鼓励使用基线模型进行迭代建模。
Intuition
基线是为迭代开发铺平道路的简单基准:
- 由于模型复杂度低,通过超参数调整进行快速实验。
- 发现数据问题、错误假设、代码中的错误等,因为模型本身并不复杂。
- 帕累托原则:可以用最少的初始努力实现良好的性能。
过程
这是建立基线的高级方法:
- 从最简单的基线开始,以比较后续开发。这通常是一个随机(机会)模型。
- 使用 IFTTT、辅助数据等开发基于规则的方法(如果可能)。
- _通过解决_限制和_激励_表示和模型架构来慢慢增加复杂性。
- 权衡性能基线之间的_权衡_(性能、延迟、大小等)。
- 随着数据集的增长,重新访问和迭代基线。
要考虑的权衡
在选择要进行的模型架构时,需要考虑哪些重要的权衡?如何优先考虑它们?
显示答案
这些权衡的优先级取决于您的上下文。
- performance`:考虑粗粒度和细粒度(例如每类)性能。
latency:您的模型对推理的响应速度有多快。size: 你的模型有多大,你能支持它的存储吗?compute:训练你的模型需要多少成本(美元、碳足迹等)?interpretability: 你的模型需要解释它的预测吗?bias checks:您的模型是否通过了关键偏差检查?time to develop: 你需要多长时间来开发第一个版本?time to retrain: 重新训练你的模型需要多长时间?如果您需要经常进行再培训,这一点非常重要。maintenance overhead:维护模型版本需要谁和什么,因为 ML 的真正工作是在部署 v1 之后开始的。您不能像许多团队对传统软件所做的那样,将其交给您的站点可靠性团队来维护它。
迭代数据
还可以在您的数据集上设置基线。不要使用固定的数据集并在模型上迭代,而是选择一个好的基线并在数据集上迭代:
- 删除或修复数据样本(误报和否定)
- 准备和转换特征
- 扩大或巩固班级
- 合并辅助数据集
- 识别要提升的独特切片
分布式训练
需要为应用程序做的所有训练都发生在一个工作人员和一个加速器(CPU/GPU)上,但是,会考虑对非常大的模型或在处理大型数据集时进行分布式训练。分布式训练可能涉及:
- 数据并行性:工作人员收到较大数据集的不同切片。
- 同步训练使用AllReduce聚合梯度并在每批结束时更新所有工作人员的权重(同步)。
- 异步训练使用通用参数服务器来更新权重,因为每个工作人员都在其数据片上进行训练(异步)。
- 模型并行性:所有工作人员使用相同的数据集,但模型在它们之间拆分(与数据并行性相比更难以实现,因为很难从反向传播中分离和组合信号)。
应用分布式训练有很多选择,例如 PyTorch 的分布式包、Ray、Horovd等。
优化
当数据或模型太大而无法训练时,分布式训练策略非常有用,但是当模型太大而无法部署时呢?以下模型压缩技术通常用于使大型模型适合现有基础架构:
- 修剪:删除权重(非结构化)或整个通道(结构化)以减小网络的大小。目标是保持模型的性能,同时增加其稀疏性。
- 量化:通过降低权重的精度(例如 32 位到 8 位)来减少权重的内存占用。可能会失去一些精度,但它不应该对性能产生太大影响。
- 蒸馏:训练较小的网络以“模仿”较大的网络,方法是让它重现较大网络层的输出。
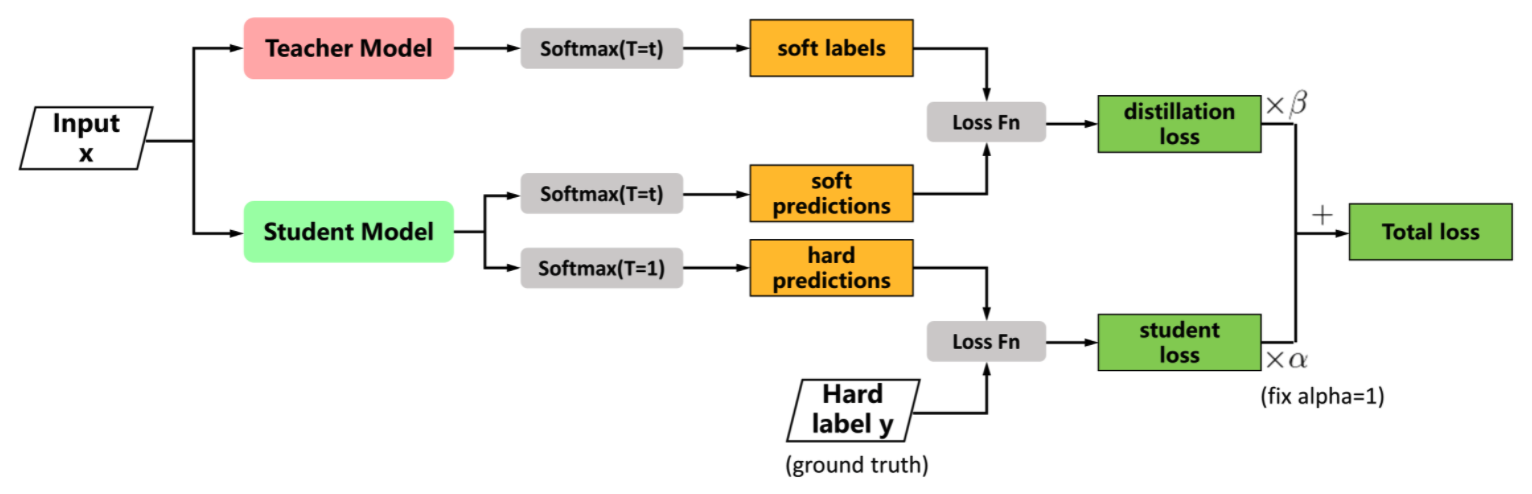
在神经网络中提取知识 [来源]
基线
每个应用程序的基线轨迹因任务而异。对于应用程序,将遵循以下路径:
将激发对缓慢增加表示(例如文本向量化)和架构(例如逻辑回归)的复杂性的需求,并解决每个步骤的限制。
如果您不熟悉此处的建模概念,请务必查看基础课程。
note
使用的特定模型与本 MLOps 课程无关,因为主要关注将模型投入生产和维护所需的所有组件。因此,在继续学习本note本之后的其他课程时,请随意选择任何model。
将首先设置一些将在不同基线实验中使用的函数。
import random
def set_seeds(seed=42):
"""Set seeds for reproducibility."""
np.random.seed(seed)
random.seed(seed)
def preprocess(df, lower, stem, min_freq):
"""Preprocess the data."""
df["text"] = df.title + " " + df.description # feature engineering
df.text = df.text.apply(clean_text, lower=lower, stem=stem) # clean text
# Replace OOS tags with `other`
oos_tags = [item for item in df.tag.unique() if item not in ACCEPTED_TAGS]
df.tag = df.tag.apply(lambda x: "other" if x in oos_tags else x)
# Replace tags below min_freq with `other`
tags_above_freq = Counter(tag for tag in tags.elements()
if (tags[tag] >= min_freq))
df.tag = df.tag.apply(lambda tag: tag if tag in tags_above_freq else None)
df.tag = df.tag.fillna("other")
return df
def get_data_splits(X, y, train_size=0.7):
"""Generate balanced data splits."""
X_train, X_, y_train, y_ = train_test_split(
X, y, train_size=train_size, stratify=y)
X_val, X_test, y_val, y_test = train_test_split(
X_, y_, train_size=0.5, stratify=y_)
return X_train, X_val, X_test, y_train, y_val, y_test
数据集很小,因此将使用整个数据集进行训练,但对于较大的数据集,应该始终在一个小子集上进行测试(在必要时进行改组之后),这样就不会在计算上浪费时间。
df = df.sample(frac=1).reset_index(drop=True) # shuffle
df = df[: num_samples] # None = all samples
需要洗牌吗?
为什么打乱数据集很重要?
显示答案
_需要_打乱数据,因为数据是按时间顺序组织的。与早期项目相比,最新项目可能具有某些流行的功能或标签。如果在创建数据拆分之前不进行洗牌,那么模型将只会在较早的信号上进行训练并且无法泛化。但是,在其他情况下(例如时间序列预测),洗牌会导致数据泄露。
随机的
动机:想知道随机(机会)表现是什么样的。所有的努力都应该远远高于这个基线。
from sklearn.metrics import precision_recall_fscore_support
# Set up
set_seeds()
df = pd.read_csv("labeled_projects.csv")
df = df.sample(frac=1).reset_index(drop=True)
df = preprocess(df, lower=True, stem=False, min_freq=min_freq)
label_encoder = LabelEncoder().fit(df.tag)
X_train, X_val, X_test, y_train, y_val, y_test = \
get_data_splits(X=df.text.to_numpy(), y=label_encoder.encode(df.tag))
# Label encoder
print (label_encoder)
print (label_encoder.classes)
<LabelEncoder(num_classes=4)> [‘computer-vision’, ‘mlops’, ‘natural-language-processing’, ‘other’]
# Generate random predictions
y_pred = np.random.randint(low=0, high=len(label_encoder), size=len(y_test))
print (y_pred.shape)
print (y_pred[0:5])
(144,) [0 0 0 1 3]
# Evaluate
metrics = precision_recall_fscore_support(y_test, y_pred, average="weighted")
performance = {"precision": metrics[0], "recall": metrics[1], "f1": metrics[2]}
print (json.dumps(performance, indent=2))
{ “precision”: 0.31684880006233446, “recall”: 0.2361111111111111, “f1”: 0.2531624273393283 }
假设每个类别都有相同的概率。让使用训练拆分来找出真正的概率是多少。
# Class frequencies
p = [Counter(y_test)[index]/len(y_test) for index in range(len(label_encoder))]
p
[0.375, 0.08333333333333333, 0.4027777777777778, 0.1388888888888889]
# Generate weighted random predictions
y_pred = np.random.choice(a=range(len(label_encoder)), size=len(y_test), p=p)
# Evaluate
metrics = precision_recall_fscore_support(y_test, y_pred, average="weighted")
performance = {"precision": metrics[0], "recall": metrics[1], "f1": metrics[2]}
print (json.dumps(performance, indent=2))
{ “precision”: 0.316412540257649, “recall”: 0.3263888888888889, “f1”: 0.31950372012322 }
限制:没有使用输入中的标记来影响预测,所以没有学到任何东西。
基于规则
动机:希望在输入中使用信号(以及领域专业知识和辅助数据)来确定标签。
# Setup
set_seeds()
df = pd.read_csv("labeled_projects.csv")
df = df.sample(frac=1).reset_index(drop=True)
df = preprocess(df, lower=True, stem=False, min_freq=min_freq)
label_encoder = LabelEncoder().fit(df.tag)
X_train, X_val, X_test, y_train, y_val, y_test = \
get_data_splits(X=df.text.to_numpy(), y=label_encoder.encode(df.tag))
def get_tag(text, aliases_by_tag):
"""If a token matches an alias,
then add the corresponding tag class."""
for tag, aliases in aliases_by_tag.items():
if replace_dash(tag) in text:
return tag
for alias in aliases:
if alias in text:
return tag
return None
# Sample
text = "A pretrained model hub for popular nlp models."
get_tag(text=clean_text(text), aliases_by_tag=aliases_by_tag)
‘natural-language-processing’
# Prediction
tags = []
for text in X_test:
tag = get_tag(text, aliases_by_tag=aliases_by_tag)
tags.append(tag)
# Encode labels
y_pred = [label_encoder.class_to_index[tag] if tag is not None else -1 for tag in tags]
# Evaluate
metrics = precision_recall_fscore_support(y_test, y_pred, average="weighted")
performance = {"precision": metrics[0], "recall": metrics[1], "f1": metrics[2]}
print (json.dumps(performance, indent=2))
{ “precision”: 0.9097222222222222, “recall”: 0.18055555555555555, “f1”: 0.2919455654201417 }
为什么召回率这么低?
为什么准确率很高,但召回率却如此之低?
显示答案
当输入信号中没有使用这些特定的别名时,仅依赖别名会证明是灾难性的。为了改进这一点,可以构建一个包含相关术语的词袋。例如,将诸如
text classification和之类的术语映射named entity recognition到natural-language-processing标签,但构建它是一项不平凡的任务。更不用说,随着数据环境的成熟,需要不断更新这些规则。
# Pitfalls
text = "Transfer learning with transformers for text classification."
print (get_tag(text=clean_text(text), aliases_by_tag=aliases_by_tag))
Tip
还可以使用词干提取来进一步完善基于规则的流程:
from nltk.stem import PorterStemmer stemmer = PorterStemmer() print (stemmer.stem("democracy")) print (stemmer.stem("democracies") )但是这些基于规则的方法只能在绝对条件匹配时产生具有高确定性的标签,因此最好不要在这种方法上花费太多精力。
限制:未能概括或学习任何隐式模式来预测标签,因为将输入中的标记视为孤立的实体。
矢量化
动机:
- 表示:使用词频-逆文档频率(TF-IDF)来捕获某个标记相对于所有输入对特定输入的重要性,而不是将输入文本中的单词视为孤立的标记。
- 架构:希望模型能够有意义地提取编码信号以预测输出标签。
到目前为止,已经将输入文本中的单词视为孤立的标记,并且还没有真正捕捉到标记之间的任何含义。让使用 TF-IDF(通过 Scikit-learn’s TfidfVectorizer)来捕获令牌对特定输入相对于所有输入的重要性。
$w_{i, j} = \text{tf}_{i, j} * log(\frac{N}{\text{df}_i})$

from sklearn.feature_extraction.text import TfidfVectorizer
# Setup
set_seeds()
df = pd.read_csv("labeled_projects.csv")
df = df.sample(frac=1).reset_index(drop=True)
df = preprocess(df, lower=True, stem=False, min_freq=min_freq)
label_encoder = LabelEncoder().fit(df.tag)
X_train, X_val, X_test, y_train, y_val, y_test = \
get_data_splits(X=df.text.to_numpy(), y=label_encoder.encode(df.tag))
# Saving raw X_test to compare with later
X_test_raw = X_test
# Tf-idf
vectorizer = TfidfVectorizer(analyzer="char", ngram_range=(2,7)) # char n-grams
print (X_train[0])
X_train = vectorizer.fit_transform(X_train)
X_val = vectorizer.transform(X_val)
X_test = vectorizer.transform(X_test)
print (X_train.shape) # scipy.sparse.csr_matrix
tao large scale benchmark tracking object diverse dataset tracking object tao consisting 2 907 high resolution videos captured diverse environments half minute long (668, 99664)
# Class weights
counts = np.bincount(y_train)
class_weights = {i: 1.0/count for i, count in enumerate(counts)}
print (f"class counts: {counts},\nclass weights: {class_weights}")
class counts: [249 55 272 92], class weights: {0: 0.004016064257028112, 1: 0.01818181818181818, 2: 0.003676470588235294, 3: 0.010869565217391304}
数据不平衡
对于数据集,可能经常会注意到数据不平衡问题,其中一系列连续值(回归)或某些类别(分类)可能没有足够的数据量可供学习。这在训练时成为一个主要问题,因为模型将学习泛化到可用数据并在数据稀疏的区域表现不佳。有几种技术可以缓解数据不平衡,包括重采样、合并类权重、增强等。尽管理想的解决方案是为少数类收集更多数据!
将使用imblearn 包来确保对少数类进行过采样以等于多数类(带有大多数样本的标签)。
pip install imbalanced-learn==0.8.1 -q
from imblearn.over_sampling import RandomOverSampler
# Oversample (training set)
oversample = RandomOverSampler(sampling_strategy="all")
X_over, y_over = oversample.fit_resample(X_train, y_train)
warning
重要的是,仅在训练拆分上应用采样,这样就不会在其他数据拆分中引入数据泄漏。
class counts: [272 272 272 272], class weights: {0: 0.003676470588235294, 1: 0.003676470588235294, 2: 0.003676470588235294, 3: 0.003676470588235294}
限制:
- 表示:TF-IDF 表示不封装超出频率的太多信号,但需要更细粒度的令牌表示。
- 架构:希望开发能够以更符合上下文的方式使用更好表示的编码的模型。
机器学习
将使用随机梯度下降分类器 ( SGDClassifier ) 作为模型。将使用对数损失,以便它有效地与 SGD 进行逻辑回归。
这样做是因为希望对训练过程(epochs)有更多的控制,而不是使用 scikit-learn 的默认二阶优化方法(例如LGBFS)进行逻辑回归。
from sklearn import metrics
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import log_loss, precision_recall_fscore_support
# Initialize model
model = SGDClassifier(
loss="log", penalty="l2", alpha=1e-4, max_iter=1,
learning_rate="constant", eta0=1e-1, power_t=0.1,
warm_start=True)
# Train model
num_epochs = 100
for epoch in range(num_epochs):
# Training
model.fit(X_over, y_over)
# Evaluation
train_loss = log_loss(y_train, model.predict_proba(X_train))
val_loss = log_loss(y_val, model.predict_proba(X_val))
if not epoch%10:
print(
f"Epoch: {epoch:02d} | "
f"train_loss: {train_loss:.5f}, "
f"val_loss: {val_loss:.5f}"
)
| Epoch: 00 | train_loss: 1.16930, val_loss: 1.21451 |
| Epoch: 10 | train_loss: 0.46116, val_loss: 0.65903 |
| Epoch: 20 | train_loss: 0.31565, val_loss: 0.56018 |
| Epoch: 30 | train_loss: 0.25207, val_loss: 0.51967 |
| Epoch: 40 | train_loss: 0.21740, val_loss: 0.49822 |
| Epoch: 50 | train_loss: 0.19615, val_loss: 0.48529 |
| Epoch: 60 | train_loss: 0.18249, val_loss: 0.47708 |
| Epoch: 70 | train_loss: 0.17330, val_loss: 0.47158 |
| Epoch: 80 | train_loss: 0.16671, val_loss: 0.46765 |
| Epoch: 90 | train_loss: 0.16197, val_loss: 0.46488 |
可以进一步优化训练管道,例如提前停止将使用创建的验证集的功能。但是希望在建模阶段简化这个与模型无关的课程
warning
SGDClassifier有一个标志,您可以在其中
early_stopping指定要用于验证的训练集的一部分。为什么这对来说是个坏主意?因为已经在训练集中应用了过采样,所以如果这样做,会引入数据泄漏。
# Evaluate
y_pred = model.predict(X_test)
metrics = precision_recall_fscore_support(y_test, y_pred, average="weighted")
performance = {"precision": metrics[0], "recall": metrics[1], "f1": metrics[2]}
print (json.dumps(performance, indent=2))
{ “precision”: 0.8753577441077441, “recall”: 0.8680555555555556, “f1”: 0.8654096949533866 }
Tip
Scikit-learn 有一个称为管道的概念,它允许将转换和训练步骤组合到一个可调用函数中。
可以从头开始创建管道:
# Create pipeline from scratch from sklearn.pipeline import Pipeline steps = (("tfidf", TfidfVectorizer()), ("model", SGDClassifier())) pipe = Pipeline(steps) pipe.fit(X_train, y_train)或使用训练有素的组件制作一个:
# Make pipeline from existing components from sklearn.pipeline import make_pipeline pipe = make_pipeline(vectorizer, model)
限制:
- 表示:TF-IDF 表示没有封装太多频率以外的信号,但需要更细粒度的令牌表示,以说明令牌本身的重要性(嵌入)。
- 架构:希望开发能够以更符合上下文的方式使用更好表示的编码的模型。
# Inference (with tokens similar to training data)
text = "Transfer learning with transformers for text classification."
y_pred = model.predict(vectorizer.transform([text]))
label_encoder.decode(y_pred)
[‘natural-language-processing’]
# Probabilities
y_prob = model.predict_proba(vectorizer.transform([text]))
{tag:y_prob[0][i] for i, tag in enumerate(label_encoder.classes)}
{‘computer-vision’: 0.023672281234089494, ‘mlops’: 0.004158589896756235, ‘natural-language-processing’: 0.9621906411391856, ‘other’: 0.009978487729968667}
# Inference (with tokens not similar to training data)
text = "Interpretability methods for explaining model behavior."
y_pred = model.predict(vectorizer.transform([text]))
label_encoder.decode(y_pred)
[‘natural-language-processing’]
# Probabilities
y_prob = model.predict_proba(vectorizer.transform([text]))
{tag:y_prob[0][i] for i, tag in enumerate(label_encoder.classes)}
{‘computer-vision’: 0.13150802188532523, ‘mlops’: 0.11198040241517894, ‘natural-language-processing’: 0.584025872986128, ‘other’: 0.17248570271336786}
将创建一个自定义预测函数,如果多数类不高于某个 softmax 分数,则预测other该类。在目标中,认为精度对来说非常重要,可以利用标签和 QA 工作流程来提高后续手动检查期间的召回率。
warning
模型可能会受到过度自信的影响,因此应用此限制可能不如想象的那么有效,尤其是对于更大的神经网络。有关更多信息,请参阅评估课程的自信学习部分。
# Determine first quantile softmax score for the correct class (on validation split)
y_pred = model.predict(X_val)
y_prob = model.predict_proba(X_val)
threshold = np.quantile([y_prob[i][j] for i, j in enumerate(y_pred)], q=0.25) # Q1
threshold
0.6742890218960005
warning
在验证拆分中执行此操作非常重要,因此不会在评估测试拆分之前使用训练拆分或泄漏信息来夸大值。
# Custom predict function
def custom_predict(y_prob, threshold, index):
"""Custom predict function that defaults
to an index if conditions are not met."""
y_pred = [np.argmax(p) if max(p) > threshold else index for p in y_prob]
return np.array(y_pred)
def predict_tag(texts):
y_prob = model.predict_proba(vectorizer.transform(texts))
other_index = label_encoder.class_to_index["other"]
y_pred = custom_predict(y_prob=y_prob, threshold=threshold, index=other_index)
return label_encoder.decode(y_pred)
# Inference (with tokens not similar to training data)
text = "Interpretability methods for explaining model behavior."
predict_tag(texts=[text])
[‘other’]
# Evaluate
y_prob = model.predict_proba(X_test)
y_pred = custom_predict(y_prob=y_prob, threshold=threshold, index=other_index)
metrics = precision_recall_fscore_support(y_test, y_pred, average="weighted")
performance = {"precision": metrics[0], "recall": metrics[1], "f1": metrics[2]}
print (json.dumps(performance, indent=2))
{ “precision”: 0.9116161616161617, “recall”: 0.7569444444444444, “f1”: 0.7929971988795519 }
Tip
甚至可以使用每个类别的阈值,特别是因为有一些数据不平衡,这会影响模型对某些类别的信心。
y_pred = model.predict(X_val) y_prob = model.predict_proba(X_val) class_thresholds = {} for index in range(len(label_encoder.classes)): class_thresholds[index] = np.mean( [y_prob[i][index] for i in np.where(y_pred==index)[0]])
这门 MLOps 课程实际上与模型无关(只要它产生概率分布),因此可以随意使用更复杂的表示(嵌入)和更复杂的架构(CNN、transformers等)。将在其余课程中使用这个基本的逻辑回归模型,因为它简单、快速并且实际上具有相当的性能(与最先进的预训练transformer相比,f1 差异<10%)。
更多干货,第一时间更新在以下微信公众号:

您的一点点支持,是我后续更多的创造和贡献

转载到请包括本文地址 更详细的转载事宜请参考文章如何转载/引用
本文主体源自以下链接:
@article{madewithml,
author = {Goku Mohandas},
title = { Made With ML },
howpublished = {\url{https://madewithml.com/}},
year = {2022}
}