1012
透视图

1015
各种各样神奇的自注意力机制(Self-attention)变形
沐神的装机经验总结
- 装机清单
装机的需求,首先就要是足够安静。不然太吵的话没法工作。
第二个需求就是散热要好。不然温度过高的话会导致GPU降频。
第三个,重点来了,因为需要跑比较大的Transformer模型,所以GPU的带宽必须足够好。
- 装机步骤
1025
文档智能(DI, Document Intelligence)主要指对于网页、数字文档或扫描文档所包含的文本以及丰富的排版格式等信息,通过人工智能技术进行理解、分类、提取以及信息归纳的过程。
Chain of Thought论文、代码和资源
- zero-shot:输入问题,等待输出结果
- CoT:输入问题并提示Let’s think step by step
- Manual-CoT: 是一种few shot方法,所以构造了一些模板Q&A(模板A中也有Let’s think step by step),然后再给出问题并提示Let’s think step by step
- Auto-CoT:采样多个问题,每个问题提示Let’s think step by step,让模型给出答案。然后拼接所有生成的Q&A并给出最终问题,并提示Let’s think step by step
为什么需要CoT?
问题可以分为两类:一类是容易回答的,没有太多逻辑推理的,比如:天气如何?面包几块钱?另一类是需要长链条的逻辑推理的问题:数学等。
当语言模型的规模指数级增大时,它解决常规问题的能力有了很大的提升,然而它解决逻辑推理的问题的能力却提升很小。而CoT就是帮助解决这样的问题,它的核心思想是:不要光给出答案,把推理过程也给出来。如下图所示,关键在于构造的prompt要包含推理过程:
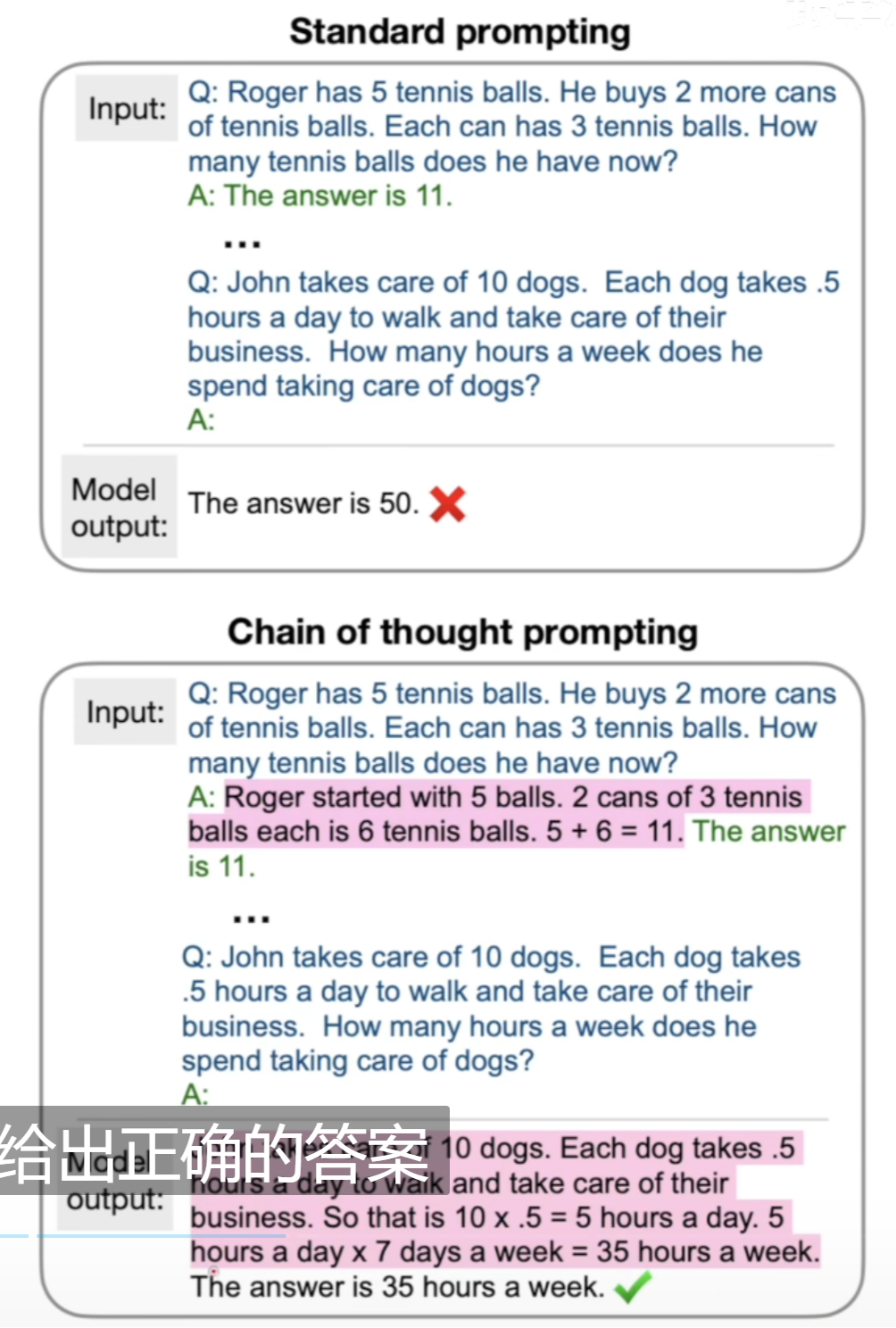
为什么延长推理过程就有效呢?这可能是因为语言模型token-by-token的特点。
标准的prompt可以被视为大模型能力的下限,如何提取大模型学到的知识的问题是一个难点,标准的prompt是一个很好的起点,但却绝不是终点。
如何用 GPT-3 这类的大语言模型来做零样本、单样本和少样本学习?
05:41
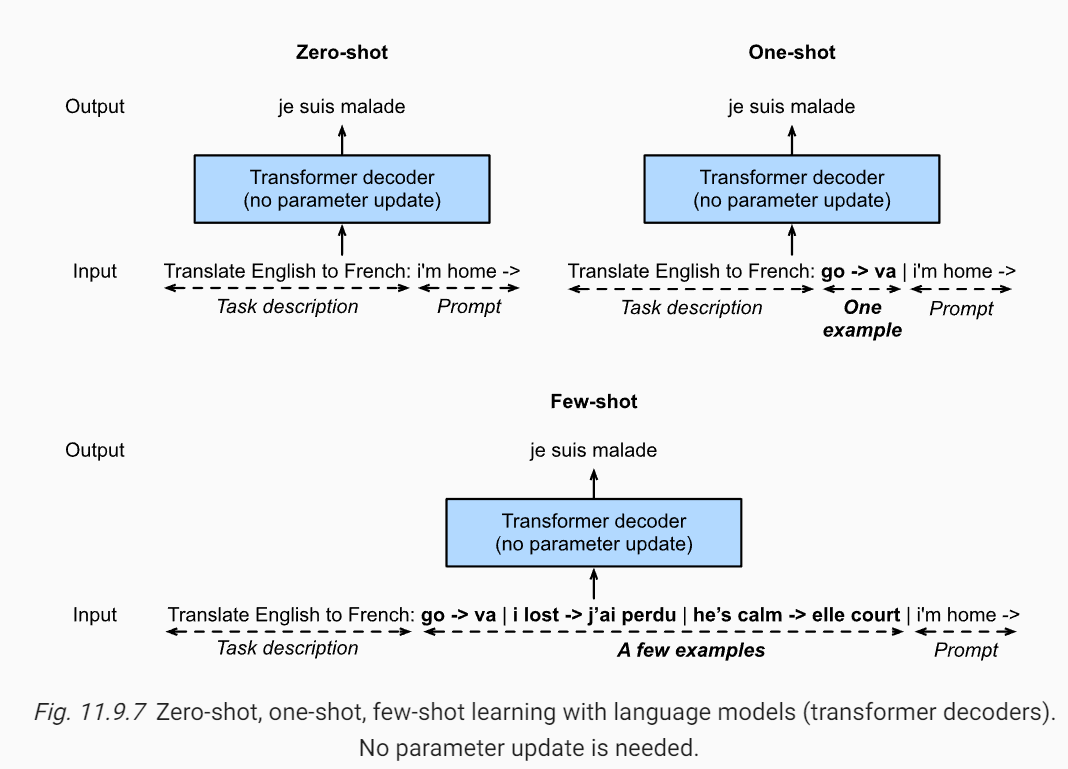
- 对于 GPT-3 来说,也就是图中的 transformer decoder,无论是在零样本、单样本还是少样本的情况下,它们的输入都是一段文本序列,输出也是一段文本序列
- 少样本与零样本的唯一区别就是中间多出了一些参考样例,它们其实都是在续写前缀(只是零样本的输入没有任何参考,而少样本的输入有一些参考样例来帮助语言模型推断如何根据任务输入生成相应的任务输出)
1030


1104
| 方案来源 | 机器 | 机器配置 | 单个请求时间 | 是否使用GPU | 显存 | ||
|---|---|---|---|---|---|---|---|
| en_ppocr_mobile_v2.0_table_structure_infer | TabelRec | 百度paddle | 192.168.101.44 | 0.7s | 是 | 860M | |
| en_ppstructure_mobile_v2.0_SLANet_infer | SLANet | 百度paddle | 192.168.101.44 | 0.7s | 是 | 800M | |
| table_structure_tablemaster_infer | tablemaster | 百度paddle | 192.168.101.44 | 3.6s | 是 | 1300M | |
| table_structure_tablemaster_infer | tablemaster | 百度paddle | 192.168.101.44 | 288s | 否 | ||
| 自研 tablemaster | tablemaster | 自研 | 192.168.101.44 | 5.5s | 是 | 2300M | |
| 自研 tablemaster | tablemaster | 自研 | 压测的测试机器 | 87s或者37s | 是 | 2500M |