了解如何监控 ML 系统以识别和解决漂移源,以防止模型性能下降。
intution
尽管已经训练并彻底评估了模型,但一旦部署到生产环境,真正的工作就开始了。这是传统软件工程与 ML 开发之间的根本区别之一。传统上,使用基于规则的确定性软件,大部分工作发生在初始阶段,一旦部署,系统就会按照定义的方式工作。但是对于机器学习,并没有明确定义事物的工作原理,而是使用数据来构建概率解决方案。这种方法会随着时间的推移而出现自然的性能下降以及意外行为,因为暴露给模型的数据将与训练过的数据不同。这不是应该试图避免的事情,而是尽可能地理解和减轻。在本课中,’漂移检测。
系统运行状况
确保模型运行良好的第一步是确保实际系统正常运行。这可以包括特定于服务请求的指标,例如延迟、吞吐量、错误率等,以及基础设施利用率,例如 CPU/GPU 利用率、内存等。
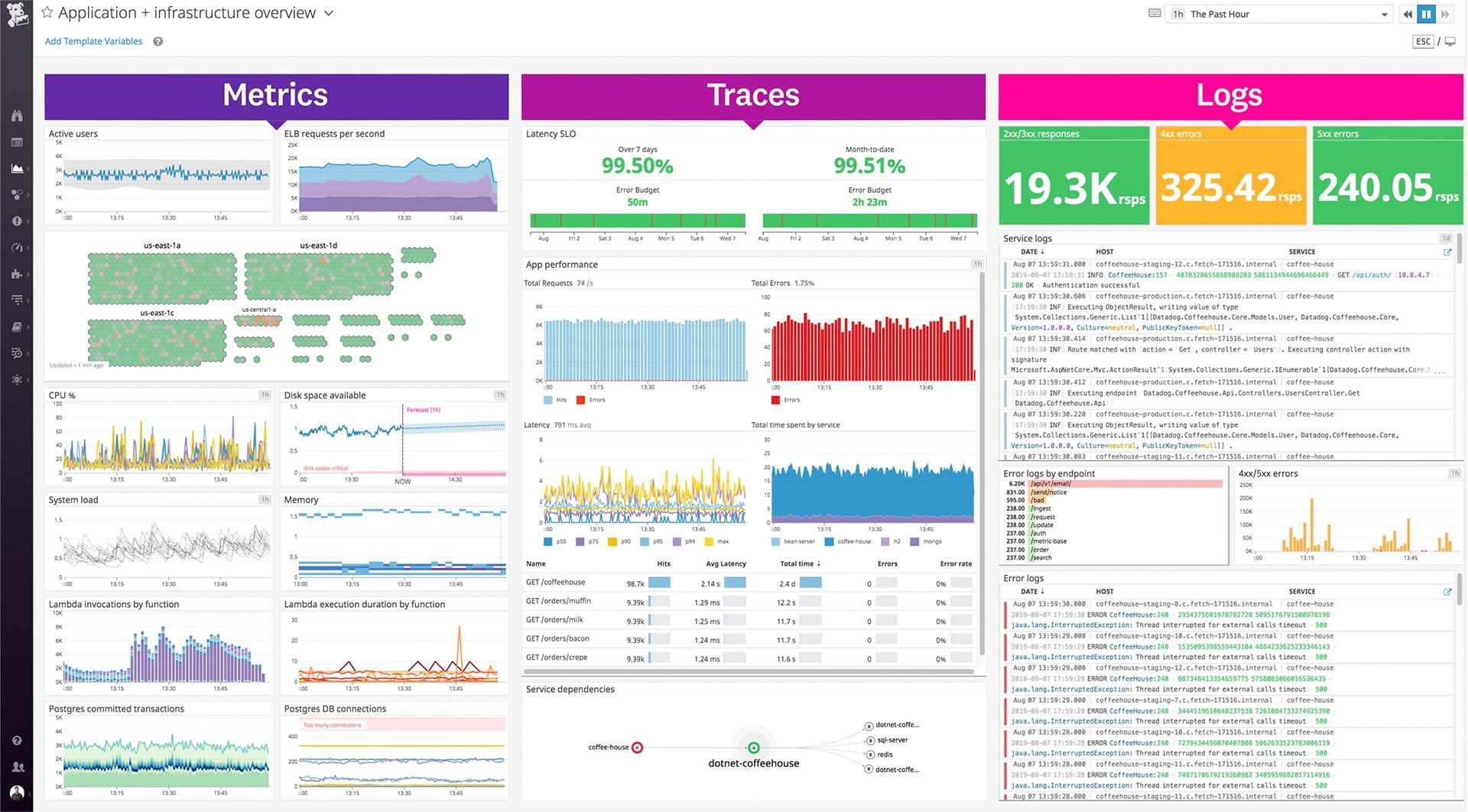
幸运的是,大多数云提供商甚至编排层都将通过仪表板免费提供对系统健康状况的洞察。如果不这样做,可以轻松地使用Grafana、Datadog等从日志中提取系统性能指标,以创建自定义仪表板并设置警报。
表现
不幸的是,仅仅监控系统的健康状况并不足以捕捉模型的潜在问题。因此,很自然地,要监控的下一层指标涉及模型的性能。这些可以是在模型评估期间使用的定量评估指标(准确度、精度、f1 等),也可以是模型影响的关键业务指标(ROI、点击率等)。
自部署模型以来,仅分析整个时间跨度内的累积性能指标通常是不够的。相反,还应该检查对应用程序很重要的一段时间内的性能(例如每天)。这些滑动指标可能更能反映系统的健康状况,并且可能能够通过不使用历史数据掩盖问题来更快地识别问题
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
sns.set_theme()
# Generate data
hourly_f1 = list(np.random.randint(low=94, high=98, size=24*20)) + \
list(np.random.randint(low=92, high=96, size=24*5)) + \
list(np.random.randint(low=88, high=96, size=24*5)) + \
list(np.random.randint(low=86, high=92, size=24*5))
# Cumulative f1
cumulative_f1 = [np.mean(hourly_f1[:n]) for n in range(1, len(hourly_f1)+1)]
print (f"Average cumulative f1 on the last day: {np.mean(cumulative_f1[-24:]):.1f}")
# Sliding f1
window_size = 24
sliding_f1 = np.convolve(hourly_f1, np.ones(window_size)/window_size, mode="valid")
print (f"Average sliding f1 on the last day: {np.mean(sliding_f1[-24:]):.1f}")
plt.ylim([80, 100])
plt.hlines(y=90, xmin=0, xmax=len(hourly_f1), colors="blue", linestyles="dashed", label="threshold")
plt.plot(cumulative_f1, label="cumulative")
plt.plot(sliding_f1, label="sliding")
plt.legend()
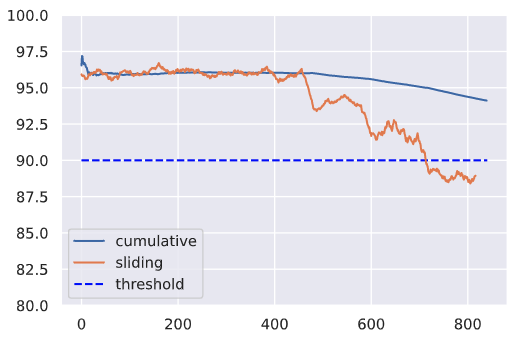
可能需要监控各种窗口大小的指标,以尽快发现性能下降。在这里,监控的是整体 f1,但可以对数据切片、单个类等执行相同的操作。例如,如果监控特定标签的性能,可能能够快速捕捉为发布的新算法该标签(例如新的transformer架构)。
延迟的结果
可能并不总是有可用的真实结果来确定模型在生产投入上的表现。如果实际数据存在明显滞后或需要注释,则尤其如此。为了缓解这种情况,可以:
- 设计一个可以帮助估计模型性能的近似信号。例如,在标签预测任务中,可以使用作者赋予项目的实际标签作为中间标签,直到验证了来自注释管道的标签。
- 标记实时数据集的一小部分以估计性能。该子集应尽量代表实时数据中的各种分布。
重要性加权
然而,近似信号并不总是适用于每种情况,因为 ML 系统的输出没有反馈,或者它太延迟了。对于这些情况,最近的一项研究依赖于在所有情况下都可用的唯一组件:输入数据。
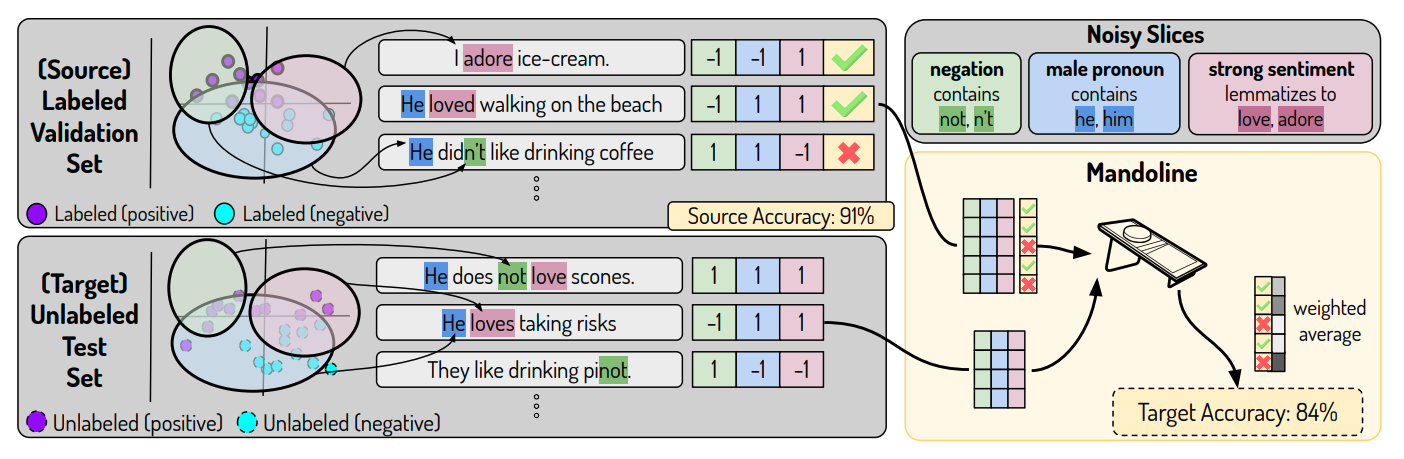
核心思想是开发切片功能,可能会捕捉数据可能经历分布变化的方式。这些切片功能应捕获明显的切片,例如类标签或不同的分类特征值,但也应捕获基于隐式元数据(不是显式特征列的数据的隐藏方面)的切片。然后将这些切片函数应用于标记数据集,以创建具有相应标签的矩阵。相同的切片函数应用于未标记的生产数据,以近似加权标签的内容。有了这个,可以确定大概的性能!这里的直觉是,可以根据标记切片矩阵和未标记切片矩阵之间的相似性更好地近似未标记数据集的性能。
如果等待基于性能来捕捉模型衰减,它可能已经对依赖它的下游业务管道造成了重大损害。需要在实际性能下降之前采用更细粒度的监控来识别模型漂移的来源。
漂移
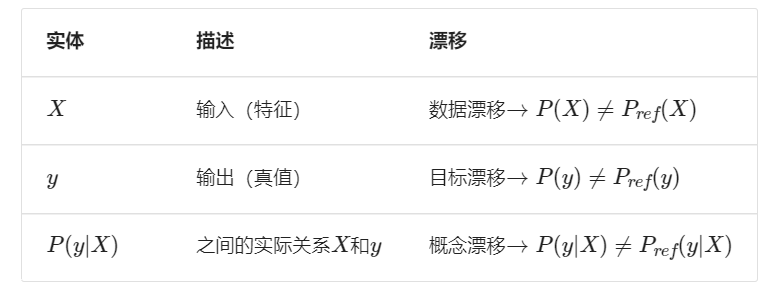
需要首先了解可能导致模型性能下降(模型漂移)的不同类型的问题。做到这一点的最好方法是查看正在尝试建模的所有移动部分以及每个部分如何体验漂移。
数据漂移
当生产数据的分布与训练数据的分布不同时,就会发生数据漂移,也称为特征漂移或协变量偏移。该模型无法处理特征空间中的这种漂移,因此它的预测可能不可靠。漂移的实际原因可归因于现实世界中的自然变化,也可归因于系统性问题,例如丢失数据、管道错误、架构更改等。检查漂移的数据并沿着其管道追溯以识别引入漂移的时间和地点。
除了只查看输入数据的分布,还希望确保在训练和服务期间检索和处理输入数据的工作流程是相同的,以避免训练-服务偏差。但是,如果从相同的源位置检索特征用于训练和服务,可以跳过这一步,即。从功能商店。
随着数据开始漂移,可能还没有注意到模型性能的显着下降,特别是如果模型能够很好地插值。然而,这是一个很好的机会,可以在漂移开始影响性能之前进行重新训练。
目标漂移
除了输入数据发生变化外,与数据漂移一样,还可以体验结果的漂移。这可能是分布的变化,也可能是具有分类任务的新类的删除或添加。尽管再训练可以减轻导致目标漂移的性能衰减,但通常可以通过有关新类、模式更改等的适当管道间通信来避免这种情况。
概念漂移
除了输入和输出数据漂移之外,还可以得到它们之间的实际关系漂移。这种概念漂移使模型无效,因为它学会在原始输入和输出之间映射的模式不再相关。概念漂移可能以各种模式发生:
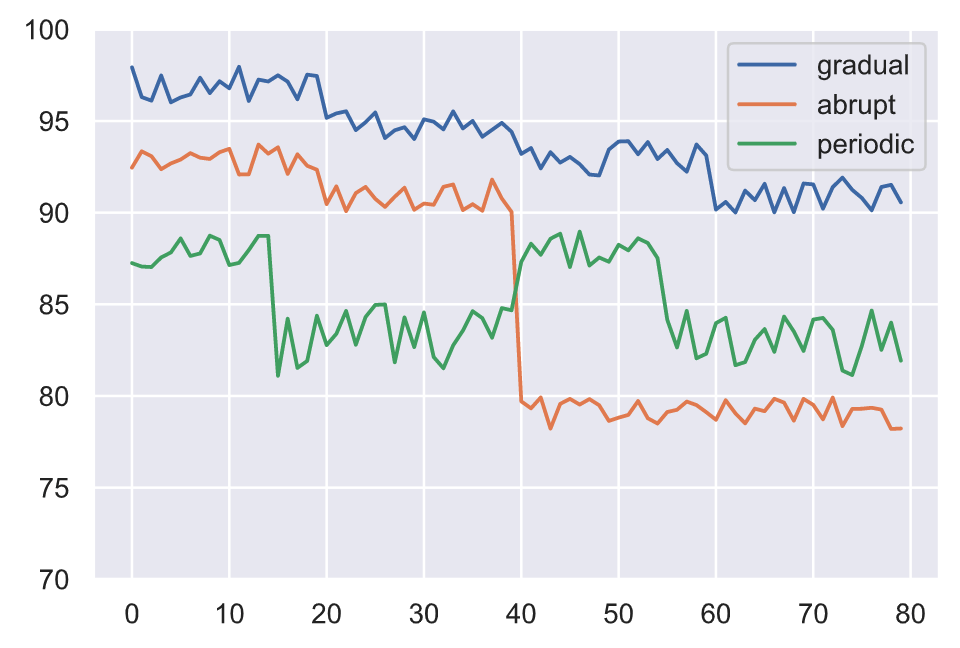
- 在一段时间内逐渐
- 由于外部事件而突然
- 由于反复发生的事件而定期
讨论的所有不同类型的漂移都可以同时发生,这会使识别漂移的来源变得复杂。
定位漂移
现在已经确定了不同类型的漂移,需要学习如何定位以及测量它的频率。以下是需要考虑的约束:
- 参考窗口:用于比较生产数据分布以识别漂移的一组点。
- 测试窗口:与参考窗口比较以确定是否发生漂移的点集。
由于正在处理在线漂移检测(即检测实时生产数据中的漂移,而不是过去的批次数据),可以采用固定或滑动窗口方法来识别点集进行比较。通常,参考窗口是训练数据的一个固定的、最近的子集,而测试窗口会随着时间的推移而滑动。
Scikit-multiflow提供了一个工具包,用于直接在流数据上进行概念漂移检测技术。该软件包提供了窗口化、移动平均功能(包括动态预处理),甚至还提供了一些围绕概念的方法,例如逐渐概念漂移。
还可以同时比较各种窗口大小,以确保较小的漂移情况不会被大窗口大小平均。
测量漂移
一旦有了想要比较的点的窗口,就需要知道如何比较它们。
import great_expectations as ge
import json
import pandas as pd
from urllib.request import urlopen
# Load labeled projects
projects = pd.read_csv("https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv")
tags = pd.read_csv("https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv")
df = ge.dataset.PandasDataset(pd.merge(projects, tags, on="id"))
df["text"] = df.title + " " + df.description
df.drop(["title", "description"], axis=1, inplace=True)
df.head(5)
期望
第一种测量形式可以是基于规则的,例如验证对缺失值、数据类型、值范围等的期望,就像在数据测试课中所做的那样。现在的不同之处在于,将根据实时生产数据验证这些期望。
# Simulated production data
prod_df = ge.dataset.PandasDataset([{"text": "hello"}, {"text": 0}, {"text": "world"}])
# Expectation suite
df.expect_column_values_to_not_be_null(column="text")
df.expect_column_values_to_be_of_type(column="text", type_="str")
expectation_suite = df.get_expectation_suite()
# Validate reference data
df.validate(expectation_suite=expectation_suite, only_return_failures=True)["statistics"]
{‘evaluated_expectations’: 2, ‘success_percent’: 100.0, ‘successful_expectations’: 2, ‘unsuccessful_expectations’: 0}
# Validate production data
prod_df.validate(expectation_suite=expectation_suite, only_return_failures=True)["statistics"]
{‘evaluated_expectations’: 2, ‘success_percent’: 50.0, ‘successful_expectations’: 1, ‘unsuccessful_expectations’: 1}
单变量
任务可能涉及想要监控的单变量(1D)特征。虽然可以使用多种类型的假设检验,但一种流行的选择是Kolmogorov-Smirnov (KS) 检验。
Kolmogorov-Smirnov (KS) 测试
KS 检验确定两个分布的累积密度函数之间的最大距离。在这里,将测量两个不同数据子集之间输入文本特征的大小是否存在任何偏差。
TIPS
虽然文本是任务中的直接特征,但还可以监控其他隐含特征,例如文本中未知标记的百分比(需要维护训练词汇表)等。虽然它们可能不会用于机器学习模型,但它们可以是检测漂移的重要指标。
from alibi_detect.cd import KSDrift
# Reference
df["num_tokens"] = df.text.apply(lambda x: len(x.split(" ")))
ref = df["num_tokens"][0:200].to_numpy()
plt.hist(ref, alpha=0.75, label="reference")
plt.legend()
plt.show()
# Initialize drift detector
length_drift_detector = KSDrift(ref, p_val=0.01)
# No drift
no_drift = df["num_tokens"][200:400].to_numpy()
plt.hist(ref, alpha=0.75, label="reference")
plt.hist(no_drift, alpha=0.5, label="test")
plt.legend()
plt.show()
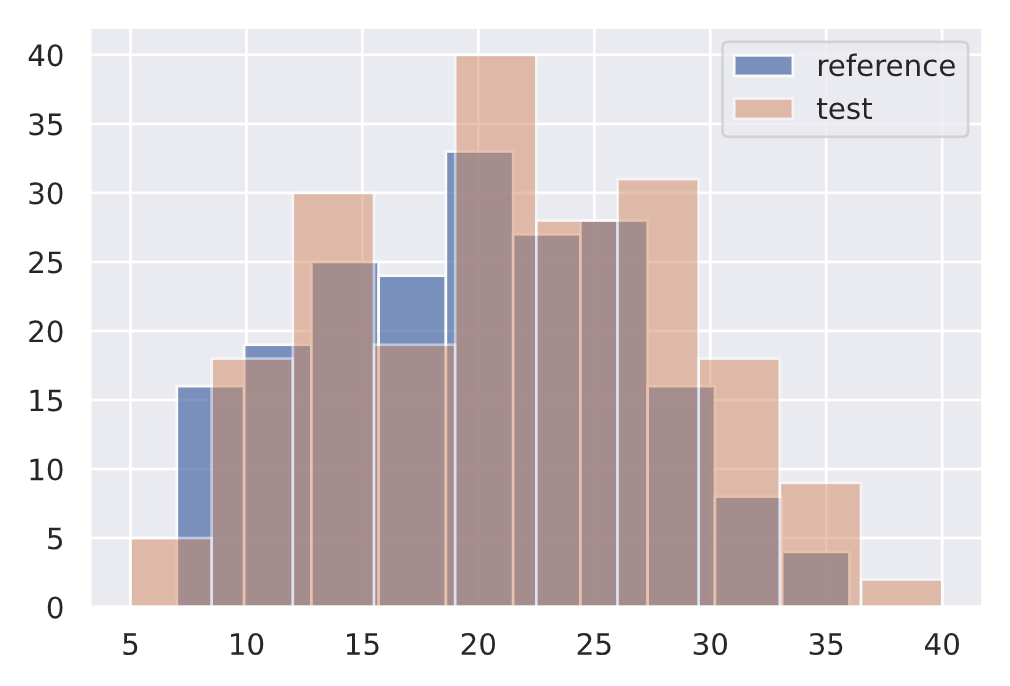
length_drift_detector.predict(no_drift, return_p_val=True, return_distance=True)
{‘data’: {‘distance’: array([0.09], dtype=float32), ‘is_drift’: 0, ‘p_val’: array([0.3927307], dtype=float32), ‘threshold’: 0.01}, ‘meta’: {‘data_type’: None, ‘detector_type’: ‘offline’, ‘name’: ‘KSDrift’, ‘version’: ‘0.9.1’}}
↓ p 值 = ↑ 确信分布不同。
# Drift
drift = np.random.normal(30, 5, len(ref))
plt.hist(ref, alpha=0.75, label="reference")
plt.hist(drift, alpha=0.5, label="test")
plt.legend()
plt.show()
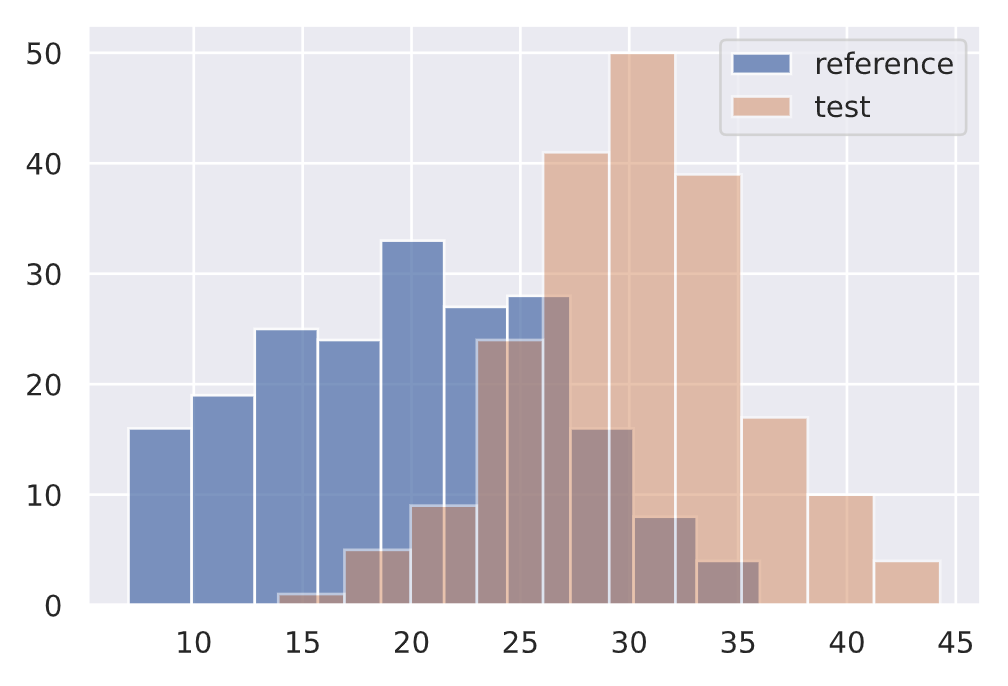
length_drift_detector.predict(drift, return_p_val=True, return_distance=True)
{'data': {'distance': array([0.63], dtype=float32),
'is_drift': 1,
'p_val': array([6.7101775e-35], dtype=float32),
'threshold': 0.01},
'meta': {'data_type': None,
'detector_type': 'offline',
'name': 'KSDrift',
'version': '0.9.1'}}
卡方检验
同样,对于分类数据(输入特征、目标等),可以应用Pearson 卡方检验来确定生产中的事件频率是否与参考分布一致。
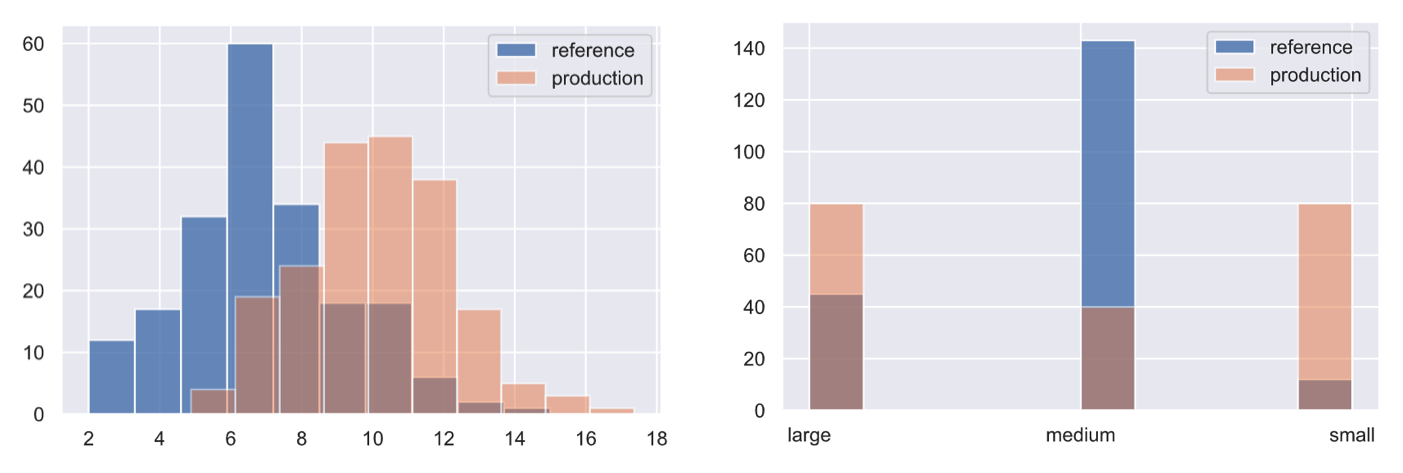
正在为文本特征中的标记数创建一个分类变量,但可以非常非常地将其应用于标签分布本身、单个标签(二进制)、标签切片等。
from alibi_detect.cd import ChiSquareDrift
# Reference
df.token_count = df.num_tokens.apply(lambda x: "small" if x <= 10 else ("medium" if x <=25 else "large"))
ref = df.token_count[0:200].to_numpy()
plt.hist(ref, alpha=0.75, label="reference")
plt.legend()
# Initialize drift detector
target_drift_detector = ChiSquareDrift(ref, p_val=0.01)
# No drift
no_drift = df.token_count[200:400].to_numpy()
plt.hist(ref, alpha=0.75, label="reference")
plt.hist(no_drift, alpha=0.5, label="test")
plt.legend()
plt.show()
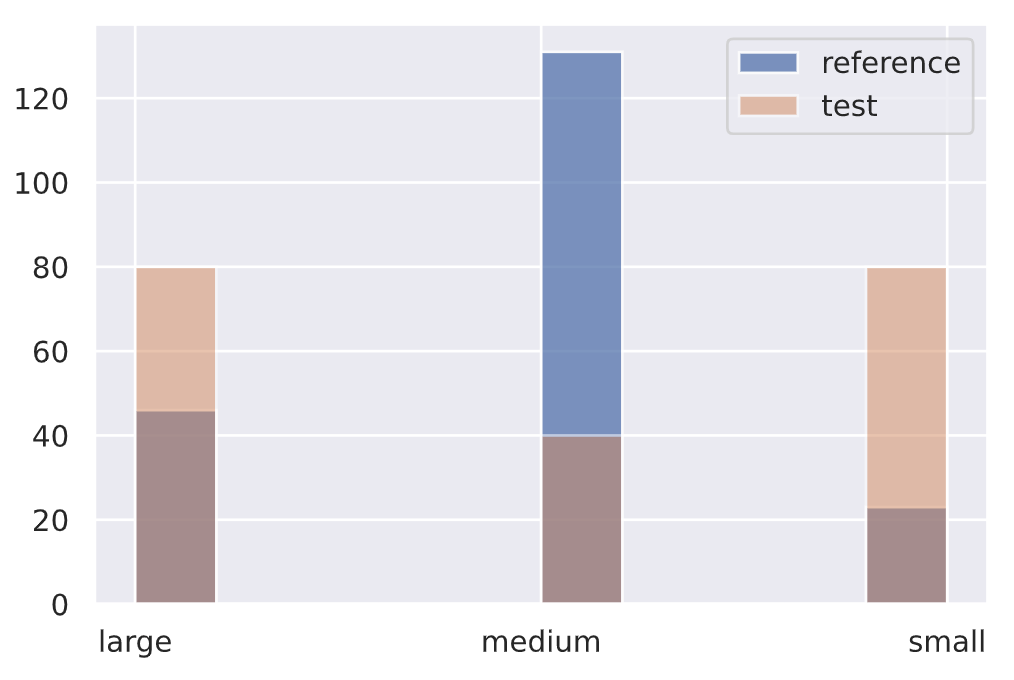
target_drift_detector.predict(no_drift, return_p_val=True, return_distance=True)
{‘data’: {‘distance’: array([4.135522], dtype=float32), ‘is_drift’: 0, ‘p_val’: array([0.12646863], dtype=float32), ‘threshold’: 0.01}, ‘meta’: {‘data_type’: None, ‘detector_type’: ‘offline’, ‘name’: ‘ChiSquareDrift’, ‘version’: ‘0.9.1’}}
# Drift
drift = np.array(["small"]*80 + ["medium"]*40 + ["large"]*80)
plt.hist(ref, alpha=0.75, label="reference")
plt.hist(drift, alpha=0.5, label="test")
plt.legend()
plt.show()
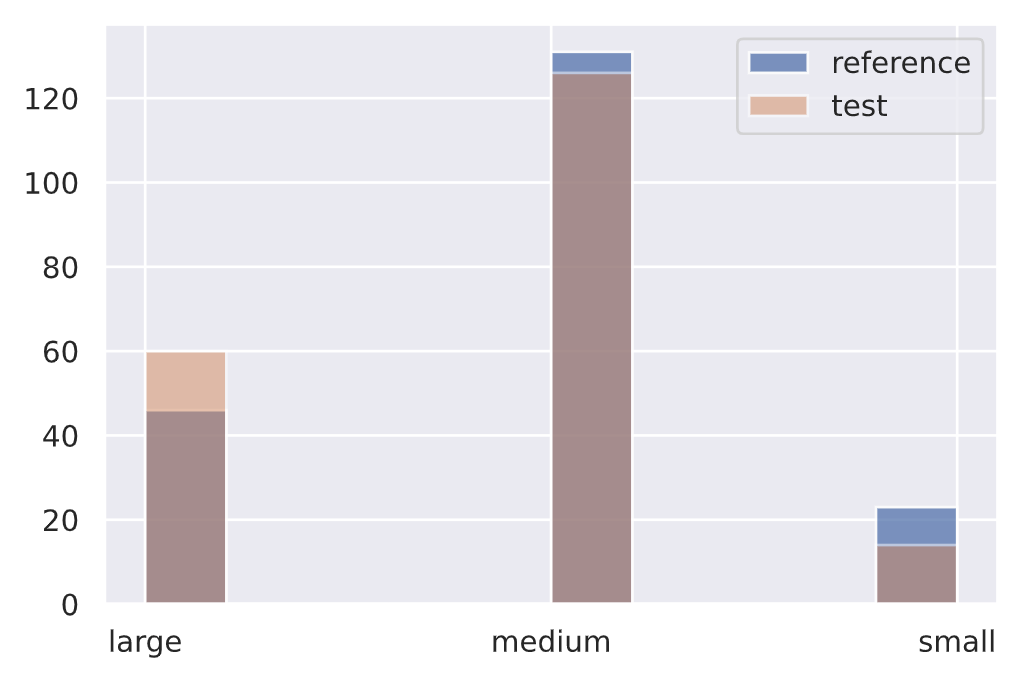
target_drift_detector.predict(drift, return_p_val=True, return_distance=True)
{‘data’: {‘is_drift’: 1, ‘distance’: array([118.03355], dtype=float32), ‘p_val’: array([2.3406739e-26], dtype=float32), ‘threshold’: 0.01}, ‘meta’: {‘name’: ‘ChiSquareDrift’, ‘detector_type’: ‘offline’, ‘data_type’: None}}
多变量
正如所看到的,测量漂移对于单变量数据相当简单,但对于多变量数据却很困难。将总结以下论文中概述的减少和测量方法:Failing Loudly: An Empirical Study of Methods for Detecting Dataset Shift。

使用 tf-idf 对文本进行矢量化(以保持建模简单),它具有高维度并且在上下文中语义不丰富。但是,通常对于文本,使用单词/字符嵌入。因此,为了说明多变量数据上的漂移检测会是什么样子,让使用预训练嵌入来表示文本。
请务必参考embedding和transformer器课程,以了解有关这些主题的更多信息。但请注意,检测多变量文本嵌入的漂移仍然非常困难,因此通常更常见的是使用应用于表格特征或图像的这些方法。
将从预训练模型加载分词器开始。
from transformers import AutoTokenizer
model_name = "allenai/scibert_scivocab_uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
vocab_size = len(tokenizer)
print (vocab_size)
31090
# Tokenize inputs
encoded_input = tokenizer(df.text.tolist(), return_tensors="pt", padding=True)
ids = encoded_input["input_ids"]
masks = encoded_input["attention_mask"]
# Decode
print (f"{ids[0]}\n{tokenizer.decode(ids[0])}")
tensor([ 102, 2029, 467, 1778, 609, 137, 6446, 4857, 191, 1332, 2399、13572、19125、1983、147、1954、165、6240、205、185、 300、3717、7434、1262、121、537、201、137、1040、111、 545、121、4714、205、103、0、0、0、0、0、 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]) [CLS] comparison between yolo and rcnn on real world videos bringing theory to experiment is cool. we can easily train models in colab and find the results in minutes. [SEP] [PAD] [PAD] …
# Sub-word tokens
print (tokenizer.convert_ids_to_tokens(ids=ids[0]))
[‘[CLS]’, ‘comparison’, ‘between’, ‘yo’, ‘##lo’, ‘and’, ‘rc’, ‘##nn’, ‘on’, ‘real’, ‘world’, ‘videos’, ‘bringing’, ‘theory’, ‘to’, ‘experiment’, ‘is’, ‘cool’, ‘.’, ‘we’, ‘can’, ‘easily’, ‘train’, ‘models’, ‘in’, ‘col’, ‘##ab’, ‘and’, ‘find’, ‘the’, ‘results’, ‘in’, ‘minutes’, ‘.’, ‘[SEP]’, ‘[PAD]’, ‘[PAD]’, …]
接下来,将加载预训练模型的权重,并使用该TransformerEmbedding对象从隐藏状态中提取嵌入(跨令牌平均)。
from alibi_detect.models.pytorch import TransformerEmbedding
# Embedding layer
emb_type = "hidden_state"
layers = [-x for x in range(1, 9)] # last 8 layers
embedding_layer = TransformerEmbedding(model_name, emb_type, layers)
# Embedding dimension
embedding_dim = embedding_layer.model.embeddings.word_embeddings.embedding_dim
embedding_dim
768
降维
现在需要使用降维方法来将表示维度减少到更易于管理的东西(例如 32 暗淡),这样就可以运行两个样本测试来检测漂移。热门选项包括:
- 主成分分析(PCA):保持数据集可变性的正交变换。
- 自动编码器(AE):消耗输入并尝试从较低维空间重建它同时最小化错误的网络。这些可以是经过训练的,也可以是未经训练的(大声失败的论文建议未经训练)。
- 黑盒移位检测器(BBSD):在训练数据上训练的实际模型可以用作降维器。可以使用 softmax 输出(多变量)或实际预测(单变量)。
import torch
import torch.nn as nn
# Device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# Untrained autoencoder (UAE) reducer
encoder_dim = 32
reducer = nn.Sequential(
embedding_layer,
nn.Linear(embedding_dim, 256),
nn.ReLU(),
nn.Linear(256, encoder_dim)
).to(device).eval()
可以将上述所有操作包装到一个预处理函数中,该函数将使用输入文本并生成简化表示。
from alibi_detect.cd.pytorch import preprocess_drift
from functools import partial
# Preprocessing with the reducer
max_len = 100
batch_size = 32
preprocess_fn = partial(preprocess_drift, model=reducer, tokenizer=tokenizer,
max_len=max_len, batch_size=batch_size, device=device)
最大平均差异 (MMD)
在对多元数据应用降维技术后,可以使用不同的统计测试来计算漂移。一个流行的选项是最大平均差异 (MMD),这是一种基于内核的方法,它通过计算两个分布的特征的平均嵌入之间的距离来确定两个分布之间的距离。
from alibi_detect.cd import MMDDrift
# Initialize drift detector
mmd_drift_detector = MMDDrift(ref, backend="pytorch", p_val=.01, preprocess_fn=preprocess_fn)# No drift
no_drift = df.text[200:400].to_list()
mmd_drift_detector.predict(no_drift)
{‘data’: {‘distance’: 0.0021169185638427734, ‘distance_threshold’: 0.0032651424, ‘is_drift’: 0, ‘p_val’: 0.05999999865889549, ‘threshold’: 0.01}, ‘meta’: {‘backend’: ‘pytorch’, ‘data_type’: None, ‘detector_type’: ‘offline’, ‘name’: ‘MMDDriftTorch’, ‘version’: ‘0.9.1’}}
# Drift
drift = ["UNK " + text for text in no_drift]
mmd_drift_detector.predict(drift)
在线的
到目前为止,已经将漂移检测方法应用于离线数据,以尝试了解参考窗口大小应该是什么,p 值是合适的等。但是,需要在在线生产设置中应用这些方法,以便可以尽可能容易地捕捉漂移。
许多监控库和平台都为其检测方法提供了在线等效项。
通常,参考窗口很大,因此有一个适当的基准来比较生产数据点。至于测试窗口,它越小,就能越快捕捉到突然的漂移。然而,更大的测试窗口将使能够识别更微妙/渐进的漂移。所以最好组合不同大小的窗口来定期监控。
from alibi_detect.cd import MMDDriftOnline
# Online MMD drift detector
ref = df.text[0:800].to_list()
online_mmd_drift_detector = MMDDriftOnline(
ref, ert=400, window_size=200, backend="pytorch", preprocess_fn=preprocess_fn)
Generating permutations of kernel matrix.. 100%|██████████| 1000/1000 [00:00<00:00, 13784.22it/s] Computing thresholds: 100%|██████████| 200/200 [00:32<00:00, 6.11it/s]
随着数据开始流入,可以使用检测器来预测每个点的漂移。检测器应该比正常数据更快地检测到漂移数据集中的漂移。
def simulate_production(test_window):
i = 0
online_mmd_drift_detector.reset()
for text in test_window:
result = online_mmd_drift_detector.predict(text)
is_drift = result["data"]["is_drift"]
if is_drift:
break
else:
i += 1
print (f"{i} steps")
# Normal
test_window = df.text[800:]
simulate_production(test_window)
27 steps
# Drift
test_window = "UNK" * len(df.text[800:])
simulate_production(test_window)
11 steps
关于刷新参考和测试窗口的频率还有几个考虑因素。可以基于新观察的数量或没有漂移的时间等。还可以根据通过监控了解的系统来调整各种阈值(ERT、窗口大小等)。
异常值
通过漂移,将生产数据窗口与参考数据进行比较,而不是查看任何一个特定数据点。虽然每个单独的点可能不是异常或异常值,但点组可能会导致漂移。说明这一点的最简单方法是想象重复为实时模型提供相同的输入数据点。实际数据点可能没有异常特征,但反复喂它会导致特征分布发生变化并导致漂移。
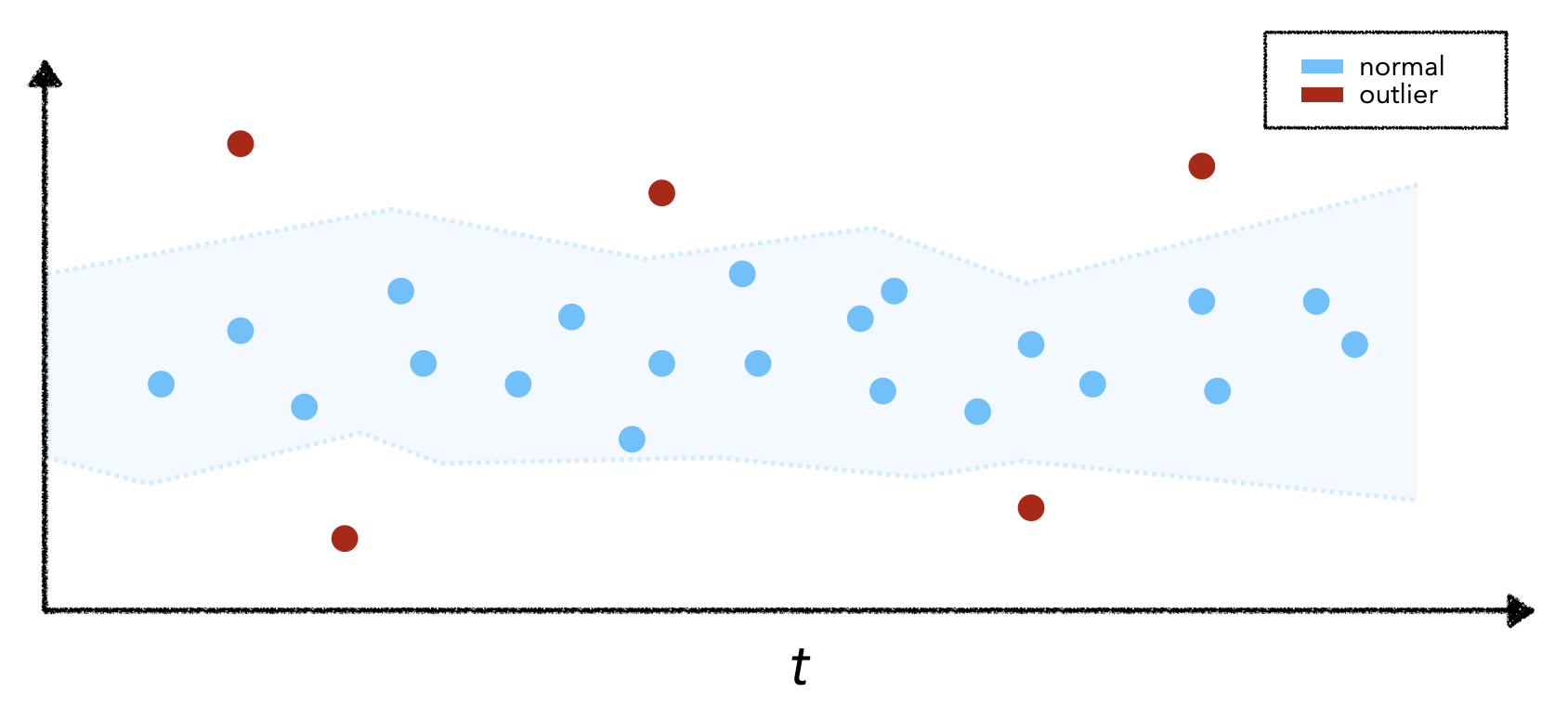
不幸的是,检测异常值并不容易,因为很难构成异常值的标准。因此,异常值检测任务通常是无监督的,并且需要随机流算法来识别潜在的异常值。幸运的是,有几个强大的库,例如PyOD、Alibi Detect、WhyLogs(使用Apache DataSketches)等,它们提供了一套异常值检测功能(目前主要用于表格和图像数据)。
通常,异常值检测算法适合(例如通过重建)训练集以了解正常数据的样子,然后可以使用阈值来预测异常值。如果有一个带有异常值的小标记数据集,可以凭经验选择阈值,但如果没有,可以选择一些合理的容差。
from alibi_detect.od import OutlierVAE
X_train = (n_samples, n_features)
outlier_detector = OutlierVAE(
threshold=0.05,
encoder_net=encoder,
decoder_net=decoder,
latent_dim=512
)
outlier_detector.fit(X_train, epochs=50)
outlier_detector.infer_threshold(X, threshold_perc=95) # infer from % outliers
preds = outlier_detector.predict(X, outlier_type="instance", outlier_perc=75)
当识别异常值时,可能想让最终用户知道模型的响应可能不可靠。此外,可能希望从下一个训练集中删除异常值,或者进一步检查它们并对其进行上采样,以防它们是传入特征未来分布情况的早期迹象。
解决方案
仅仅能够测量漂移或识别异常值是不够的,还能够对其采取行动。希望能够对漂移发出警报,对其进行检查然后采取行动。
警报
一旦确定了异常值和/或测量了统计上显着的漂移,需要设计一个工作流程来通知利益相关者这些问题。监控的负面含义是由误报警报引起的疲劳。这可以通过根据对特定应用程序重要的内容选择适当的约束(例如警报阈值)来缓解。例如,阈值可以是:
-
固定值/范围,用于具体了解预期上限/下限的情况。
if percentage_unk_tokens > 5%: trigger_alert() -
预测阈值取决于先前的输入、时间等。
if current_f1 < forecast_f1(current_time): trigger_alert() -
不同漂移检测器的适当 p 值(↓ p 值 = ↑ 确信分布不同)。
from alibi_detect.cd import KSDrift length_drift_detector = KSDrift(reference, p_val=0.01)
一旦精心设计了警报工作流程,就可以在出现问题时通过电子邮件、Slack、PageDuty等通知利益相关者。利益相关者可以是不同级别的(核心工程师、经理等),他们可以订阅警报与他们相关的。
检查
一旦收到警报,需要在采取行动之前对其进行检查。警报需要几个组件才能让完全检查它:
- 触发的特定警报
- 相关元数据(时间、输入、输出等)
- 失败的阈值/期望
- 进行的漂移检测测试
- 来自参考和测试窗口的数据
- 相关时间窗口的日志记录
# Sample alerting ticket
{
"triggered_alerts": ["text_length_drift"],
"threshold": 0.05,
"measurement": "KSDrift",
"distance": 0.86,
"p_val": 0.03,
"reference": [],
"target": [],
"logs": ...
}
有了这些信息,可以从警报开始向后工作,以确定问题的根本原因。根本原因分析 (RCA)在监控方面是重要的第一步,因为希望防止同样的问题再次影响系统。通常会触发许多警报,但它们实际上可能都是由相同的潜在问题引起的。在这种情况下,只想智能地触发一个指出核心问题的警报。例如,假设收到一条警报,表明整体用户满意度评分正在下降,但还收到另一条警报,指出北美用户的满意度评分也很低。这是系统将自动评估跨许多不同切片和聚合的用户满意度评分的漂移,以发现只有特定区域的用户遇到问题,但由于它是一个受欢迎的用户群,它最终也会触发所有聚合下游警报!
行为
根据情况,可以采取许多不同的方式来漂移。最初的冲动可能是在新数据上重新训练模型,但它可能并不总能解决根本问题。
- 确保所有数据预期均已通过。
- 确认没有数据架构更改。
- 在新的移位数据集上重新训练模型。
- 将参考窗口移动到更新的数据或赋予它更多的权重。
- 确定异常值是否是潜在的有效数据点。
生产
由于检测漂移和异常值可能涉及计算密集型操作,因此需要一种能够在事件数据流(例如Kafka)之上执行无服务器工作负载的解决方案。通常,这些解决方案将摄取有效负载(例如模型的输入和输出)并可以触发监控工作负载。这使能够将用于监控的资源与实际 ML 应用程序隔离开来,并根据需要对其进行扩展。
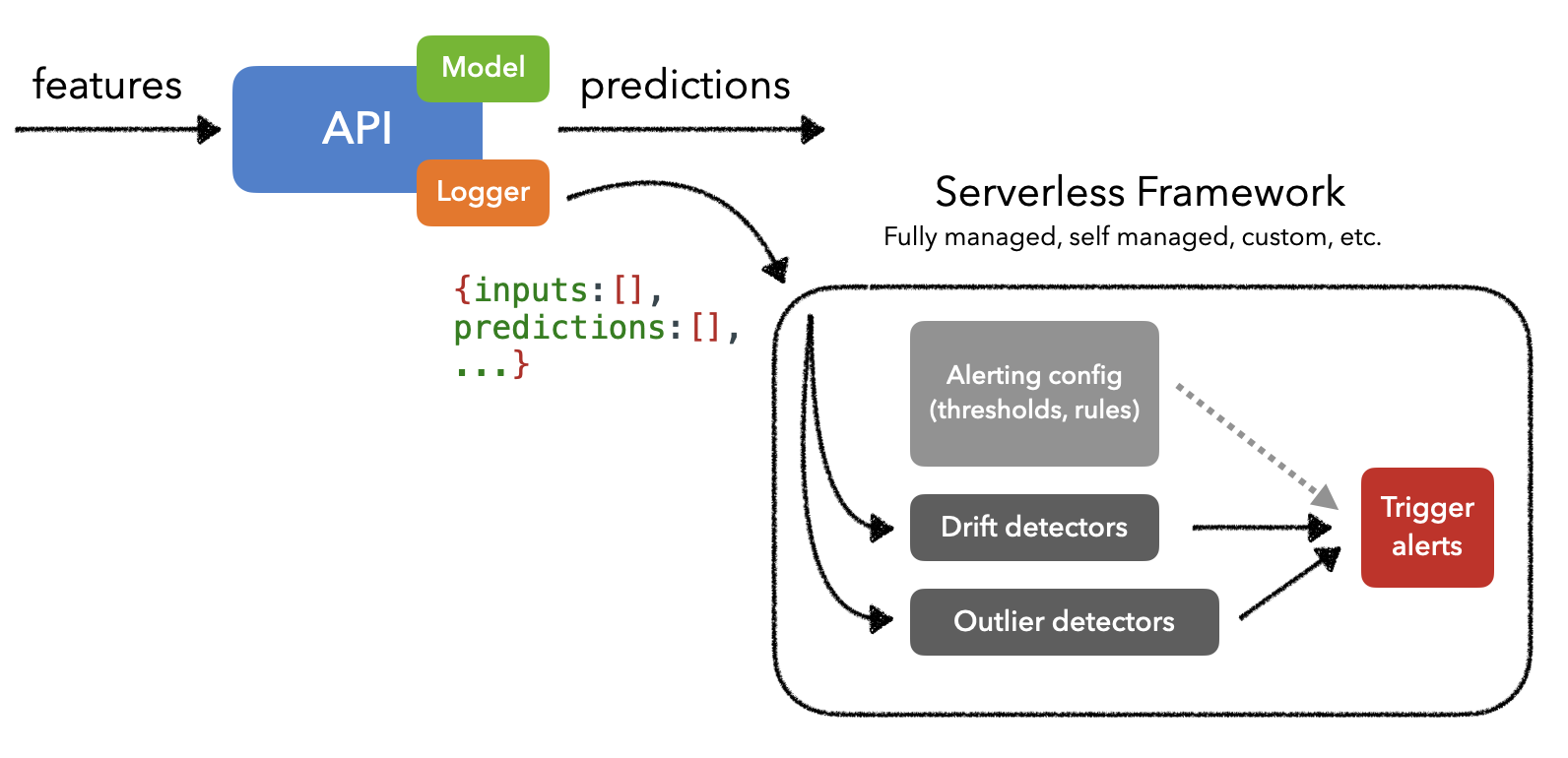
在实际实施监控系统时,有多种选择,从完全托管到从头开始。几种流行的托管解决方案是Arize、Arthur、Fiddler、Gantry、Mona、WhyLabs等,所有这些都允许创建自定义监控视图、触发警报等。甚至还有几个很棒的开源解决方案,例如EvidentlyAI、TorchDrift ,为什么日志等
经常会注意到监控解决方案是作为更大部署选项的一部分提供的,例如Sagemaker、TensorFlow Extended (TFX)、TorchServe等。如果已经在使用 Kubernetes,可以将KNative或Kubeless用于无服务器工作负载管理。但也可以使用更高级别的框架,例如KFServing或Seldon 核心,它们本机使用 KNative 等无服务器框架。
参考
更多干货,第一时间更新在以下微信公众号:

您的一点点支持,是我后续更多的创造和贡献

转载到请包括本文地址 更详细的转载事宜请参考文章如何转载/引用
本文主体源自以下链接:
@article{madewithml,
author = {Goku Mohandas},
title = { Made With ML },
howpublished = {\url{https://madewithml.com/}},
year = {2022}
}