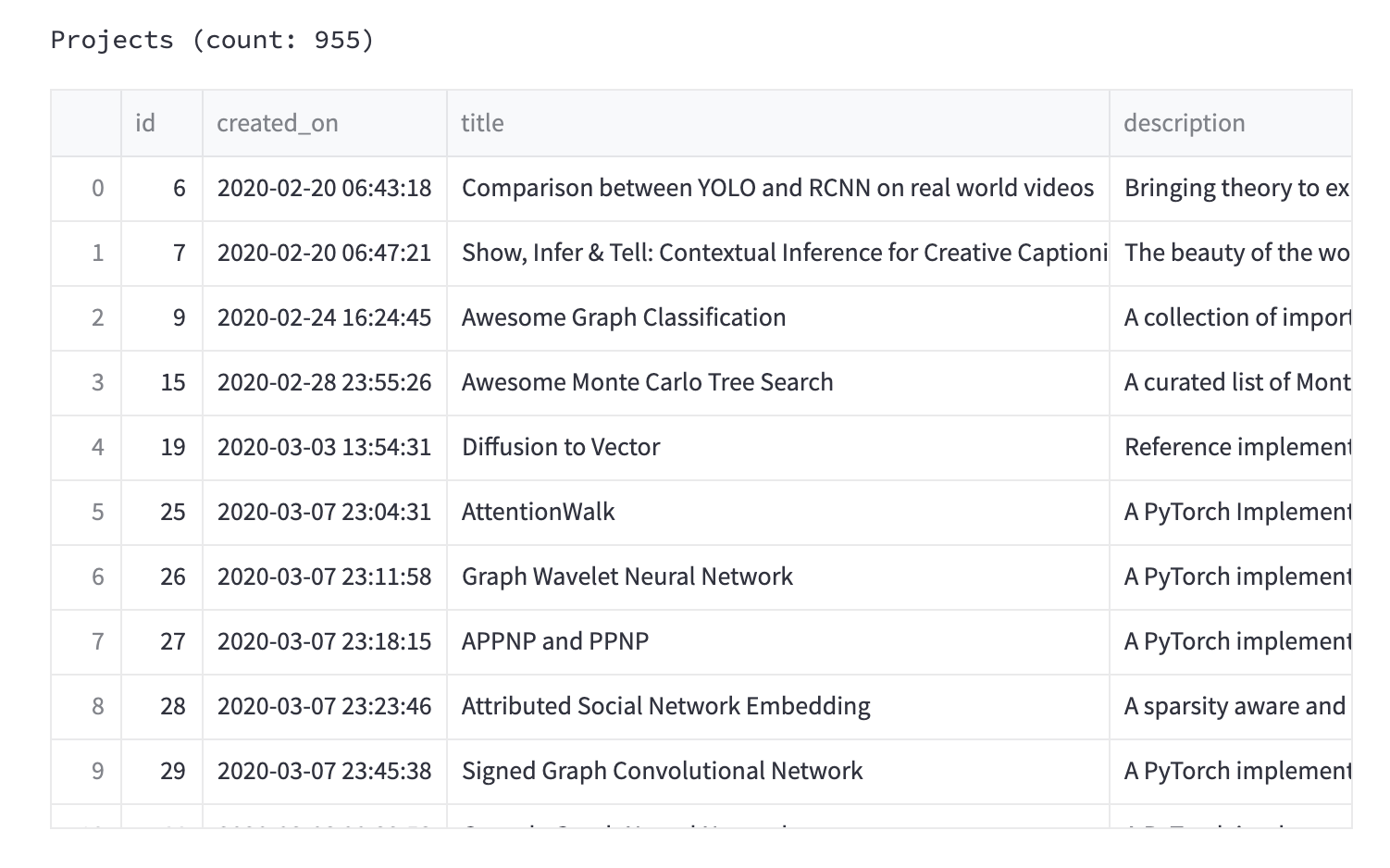
将保持仪表板简单,因此将只显示标记的项目。
st.header("Data")
projects_fp = Path(config.DATA_DIR, "labeled_projects.csv")
df = pd.read_csv(projects_fp)
st.text(f"Projects (count: {len(df)})")
st.write(df)
表现
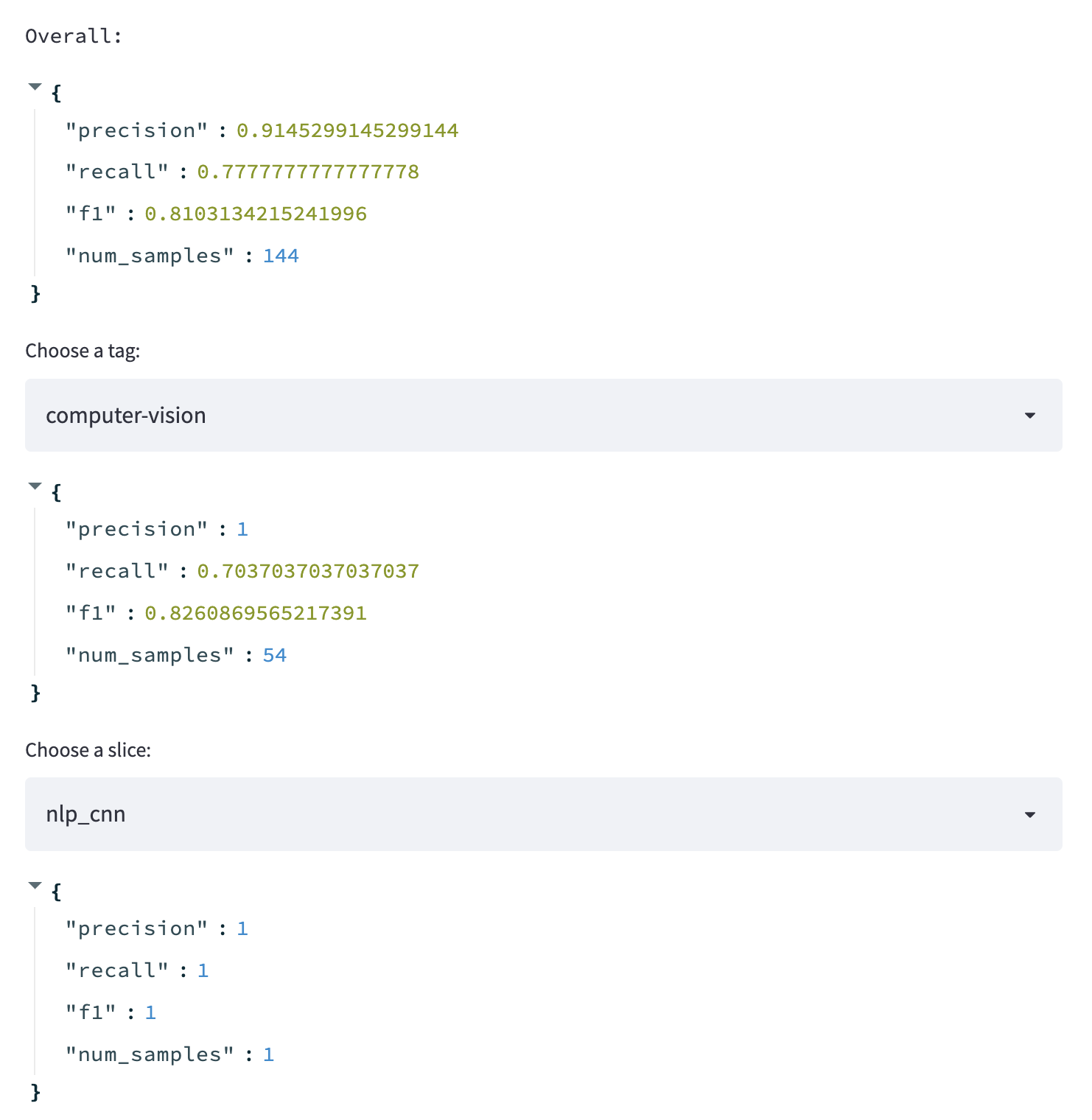
在本节中,将展示最新训练模型的性能。同样,将保持简单,但也可以通过访问模型存储来覆盖更多信息,例如以前部署的改进或回归。
st.header("📊 Performance")
performance_fp = Path(config.CONFIG_DIR, "performance.json")
performance = utils.load_dict(filepath=performance_fp)
st.text("Overall:")
st.write(performance["overall"])
tag = st.selectbox("Choose a tag: ", list(performance["class"].keys()))
st.write(performance["class"][tag])
tag = st.selectbox("Choose a slice: ", list(performance["slices"].keys()))
st.write(performance["slices"][tag])
推理
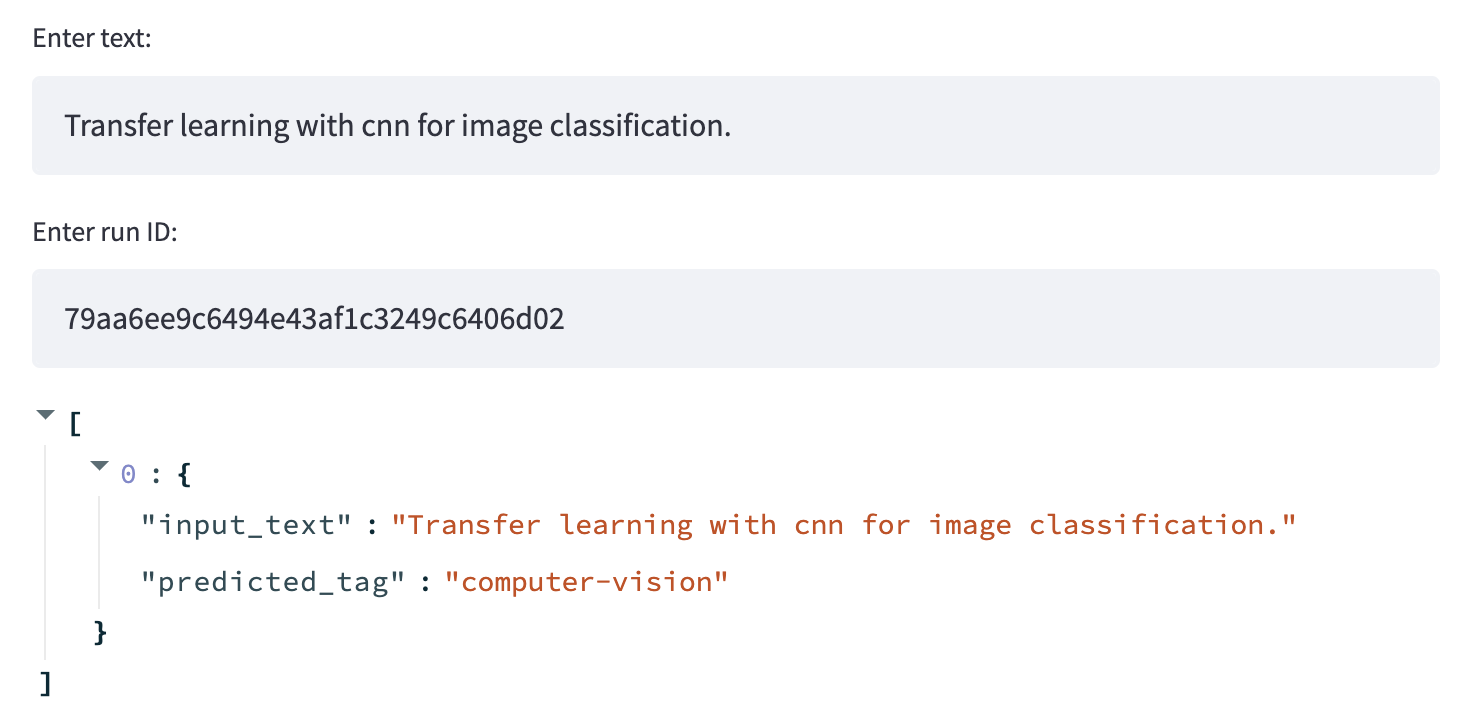
在推理部分,希望能够使用最新训练的模型进行快速预测。
st.header("🚀 Inference")
text = st.text_input("Enter text:", "Transfer learning with transformers for text classification.")
run_id = st.text_input("Enter run ID:", open(Path(config.CONFIG_DIR, "run_id.txt")).read())
prediction = main.predict_tag(text=text, run_id=run_id)
st.write(prediction)
Tip
仪表板非常简单,但还可以使用更全面的仪表板来反映在机器学习画布中涵盖的一些核心主题。
缓存
有时可能有涉及计算量大的操作的视图,例如加载数据或模型工件。最好的做法是通过使用@st.cache装饰器将它们包装为单独的函数来缓存这些操作。这要求 Streamlit 通过其输入的特定组合来缓存该函数,以在使用相同输入调用该函数时提供相应的输出。
@st.cache()
def load_data():
projects_fp = Path(config.DATA_DIR, "labeled_projects.csv")
df = pd.read_csv(projects_fp)
return df
部署
有几种不同的选项来部署和管理 Streamlit 仪表板。可以使用 Streamlit 的共享功能(测试版),它允许直接从 GitHub 无缝部署仪表板。随着向存储库提交更改,仪表板将继续保持更新。另一种选择是将 Streamlit 仪表板与 API 服务一起部署。可以使用 docker-compose 来启动一个单独的容器,或者简单地将其添加到 API 服务的 Dockerfile 的ENTRYPOINT并暴露适当的端口。后者可能是理想的,特别是如果您的仪表板不打算公开并且您希望增加安全性、性能等。
直接.pt文件inference部署,推理时间过长,一般达不到线上高并发高tps的要求
初识模型部署
在软件工程中,部署指把开发完毕的软件投入使用的过程,包括环境配置、软件安装等步骤。类似地,对于深度学习模型来说,模型部署指让训练好的模型在特定环境中运行的过程。相比于软件部署,模型部署会面临更多的难题:
-
运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。
-
深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。模型的运行效率需要优化。 因为这些难题的存在,模型部署不能靠简单的环境配置与安装完成。经过工业界和学术界数年的探索,模型部署有了一条流行的流水线:

为了让模型最终能够部署到某一环境上,开发者们可以使用任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。之后,模型的结构和参数会被转换成一种只描述网络结构的中间表示,一些针对网络结构的优化会在中间表示上进行。最后,用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写,能高效执行深度学习网络中算子的推理引擎会把中间表示转换成特定的文件格式,并在对应硬件平台上高效运行模型。
这一条流水线解决了模型部署中的两大问题:使用对接深度学习框架和推理引擎的中间表示,开发者不必担心如何在新环境中运行各个复杂的框架;通过中间表示的网络结构优化和推理引擎对运算的底层优化,模型的运算效率大幅提升。
现在,让从一个模型部署的“Hello World”项目入手,见识一下模型部署各方面的知识吧!
模型部署中常见的难题
-
模型的动态化。出于性能的考虑,各推理框架都默认模型的输入形状、输出形状、结构是静态的。而为了让模型的泛用性更强,部署时需要在尽可能不影响原有逻辑的前提下,让模型的输入输出或是结构动态化。
-
新算子的实现。深度学习技术日新月异,提出新算子的速度往往快于 ONNX 维护者支持的速度。为了部署最新的模型,部署工程师往往需要自己在 ONNX 和推理引擎中支持新算子。
-
中间表示与推理引擎的兼容问题。由于各推理引擎的实现不同,对 ONNX 难以形成统一的支持。为了确保模型在不同的推理引擎中有同样的运行效果,部署工程师往往得为某个推理引擎定制模型代码,这为模型部署引入了许多工作量。
更多干货,第一时间更新在以下微信公众号:

您的一点点支持,是我后续更多的创造和贡献

转载到请包括本文地址 更详细的转载事宜请参考文章如何转载/引用
本文主体源自以下链接:
@article{madewithml,
author = {Goku Mohandas},
title = { Made With ML },
howpublished = {\url{https://madewithml.com/}},
year = {2022}
}