设计机器学习产品
用于指导机器学习系统开发周期的模板,该模板考虑了产品要求、设计文档和项目注意事项。
概述
在本课程中,不仅会开发机器学习模型,还会讨论以可重现、可靠和稳健的方式将模型投入生产所需的所有重要 ML 系统和软件设计组件。将从为将要构建的精确产品设置场景开始。虽然这是一门技术课程,但最初的产品设计过程非常关键,是区分优秀产品与平庸产品的关键所在。本课将提供如何思考 ML + 产品的结构。
模板
该模板旨在指导机器学习产品开发。虽然此模板最初将按顺序完成,但它自然会涉及基于迭代反馈的非线性参与。对于产品的每个主要版本,都应该遵循此模板,以便所有决策制定都是透明的并记录在案。
产品(什么和为什么)→工程(如何)→项目(谁和什么时候)
虽然文档会很详细,但可以通过浏览机器学习画布来开始这个过程:
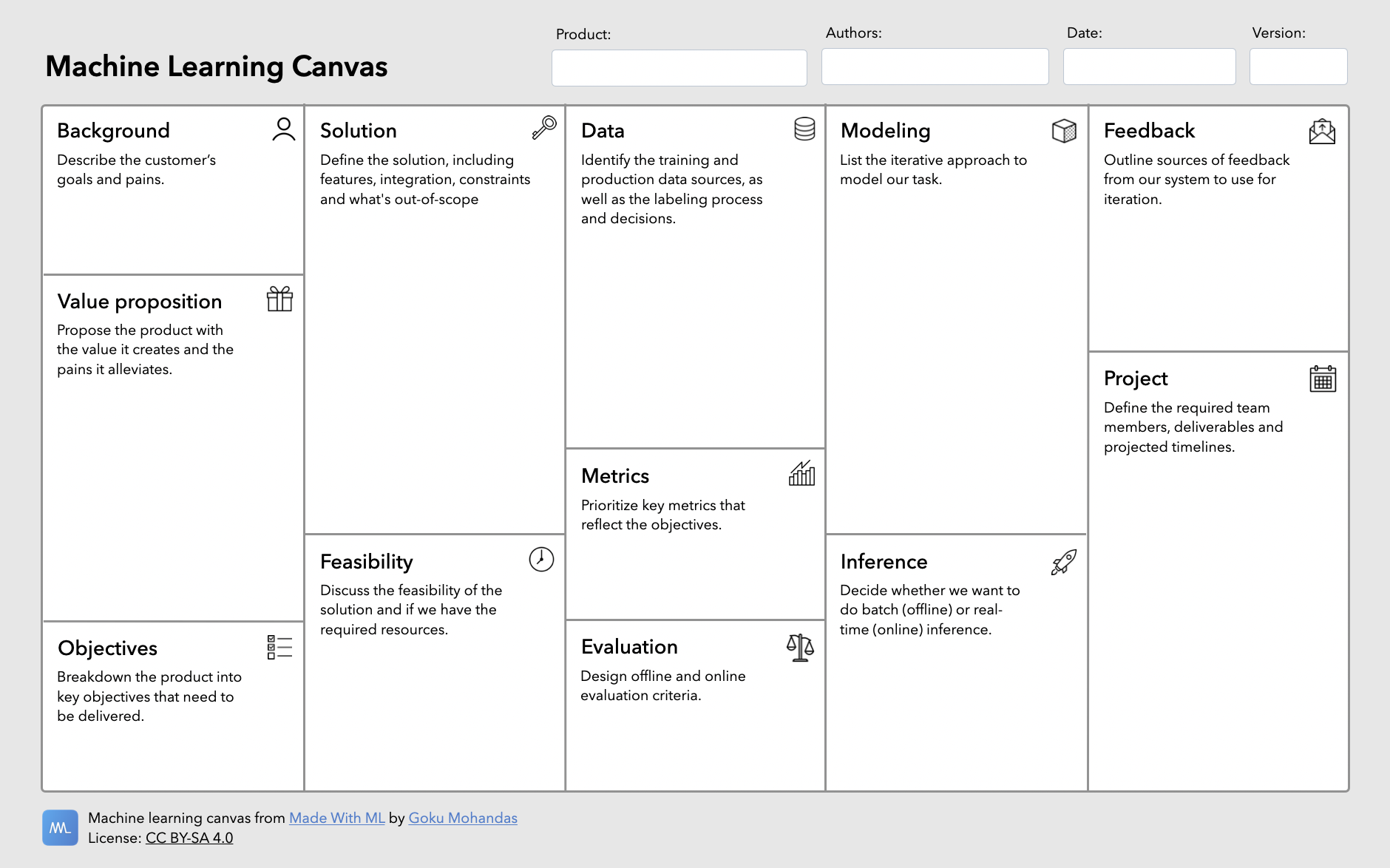
👉 下载 ML 画布的 PDF 以用于您自己的产品 → ml-canvas.pdf(右键单击链接并点击“链接另存为…”)
从这个高级画布,可以为每个版本创建详细的文档:
# Documentation
📂 project/
├── 📄 Overview
├── 📂 release-1
| ├── 📄 product requirements [Product]
| ├── 📄 design documentation [Engineering]
| ├── 📄 project planning [Project]
├── ...
└── 📂 release-n
在本课中,将陈述并证明为简化问题空间所做的假设。
产品管理
[ What & Why ]:激发对产品的需求并概述目标和关键结果。
note
下面的每个部分都有一个名为“任务”的下拉组件,它将讨论与正在尝试构建的特定产品相关的特定主题。
概述
背景
通过以客户为中心的方法为正在尝试做的事情设定场景:
customer:要解决的客户的个人资料goal: 客户的主要目标pains:客户实现目标的障碍gains:什么可以使客户的工作更轻松?
任务
customer:机器学习开发人员和研究人员。goal:及时了解工作、知识等方面的 ML 内容。pains: 互联网上散布着太多未分类的内容。gains:一个中央位置,其中包含来自受信任的第 3 方来源的分类内容。
价值主张
提出可以通过以产品为中心的方法创造的价值:
product:需要建立什么来帮助客户实现他们的目标?alleviates: 该产品将如何减轻痛点?advantages:产品将如何创造收益?
任务
product:从流行来源发现和分类 ML 内容的服务。alleviates:及时展示分类内容供客户发现。advantages:客户只需访问产品即可了解最新信息。
是的,在意识到它加剧了噪音和炒作之前,确实构建了它。因此,转向教导社区如何负责任地开发、部署和维护机器学习。
目标
将产品分解为想要关注的关键目标。
任务
- 允许客户添加和分类他们自己的项目。
- 从可信来源发现 ML 内容以引入平台。
- 对传入的内容(高精度)进行分类,以便客户轻松发现。[重点]
- 在平台上显示分类内容(最近、热门、推荐等)
解决方案
描述满足目标所需的解决方案,包括它的核心功能、集成、备选方案、约束以及超出范围的内容。
可能需要单独的文档(线框、用户故事、模型等)。
任务
开发一个可以对传入内容进行分类的模型,以便它可以在平台上按类别进行组织。
Core features:
- 将为传入内容预测正确类别的 ML 服务。[重点]
- 错误分类内容的用户反馈过程。
- 对服务不正确或不自信的内容进行分类的工作流程。
- 对平台上已有的内容进行重复筛选。
Integrations:
- 分类后的内容将发送到 UI 服务进行显示。
- 来自用户的分类反馈将发送到标签工作流程。
Alternatives:
- 允许用户手动添加内容(瓶颈)。
Constraints:
- 在对传入内容进行分类时保持低延迟(>100 毫秒)。[Latency]
- 只推荐批准的标签列表中的标签。[安全]
- 避免将重复内容添加到平台。[用户界面/用户体验]
Out-of-scope:
- 识别超出批准的标签列表的相关标签。
- 使用来自内容链接的全文 HTML 来帮助分类。
- 为什么推荐某些标签的可解释性。
- 识别多个类别(详见数据集部分)。
可行性
解决方案的可行性如何?是否拥有交付它所需的资源(数据、资金、团队等)?
任务
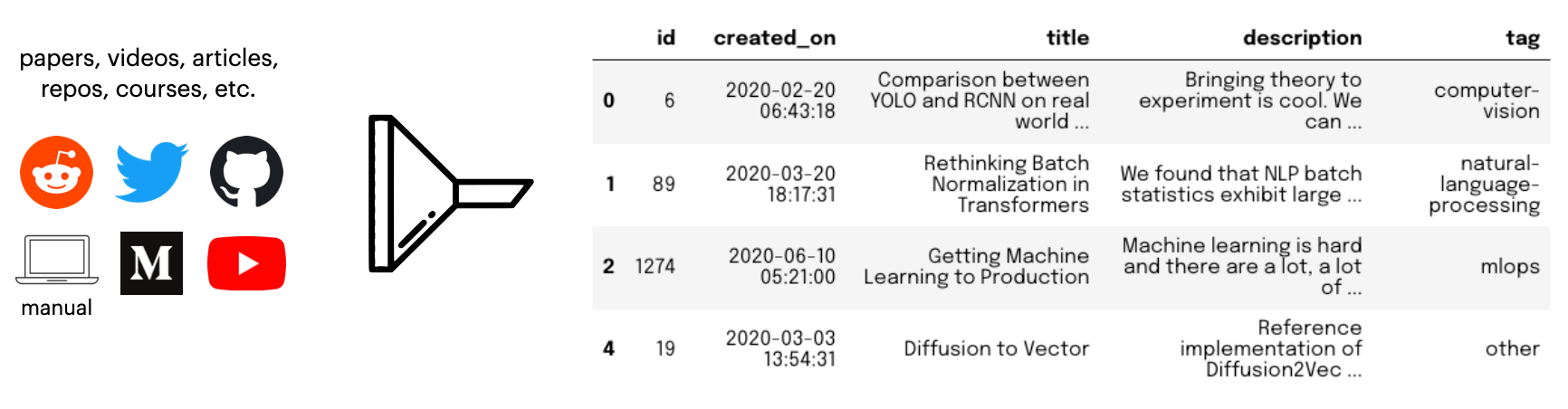
有一个 ML 内容数据集,用户已手动将其添加到平台。需要评估它是否有必要的信号来实现目标。
样本数据点
{
"id": 443,
"created_on": "2020-04-10 17:51:39",
"title": "AllenNLP Interpret",
"description": "A Framework for Explaining Predictions of NLP Models",
"tag": "natural-language-processing"
}
| 假设 | 现实 | 原因 |
|---|---|---|
| 该数据集质量很高,因为它们是由实际用户添加的。 | 需要评估标签的质量,尤其是因为它是由用户创建的! | 数据集质量很好,但在其中留下了一些错误,因此可以在评估过程中发现它们。 |
工程
[如何]:能否设计构建产品的方法。
数据
描述数据的训练和生产(批处理/流)来源。
任务
-
培训:
-
制作:
- 从分散的来源(Reddit、Twitter 等)及时访问批量的 ML 内容
- 怎么能相信这个流只有与历史上看到的一致的数据?
假设 现实 原因 ML 流只有 ML 相关的内容。 过滤以从这些第 3 方流中删除垃圾内容。 将需要获取相关数据并构建另一个模型。
标签
描述标记过程以及如何确定特征和标签。
任务
标签:使用机器学习类别(平台感兴趣的子集)进行标签。
特征:文本特征(标题和描述)为分类任务提供信号。
标签:反映目前在平台上展示的内容类别:
['natural-language-processing',
'computer-vision',
'mlops',
...
'other']
| 假设 | 现实 | 原因 |
|---|---|---|
| 内容只能属于一个类别(多类)。 | 内容可以属于多个类别(多标签)。 | 为简单起见,许多图书馆不支持或复杂化多标签场景。 |
评估
在可以为目标建模之前,需要能够评估表现。
指标
评估中最困难的挑战之一是将核心目标(可能是定性的)与模型可以优化的定量指标联系起来。
任务
希望能够以高精度对传入数据进行分类,以便可以正确显示它们。对于归类为的项目other,可以使用手动标记工作流_召回任何错误分类的内容。可能还想评估特定类别或数据片段的性能。
优先事项是什么
如何决定优先考虑哪些指标?
显示答案
这完全取决于具体任务。例如,在电子邮件垃圾邮件检测器中,精度非常重要,因为它比看到一些垃圾邮件然后完全错过一封重要的电子邮件要好。随着时间的推移,需要迭代解决方案,以便改进所有评估指标,但重要的是要知道不能从一开始就包含哪些指标。
离线评估
离线评估需要一个黄金标准标记的数据集,可以使用它来对所有的建模进行基准测试。
任务
将使用历史数据集进行离线评估。还将创建要单独评估的数据切片。
在线测评
在线评估确保模型在生产中继续表现良好,并且可以使用标签或在没有标签的情况下使用代理信号来执行。
任务
- 手动标记传入数据的子集以定期评估。
- 询问查看新分类内容的初始用户集是否正确分类。
- 允许用户报告模型错误分类的内容。
在承诺替换现有的系统版本之前,衡量实时性能非常重要。
- 内部canary发布、代理/实际性能监控等。
- 推广到更大的内部团队以获得更多反馈。
- A/B 推广到人口的一个子集,以更好地理解用户体验、效用等。
并非所有版本都必须是高风险和面向外部的。始终可以包括内部版本、收集反馈和迭代,直到准备好扩大范围。
Modeling
虽然采用的具体方法可能因问题而异,但始终希望遵循以下核心原则:
- 端到端效用:每次迭代的最终结果应该提供最小的端到端效用,这样就可以对彼此的迭代进行基准测试,并与系统即插即用。
- ML 之前的手动操作:在定义规则之前合并确定性组件,然后使用从数据→基线推断规则的概率组件。
- 增强与自动化:允许系统补充决策过程,而不是做出最终决定。
- 内部与外部:并非所有早期版本都必须面向最终用户。可以使用早期版本进行内部验证、反馈、数据收集等。
- 彻底:每种方法都需要经过良好的测试(代码、数据+模型)和评估,因此可以客观地对不同的方法进行基准测试。
任务
- v1:创建代表问题空间的黄金标准标记数据集。
- v2:基于规则的文本匹配方法对内容进行分类。
- v3:从内容标题和描述中概率预测标签。
- v4: …
解耦 POC 和实现
这些方法中的每一种都将涉及概念验证 (POC) 发布和在验证其相对于先前方法的实用性之后的实施发布。应该将 POC 和实施分离,因为如果 POC 没有证明是成功的,那么就无法实施,所有相关的计划也不再适用。
开始简单的实用程序
一些较早的、更简单的方法可能无法实现特定的性能目标。仍然从简单开始有哪些优点?
显示答案
- 获得有关端到端实用程序的内部反馈。
- 执行 A/B 测试以了解 UI/UX 设计。
- 在本地部署以开始生成更复杂方法所需的更多数据。
反馈
如何接收对系统的反馈并将其纳入下一次迭代?这可能涉及人在环路反馈以及通过监控等自动反馈。
任务
- 当对分类的信心较低时,强制执行人工循环检查。
- 允许用户报告与错误分类相关的问题。
始终回归价值主张
虽然迭代和优化工作流程的内部结构很重要,但确保 ML 系统真正产生影响更为重要。需要不断地与利益相关者(管理层、用户)互动,以反复思考 ML 系统存在的原因。

项目管理
[谁和什么时候]:将所有产品需求组织到可管理的时间表中,以便能够实现愿景。
团队
哪些团队和这些团队的特定成员需要参与该项目?重要的是要考虑即使是次要功能,这样每个人都知道它,这样就可以适当地确定时间表的范围和优先级。请记住,这不是人们可能从事的唯一项目。
任务
- 产品:负责概述产品需求并批准它们的成员可能包括产品经理、高管、外部利益相关者等。
- 系统设计:
- 数据工程:负责数据依赖性,其中包括稳健的工作流,以持续交付数据并确保数据经过适当验证并为下游应用程序做好准备。
- 机器学习:开发具有适当评估的概率系统。
- DevOps:部署应用程序并帮助根据流量自动缩放。
- UI/UX:使用系统的输出来为用户提供新的体验。
- 辅助功能:帮助对社区进行新推出的辅助,并协助围绕敏感问题做出决策。
- 站点可靠性:维护应用程序并可能监督在线评估/监控工作流程是否正常工作。
- 项目:负责与产品和工程团队反复接触以确保构建正确的产品并且构建得当的成员可能包括项目经理、工程经理等。
可交付成果
需要将特定发布的所有目标分解为明确的可交付成果,这些可交付成果指定可交付成果、贡献者、依赖项、验收标准和状态。这将成为团队用来决定优先事项的详细清单。
任务
时间线
这是项目范围界定开始的地方。通常,利益相关者会有期望的发布时间和要交付的功能。根据可行性研究的结果,在这方面会有很多来回,因此设置期望时彻底和透明是非常重要的。
任务
v1:对传入的内容(高精度)进行分类,以便客户轻松发现。
- XX进行的勘探研究
- 由 XX 推送给开发人员进行 A/B 测试
- 被 XX 推送到登机hook
- 由 XX 推送到产品
这是一个极其简化的时间表。实际的时间线将描述来自所有不同团队的时间线,这些时间线在指定的时间限制或版本发布时用垂直线堆叠在一起。
更多干货,第一时间更新在以下微信公众号:

您的一点点支持,是我后续更多的创造和贡献

转载到请包括本文地址 更详细的转载事宜请参考文章如何转载/引用
本文主体源自以下链接:
@article{madewithml,
author = {Goku Mohandas},
title = { Made With ML },
howpublished = {\url{https://madewithml.com/}},
year = {2022}
}