ML2025 Homework 1 - Retrieval Augmented Generation with Agents
Environment Setup
First, we will mount your own Google Drive and change the working directory.
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
# Change the working directory to somewhere in your Google Drive.
# You could check the path by right clicking on the folder.
%cd [change to the directory you prefer]
[Errno 2] No such file or directory: '[change to the directory you prefer]'
/content
In this section, we install the necessary python packages and download model weights of the quantized version of LLaMA 3.1 8B. Also, download the dataset. Note that the model weight is around 8GB. If you are using your Google Drive as the working directory, make sure you have enough space for the model.
!python3 -m pip install --no-cache-dir llama-cpp-python==0.3.4 --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cu122
!python3 -m pip install googlesearch-python bs4 charset-normalizer requests-html lxml_html_clean
from pathlib import Path
if not Path('./Meta-Llama-3.1-8B-Instruct-Q8_0.gguf').exists():
!wget https://huggingface.co/bartowski/Meta-Llama-3.1-8B-Instruct-GGUF/resolve/main/Meta-Llama-3.1-8B-Instruct-Q8_0.gguf
if not Path('./public.txt').exists():
!wget https://www.csie.ntu.edu.tw/~ulin/public.txt
if not Path('./private.txt').exists():
!wget https://www.csie.ntu.edu.tw/~ulin/private.txt
Looking in indexes: https://pypi.org/simple, https://abetlen.github.io/llama-cpp-python/whl/cu122
Collecting llama-cpp-python==0.3.4
Downloading https://github.com/abetlen/llama-cpp-python/releases/download/v0.3.4-cu122/llama_cpp_python-0.3.4-cp311-cp311-linux_x86_64.whl (445.2 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m445.2/445.2 MB[0m [31m92.8 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: typing-extensions>=4.5.0 in /usr/local/lib/python3.11/dist-packages (from llama-cpp-python==0.3.4) (4.13.2)
Requirement already satisfied: numpy>=1.20.0 in /usr/local/lib/python3.11/dist-packages (from llama-cpp-python==0.3.4) (2.0.2)
Collecting diskcache>=5.6.1 (from llama-cpp-python==0.3.4)
Downloading diskcache-5.6.3-py3-none-any.whl.metadata (20 kB)
Requirement already satisfied: jinja2>=2.11.3 in /usr/local/lib/python3.11/dist-packages (from llama-cpp-python==0.3.4) (3.1.6)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.11/dist-packages (from jinja2>=2.11.3->llama-cpp-python==0.3.4) (3.0.2)
Downloading diskcache-5.6.3-py3-none-any.whl (45 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m45.5/45.5 kB[0m [31m8.6 MB/s[0m eta [36m0:00:00[0m
[?25hInstalling collected packages: diskcache, llama-cpp-python
Successfully installed diskcache-5.6.3 llama-cpp-python-0.3.4
Collecting googlesearch-python
Downloading googlesearch_python-1.3.0-py3-none-any.whl.metadata (3.4 kB)
Collecting bs4
Downloading bs4-0.0.2-py2.py3-none-any.whl.metadata (411 bytes)
Requirement already satisfied: charset-normalizer in /usr/local/lib/python3.11/dist-packages (3.4.1)
Collecting requests-html
Downloading requests_html-0.10.0-py3-none-any.whl.metadata (15 kB)
Collecting lxml_html_clean
Downloading lxml_html_clean-0.4.2-py3-none-any.whl.metadata (2.4 kB)
Requirement already satisfied: beautifulsoup4>=4.9 in /usr/local/lib/python3.11/dist-packages (from googlesearch-python) (4.13.4)
Requirement already satisfied: requests>=2.20 in /usr/local/lib/python3.11/dist-packages (from googlesearch-python) (2.32.3)
Collecting pyquery (from requests-html)
Downloading pyquery-2.0.1-py3-none-any.whl.metadata (9.0 kB)
Collecting fake-useragent (from requests-html)
Downloading fake_useragent-2.2.0-py3-none-any.whl.metadata (17 kB)
Collecting parse (from requests-html)
Downloading parse-1.20.2-py2.py3-none-any.whl.metadata (22 kB)
Collecting w3lib (from requests-html)
Downloading w3lib-2.3.1-py3-none-any.whl.metadata (2.3 kB)
Collecting pyppeteer>=0.0.14 (from requests-html)
Downloading pyppeteer-2.0.0-py3-none-any.whl.metadata (7.1 kB)
Requirement already satisfied: lxml in /usr/local/lib/python3.11/dist-packages (from lxml_html_clean) (5.4.0)
Requirement already satisfied: soupsieve>1.2 in /usr/local/lib/python3.11/dist-packages (from beautifulsoup4>=4.9->googlesearch-python) (2.7)
Requirement already satisfied: typing-extensions>=4.0.0 in /usr/local/lib/python3.11/dist-packages (from beautifulsoup4>=4.9->googlesearch-python) (4.13.2)
Collecting appdirs<2.0.0,>=1.4.3 (from pyppeteer>=0.0.14->requests-html)
Downloading appdirs-1.4.4-py2.py3-none-any.whl.metadata (9.0 kB)
Requirement already satisfied: certifi>=2023 in /usr/local/lib/python3.11/dist-packages (from pyppeteer>=0.0.14->requests-html) (2025.1.31)
Requirement already satisfied: importlib-metadata>=1.4 in /usr/local/lib/python3.11/dist-packages (from pyppeteer>=0.0.14->requests-html) (8.6.1)
Collecting pyee<12.0.0,>=11.0.0 (from pyppeteer>=0.0.14->requests-html)
Downloading pyee-11.1.1-py3-none-any.whl.metadata (2.8 kB)
Requirement already satisfied: tqdm<5.0.0,>=4.42.1 in /usr/local/lib/python3.11/dist-packages (from pyppeteer>=0.0.14->requests-html) (4.67.1)
Collecting urllib3<2.0.0,>=1.25.8 (from pyppeteer>=0.0.14->requests-html)
Downloading urllib3-1.26.20-py2.py3-none-any.whl.metadata (50 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m50.1/50.1 kB[0m [31m5.0 MB/s[0m eta [36m0:00:00[0m
[?25hCollecting websockets<11.0,>=10.0 (from pyppeteer>=0.0.14->requests-html)
Downloading websockets-10.4-cp311-cp311-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (6.4 kB)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.11/dist-packages (from requests>=2.20->googlesearch-python) (3.10)
Collecting cssselect>=1.2.0 (from pyquery->requests-html)
Downloading cssselect-1.3.0-py3-none-any.whl.metadata (2.6 kB)
Requirement already satisfied: zipp>=3.20 in /usr/local/lib/python3.11/dist-packages (from importlib-metadata>=1.4->pyppeteer>=0.0.14->requests-html) (3.21.0)
Downloading googlesearch_python-1.3.0-py3-none-any.whl (5.6 kB)
Downloading bs4-0.0.2-py2.py3-none-any.whl (1.2 kB)
Downloading requests_html-0.10.0-py3-none-any.whl (13 kB)
Downloading lxml_html_clean-0.4.2-py3-none-any.whl (14 kB)
Downloading pyppeteer-2.0.0-py3-none-any.whl (82 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m82.9/82.9 kB[0m [31m10.2 MB/s[0m eta [36m0:00:00[0m
[?25hDownloading fake_useragent-2.2.0-py3-none-any.whl (161 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m161.7/161.7 kB[0m [31m17.4 MB/s[0m eta [36m0:00:00[0m
[?25hDownloading parse-1.20.2-py2.py3-none-any.whl (20 kB)
Downloading pyquery-2.0.1-py3-none-any.whl (22 kB)
Downloading w3lib-2.3.1-py3-none-any.whl (21 kB)
Downloading appdirs-1.4.4-py2.py3-none-any.whl (9.6 kB)
Downloading cssselect-1.3.0-py3-none-any.whl (18 kB)
Downloading pyee-11.1.1-py3-none-any.whl (15 kB)
Downloading urllib3-1.26.20-py2.py3-none-any.whl (144 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m144.2/144.2 kB[0m [31m15.5 MB/s[0m eta [36m0:00:00[0m
[?25hDownloading websockets-10.4-cp311-cp311-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl (107 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m107.4/107.4 kB[0m [31m11.7 MB/s[0m eta [36m0:00:00[0m
[?25hInstalling collected packages: parse, appdirs, websockets, w3lib, urllib3, pyee, lxml_html_clean, fake-useragent, cssselect, pyquery, pyppeteer, bs4, requests-html, googlesearch-python
Attempting uninstall: websockets
Found existing installation: websockets 15.0.1
Uninstalling websockets-15.0.1:
Successfully uninstalled websockets-15.0.1
Attempting uninstall: urllib3
Found existing installation: urllib3 2.4.0
Uninstalling urllib3-2.4.0:
Successfully uninstalled urllib3-2.4.0
[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
google-genai 1.12.1 requires websockets<15.1.0,>=13.0.0, but you have websockets 10.4 which is incompatible.[0m[31m
[0mSuccessfully installed appdirs-1.4.4 bs4-0.0.2 cssselect-1.3.0 fake-useragent-2.2.0 googlesearch-python-1.3.0 lxml_html_clean-0.4.2 parse-1.20.2 pyee-11.1.1 pyppeteer-2.0.0 pyquery-2.0.1 requests-html-0.10.0 urllib3-1.26.20 w3lib-2.3.1 websockets-10.4
--2025-04-30 02:17:56-- https://huggingface.co/bartowski/Meta-Llama-3.1-8B-Instruct-GGUF/resolve/main/Meta-Llama-3.1-8B-Instruct-Q8_0.gguf
Resolving huggingface.co (huggingface.co)... 18.164.174.23, 18.164.174.118, 18.164.174.55, ...
Connecting to huggingface.co (huggingface.co)|18.164.174.23|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://cas-bridge.xethub.hf.co/xet-bridge-us/669fce02988201fd4f9ceddc/13ba7de6d825796cd4846a9428031ca1be96a4f615bce26c19aafb27a9cf8a2c?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=cas%2F20250430%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20250430T021756Z&X-Amz-Expires=3600&X-Amz-Signature=09bd0a16f97c087142e15c5bbc8605a25fc05215bef8e1bf14f4931c9dcaa1d2&X-Amz-SignedHeaders=host&X-Xet-Cas-Uid=public&response-content-disposition=inline%3B+filename*%3DUTF-8%27%27Meta-Llama-3.1-8B-Instruct-Q8_0.gguf%3B+filename%3D%22Meta-Llama-3.1-8B-Instruct-Q8_0.gguf%22%3B&x-id=GetObject&Expires=1745983076&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTc0NTk4MzA3Nn19LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2FzLWJyaWRnZS54ZXRodWIuaGYuY28veGV0LWJyaWRnZS11cy82NjlmY2UwMjk4ODIwMWZkNGY5Y2VkZGMvMTNiYTdkZTZkODI1Nzk2Y2Q0ODQ2YTk0MjgwMzFjYTFiZTk2YTRmNjE1YmNlMjZjMTlhYWZiMjdhOWNmOGEyYyoifV19&Signature=qrHa6MD08GZEJdunFJYwv%7Eu5Ha9d%7EzCMukdx6PUvMZx1rYSfG8awhkd%7EDx-87dcUK3krQ2e3butvr3i1RCu60Su8p3%7EX%7ERN8%7EJTAYa2eXblIwHYd9qpw3Isw4hENr-X3uUmfH72xhcuOn8wBEEHPQOD6P7u%7EATOoWzU9bLpvkZ5vNASQnYD8L-6Pz2XV5N9xCU8yKHFsPeCfIclKZ7hyV5zDZM-I2nEk1nO3sx2k%7EPCJ324%7EUMf63xkbrhancXDYPbV8HC3Dfs%7EicqEc6iSXGP--jeyiisG0xCghsS5L9y7zW2Om8tze0PB2xlOV9JB9qQyIYYDDithdLvfzEzQlIQ__&Key-Pair-Id=K2L8F4GPSG1IFC [following]
--2025-04-30 02:17:56-- https://cas-bridge.xethub.hf.co/xet-bridge-us/669fce02988201fd4f9ceddc/13ba7de6d825796cd4846a9428031ca1be96a4f615bce26c19aafb27a9cf8a2c?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=cas%2F20250430%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20250430T021756Z&X-Amz-Expires=3600&X-Amz-Signature=09bd0a16f97c087142e15c5bbc8605a25fc05215bef8e1bf14f4931c9dcaa1d2&X-Amz-SignedHeaders=host&X-Xet-Cas-Uid=public&response-content-disposition=inline%3B+filename*%3DUTF-8%27%27Meta-Llama-3.1-8B-Instruct-Q8_0.gguf%3B+filename%3D%22Meta-Llama-3.1-8B-Instruct-Q8_0.gguf%22%3B&x-id=GetObject&Expires=1745983076&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTc0NTk4MzA3Nn19LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2FzLWJyaWRnZS54ZXRodWIuaGYuY28veGV0LWJyaWRnZS11cy82NjlmY2UwMjk4ODIwMWZkNGY5Y2VkZGMvMTNiYTdkZTZkODI1Nzk2Y2Q0ODQ2YTk0MjgwMzFjYTFiZTk2YTRmNjE1YmNlMjZjMTlhYWZiMjdhOWNmOGEyYyoifV19&Signature=qrHa6MD08GZEJdunFJYwv%7Eu5Ha9d%7EzCMukdx6PUvMZx1rYSfG8awhkd%7EDx-87dcUK3krQ2e3butvr3i1RCu60Su8p3%7EX%7ERN8%7EJTAYa2eXblIwHYd9qpw3Isw4hENr-X3uUmfH72xhcuOn8wBEEHPQOD6P7u%7EATOoWzU9bLpvkZ5vNASQnYD8L-6Pz2XV5N9xCU8yKHFsPeCfIclKZ7hyV5zDZM-I2nEk1nO3sx2k%7EPCJ324%7EUMf63xkbrhancXDYPbV8HC3Dfs%7EicqEc6iSXGP--jeyiisG0xCghsS5L9y7zW2Om8tze0PB2xlOV9JB9qQyIYYDDithdLvfzEzQlIQ__&Key-Pair-Id=K2L8F4GPSG1IFC
Resolving cas-bridge.xethub.hf.co (cas-bridge.xethub.hf.co)... 18.164.174.110, 18.164.174.21, 18.164.174.4, ...
Connecting to cas-bridge.xethub.hf.co (cas-bridge.xethub.hf.co)|18.164.174.110|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 8540775840 (8.0G)
Saving to: ‘Meta-Llama-3.1-8B-Instruct-Q8_0.gguf’
Meta-Llama-3.1-8B-I 100%[===================>] 7.95G 131MB/s in 50s
2025-04-30 02:18:46 (162 MB/s) - ‘Meta-Llama-3.1-8B-Instruct-Q8_0.gguf’ saved [8540775840/8540775840]
--2025-04-30 02:18:47-- https://www.csie.ntu.edu.tw/~ulin/public.txt
Resolving www.csie.ntu.edu.tw (www.csie.ntu.edu.tw)... 140.112.30.26
Connecting to www.csie.ntu.edu.tw (www.csie.ntu.edu.tw)|140.112.30.26|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 4399 (4.3K) [text/plain]
Saving to: ‘public.txt’
public.txt 100%[===================>] 4.30K --.-KB/s in 0s
2025-04-30 02:18:48 (229 MB/s) - ‘public.txt’ saved [4399/4399]
--2025-04-30 02:18:48-- https://www.csie.ntu.edu.tw/~ulin/private.txt
Resolving www.csie.ntu.edu.tw (www.csie.ntu.edu.tw)... 140.112.30.26
Connecting to www.csie.ntu.edu.tw (www.csie.ntu.edu.tw)|140.112.30.26|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 15229 (15K) [text/plain]
Saving to: ‘private.txt’
private.txt 100%[===================>] 14.87K --.-KB/s in 0.1s
2025-04-30 02:18:48 (109 KB/s) - ‘private.txt’ saved [15229/15229]
import torch
if not torch.cuda.is_available():
raise Exception('You are not using the GPU runtime. Change it first or you will suffer from the super slow inference speed!')
else:
print('You are good to go!')
You are good to go!
Prepare the LLM and LLM utility function
By default, we will use the quantized version of LLaMA 3.1 8B. you can get full marks on this homework by using the provided LLM and LLM utility function. You can also try out different LLM models.
In the following code block, we will load the downloaded LLM model weights onto the GPU first. Then, we implemented the generate_response() function so that you can get the generated response from the LLM model more easily.
You can ignore “llama_new_context_with_model: n_ctx_per_seq (16384) < n_ctx_train (131072) – the full capacity of the model will not be utilized” warning.
from llama_cpp import Llama
# Load the model onto GPU
llama3 = Llama(
"./Meta-Llama-3.1-8B-Instruct-Q8_0.gguf",
verbose=False,
n_gpu_layers=-1,
n_ctx=16384, # This argument is how many tokens the model can take. The longer the better, but it will consume more memory. 16384 is a proper value for a GPU with 16GB VRAM.
)
def generate_response(_model: Llama, _messages: str) -> str:
'''
This function will inference the model with given messages.
'''
_output = _model.create_chat_completion(
_messages,
stop=["<|eot_id|>", "<|end_of_text|>"],
max_tokens=512, # This argument is how many tokens the model can generate, you can change it and observe the differences.
temperature=0, # This argument is the randomness of the model. 0 means no randomness. You will get the same result with the same input every time. You can try to set it to different values.
repeat_penalty=2.0,
)["choices"][0]["message"]["content"]
return _output
llama_new_context_with_model: n_ctx_per_seq (16384) < n_ctx_train (131072) -- the full capacity of the model will not be utilized
Search Tool
The TA has implemented a search tool for you to search certain keywords using Google Search. You can use this tool to search for the relevant web pages for the given question. The search tool can be integrated in the following sections.
from typing import List
from googlesearch import search as _search
from bs4 import BeautifulSoup
from charset_normalizer import detect
import asyncio
from requests_html import AsyncHTMLSession
import urllib3
urllib3.disable_warnings()
async def worker(s:AsyncHTMLSession, url:str):
try:
header_response = await asyncio.wait_for(s.head(url, verify=False), timeout=10)
if 'text/html' not in header_response.headers.get('Content-Type', ''):
return None
r = await asyncio.wait_for(s.get(url, verify=False), timeout=10)
return r.text
except:
return None
async def get_htmls(urls):
session = AsyncHTMLSession()
tasks = (worker(session, url) for url in urls)
return await asyncio.gather(*tasks)
async def search(keyword: str, n_results: int=3) -> List[str]:
'''
This function will search the keyword and return the text content in the first n_results web pages.
Warning: You may suffer from HTTP 429 errors if you search too many times in a period of time. This is unavoidable and you should take your own risk if you want to try search more results at once.
The rate limit is not explicitly announced by Google, hence there's not much we can do except for changing the IP or wait until Google unban you (we don't know how long the penalty will last either).
'''
keyword = keyword[:100]
# First, search the keyword and get the results. Also, get 2 times more results in case some of them are invalid.
results = list(_search(keyword, n_results * 2, lang="zh", unique=True))
# Then, get the HTML from the results. Also, the helper function will filter out the non-HTML urls.
results = await get_htmls(results)
# Filter out the None values.
results = [x for x in results if x is not None]
# Parse the HTML.
results = [BeautifulSoup(x, 'html.parser') for x in results]
# Get the text from the HTML and remove the spaces. Also, filter out the non-utf-8 encoding.
results = [''.join(x.get_text().split()) for x in results if detect(x.encode()).get('encoding') == 'utf-8']
# Return the first n results.
return results[:n_results]
Test the LLM inference pipeline
# You can try out different questions here.
test_question='請問誰是 Taylor Swift?'
messages = [
{"role": "system", "content": "你是 LLaMA-3.1-8B,是用來回答問題的 AI。使用中文時只會使用繁體中文來回問題。"}, # System prompt
{"role": "user", "content": test_question}, # User prompt
]
print(generate_response(llama3, messages))
泰勒絲(Taylor Swift)是一位美國歌手、詞曲作家和音樂製作人。她出生於1989年,來自田納西州。她的音乐风格从乡村摇滚发展到流行搖擺,並且她被誉为当代最成功的女艺人的之一。
泰勒絲早期在鄉郊小鎮演唱會時開始發展音樂事業,她推出了多張專輯,包括《Taylor Swift》、《Fearless》,以及後來更為知名的大熱作如 《1989》(2014年)、_reputation()和 _Lover ()。她的歌曲經常探討愛情、友誼及自我成長等主題。
泰勒絲獲得了許多獎項,包括13座格萊美奖,並且是史上最快達到百萬銷量的女藝人之一。
Agents
The TA has implemented the Agent class for you. You can use this class to create agents that can interact with the LLM model. The Agent class has the following attributes and methods:
- Attributes:
- role_description: The role of the agent. For example, if you want this agent to be a history expert, you can set the role_description to “You are a history expert. You will only answer questions based on what really happened in the past. Do not generate any answer if you don’t have reliable sources.”.
- task_description: The task of the agent. For example, if you want this agent to answer questions only in yes/no, you can set the task_description to “Please answer the following question in yes/no. Explanations are not needed.”
- llm: Just an indicator of the LLM model used by the agent.
- Method:
- inference: This method takes a message as input and returns the generated response from the LLM model. The message will first be formatted into proper input for the LLM model. (This is where you can set some global instructions like “Please speak in a polite manner” or “Please provide a detailed explanation”.) The generated response will be returned as the output.
class LLMAgent():
def __init__(self, role_description: str, task_description: str, llm:str="bartowski/Meta-Llama-3.1-8B-Instruct-GGUF"):
self.role_description = role_description # Role means who this agent should act like. e.g. the history expert, the manager......
self.task_description = task_description # Task description instructs what task should this agent solve.
self.llm = llm # LLM indicates which LLM backend this agent is using.
def inference(self, message:str) -> str:
if self.llm == 'bartowski/Meta-Llama-3.1-8B-Instruct-GGUF': # If using the default one.
# TODO: Design the system prompt and user prompt here.
# Format the messsages first.
messages = [
{"role": "system", "content": f"{self.role_description}"}, # Hint: you may want the agents to speak Traditional Chinese only.
{"role": "user", "content": f"{self.task_description}\n{message}"}, # Hint: you may want the agents to clearly distinguish the task descriptions and the user messages. A proper seperation text rather than a simple line break is recommended.
]
return generate_response(llama3, messages)
else:
# TODO: If you want to use LLMs other than the given one, please implement the inference part on your own.
return ""
TODO: Design the role description and task description for each agent.
# TODO: Design the role and task description for each agent.
# This agent may help you filter out the irrelevant parts in question descriptions.
question_extraction_agent = LLMAgent(
role_description="",
task_description="",
)
# This agent may help you extract the keywords in a question so that the search tool can find more accurate results.
keyword_extraction_agent = LLMAgent(
role_description="",
task_description="",
)
# This agent is the core component that answers the question.
qa_agent = LLMAgent(
role_description="你是 LLaMA-3.1-8B,是用來回答問題的 AI。使用中文時只會使用繁體中文來回問題。",
task_description="請回答以下問題:",
)
RAG pipeline
TODO: Implement the RAG pipeline.
Please refer to the homework description slides for hints.
Also, there might be more heuristics (e.g. classifying the questions based on their lengths, determining if the question need a search or not, reconfirm the answer before returning it to the user……) that are not shown in the flow charts. You can use your creativity to come up with a better solution!
-
Naive approach (simple baseline)
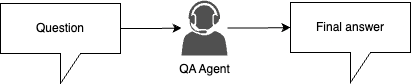
-
Naive RAG approach (medium baseline)
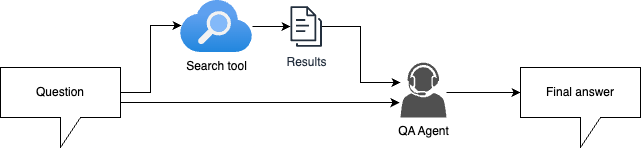
-
RAG with agents (strong baseline)
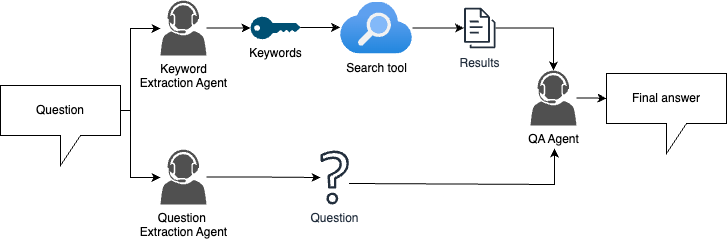
async def pipeline(question: str) -> str:
# TODO: Implement your pipeline.
# Currently, it only feeds the question directly to the LLM.
# You may want to get the final results through multiple inferences.
# Just a quick reminder, make sure your input length is within the limit of the model context window (16384 tokens), you may want to truncate some excessive texts.
return qa_agent.inference(question)
Answer the questions using your pipeline!
Since Colab has usage limit, you might encounter the disconnections. The following code will save your answer for each question. If you have mounted your Google Drive as instructed, you can just rerun the whole notebook to continue your process.
from pathlib import Path
# Fill in your student ID first.
STUDENT_ID = "th"
STUDENT_ID = STUDENT_ID.lower()
with open('./public.txt', 'r') as input_f:
questions = input_f.readlines()
questions = [l.strip().split(',')[0] for l in questions]
for id, question in enumerate(questions, 1):
if Path(f"./{STUDENT_ID}_{id}.txt").exists():
continue
answer = await pipeline(question)
answer = answer.replace('\n',' ')
print(id, answer)
with open(f'./{STUDENT_ID}_{id}.txt', 'w') as output_f:
print(answer, file=output_f)
with open('./private.txt', 'r') as input_f:
questions = input_f.readlines()
for id, question in enumerate(questions, 31):
if Path(f"./{STUDENT_ID}_{id}.txt").exists():
continue
answer = await pipeline(question)
answer = answer.replace('\n',' ')
print(id, answer)
with open(f'./{STUDENT_ID}_{id}.txt', 'a') as output_f:
print(answer, file=output_f)
1 「虎山雄風飛揚」是國立臺灣大學的校歌。
2 對不起,我無法提供關於2025年初NCC規定的具體數據。
3 第一代 iPhone 是由史蒂夫·乔布斯(Steve Jobs)發表的。
4 根據台灣大學的進階英文免修申請規定,托福網路測驗 TOEFL iBT 的成績需達到 80 分以上才能符合資格。
5 在橄欖球聯盟(Rugby Union)中,觸地試踢得 5 分。
6 根據歷史記載,卑南族的祖先發源自ruvuwa'an,這個地點被認為是位於現今臺灣省臺東縣太麻里鄉附近。
7 根據我的知識,熊仔的碩士指導教授是黃韻玲。
8 答案:詹姆斯·克拉ーク・マ克斯韋爾。
9 根據我的資料,距離國立臺灣史前文化博物館最近的臺鐵車站是「台東火车駅」。
10 答案是:50
11 對不起,我無法提供關於未來的 NBA 賽事資訊,因為我只知道到 2023 年底。
12 對不起,我無法提供關於未來事件的確切信息,特別是政治選舉結果。2024年美國總統大选尚在進行中,並且各個候任人士仍然競爭當時。我可以幫助你了解更多有关于美国总统竞争和历史上相关事項嗎?
13 根據我的知識,Llama-3.1 系列模型中參數量最小的為 LLaMA 7B(約有七十億個参数),但我無法確認是否能找到更低版本。
14 根據國立臺灣大學學則,停修有更嚴格的限制。依照規定,在沒有師生雙方同意的情況下,每個班級每年最多只能申請兩門課程停止上课(即「退選」),但如果是因為個人原因需要暫時休息或轉學等情形,則可以向系辦提出停修申请。
15 對不起,我無法找到任何有關DeepSeek公司的相關資訊。
16 對不起,我無法提供最新的資訊或未來事件。2024年NBA總冠軍隊伍尚待確認,請關注官方新聞和賽事結果以獲得最準確且更新至今的情況報告
17 這類化合物稱為烯(Alkene)。
18 答案是阿倫·圖靈(Alan Turing)。他是一位英國數學家、計算機科學院院士和密碼破譯者,被認為是在20世紀中期對現代電腦理論做出重大貢獻的人。他的「图灵机」概念奠定了计算理论的基礎,並且他提出的圖靈測試也成為人工智能研究中的重要指標之一。他在密碼破譯方面也有著傑出した成就,曾參與過第二次世界大戰期間對德國加拿大的無線電通訊進行解讀工作。
19 根據我的知識,臺灣玄天上帝信仰的進香中心位於新北市貢寮區。
20 Windows 作業系統是微軟公司(Microsoft)的產品。
21 官將首的起源是由於臺灣南部某間廟宇創立,該名為「天后宮」的福建移民在清治時期所建立。
22 《咒》的邪神名為 "阿修羅"。
23 這個問題的答案是:短暫交會的是五月天的一首歌曲,「旅程就此分岔」就是那一句經典台語詞。
24 對不起,我無法提供 2025 年卑南族聯合年聚的具體資訊,因為這類型的情況可能會根據當地部落和組織者的安排而有所變動。然而,通常來說,這些活動是由各個原住民族委員会或相關機構負責籌辦。 如果你想知道 2025 年卑南族聯合年聚的具體資訊,我建議您可以查詢以下幾種途徃: 1. 卫生部卫生福利厅:他們可能會有關於原住民族活動和節慶相關信息。 2.Taiwan Indigenous Peoples' Festival Committee(臺灣本土人民文化藝術祭籌備委員会):這是一個促進台灣各族群間的交流與合作組織,很大機率能夠提供你想要知道的情況。
25 最新的輝達顯卡系列是「GeForce RTX 40 系列」。這個新一代產品使用了 NVIDIA 的 Ada Lovelace 架構,提供更高效能、更多功能和改進的人工智慧能力。
26 大S(原名陳嘉樺)是在2013年8月去世的,她在美國洛杉磯因為肝硬化併發症而逕自離開醫院,後來被送到急診室,但已經無法挽回。
27 萬有引力的發現通常被歸功於英國物理學家艾薩克·牛頓。他在1687年出版的著作《哲理自然科普論》中提出三大運動定律和万有的吸力法則,描述了物體之間彼此相互作用並引起力的現象。這些工作奠基於萬有導致物理學領域,並對我們理解宇宙的運作方式產生深遠影響。 然而,也有一位古希臘哲理家阿里斯塔克(Aristarchus of Samos)在前3世紀提出了類似的觀點,他認為太陽和其他天體之間存在著某種形式的情感力或吸引力的作用。
28 台鵠開示計畫「TAIHUCAIS」的英文全名為 "Taiwan Indigenous Cultural Assets Information System"。
29 「I'll be back」是出自1984年電影《終極追殺令》(The Terminator)的經典台詞,由阿諾·施瓦辛格飾演的角色泰倫森(T-800)說出的。這句話成為了科幻片中的代表性標誌,也使得「I'll be back」變成了一個流行文化上的符號,常被用來表示復仇或回歸等意義。在續集《終極追殺令2:審判日》中,這一句話也再次出現,並成為了系列電影的標誌性台詞。
30 水的化學式是 H2O。
31 對不起,我無法提供李宏毅教授在《機器學習》2023年春季班中第15個作業的名稱。
32 根據我的知識,目前臺灣公立的獨립學院僅剩一間是國防管理学院(簡稱:德明科大)。
33 BitTorrent 協議使用的機制是叫做 "Tracker" 和 "_piece_選擇算法(Piece Selection Algorithm)或稱為 _bitfield_"。 當一個新的節點加入網路時,該協定會要求 Tracker 服務器提供一份包含所有種子的資訊清單。這些信息包括每個种子拥有的块的数量和哪个block已经下载完成等数据。这使得新节点可以知道谁有它需要什么。 接下来的步骤是使用 _bitfield_ 機制,該機製會將節點所缺乏資料分成多塊,並根據每一片是否已經被其他種子擁有的情況來決定哪些部分的資訊可以從那個特定的种子的哪里下载。
34 這個描述聽起來很像是一部名為"Crash Course: University of California, Berkeley to StanfordUniversity (Motorcycle)"的影片。
35 根據研究人員的觀察報告和實驗結果,戈芬氏鳳頭鸚鵡最受偏好的乳酪口味是什麼呢?答案是在這個文中並沒有明確提及。然而,我們可以從文章中的描述推測出一些線索。 在整篇報導當 中,都有強調戈芬氏鳳頭鸚鵡對於某一特定乳酪口味的偏好,並且這種行為似乎是由它们認知到經過浸泡與翻轉後,食物變得更加美妙所導致。然而,這個文中並沒有明確指出哪一個奶油醬料最受鸚鵡喜愛。 但根據實驗結果,我們可以推測這些戈芬氏鳳頭鳥可能對於一些較為濃郁、香味豐富的乳酪口感有著特別偏好的選擇。
36 很抱歉,我無法找到相關的資訊,關於2024年桃園Xpark水族館國王企鵝「嘟胖」和 「烏龍茶」的產下一隻小孩。
37 根據國立臺灣大學的資訊,物理治療學系目前正常修業年限為四年的碩士班和三年半至五個月(含實習)的博士後研究生。
38 《BanG Dream!》中,「呼嘿哈」或是 「呵~咯」的笑聲習慣,是由Riko Kawamura所扮演的角色。
39 你提到的「甲斐之虎」其實是日本戰國時代的一位著名武將——高良政永的別稱,但最為人所知的是被這個名字冠上的另一人物:真田幸村。
40 根據王肥貓同學的標準,他想要選擇網路上最多好評的一門課。因此,我們需要找出這三個候補中的哪一堂是台大生中人氣最高、口碑最佳。 雖然我沒有實時存取最新資訊,但根據過往資料,「數位素養導航」是一道非常受歡迎的通識課程。它教學內容豐富且有趣,並結合現代社會中的科技元素,使得許多台大生都對這堂课充滿好奇心。 因此,我們可以推測,王肥貓同事最可能選擇「數位素養導航」課程。
41 對不起,我無法提供2024年的第42回《極限體能王SASUKE》首播日期的資訊,因為我沒有最新或實時更新的情況。然而,根據過往慣例和節目安排,你可以嘗試在日本TBS電視台官方網站、社交媒介平台,或是其他相關新聞來源查詢2024年的第42回《極限體能王SASUKE》首播日期的最新資訊。
42 根據歷史記載,出身於利嘉部落後來成為初鹿(或稱為大隘)頭目的漢人,是名叫「張永春」的。
43 《BanG Dream! Ave Mujica》的片頭曲是「」。
44 Linux作業系統最早於1991年首次發布。由林納斯·托瓦茲(Linus Torvalds)在芬蘭赫爾辛基大學開源發展的 Linux核心,最初是為了取代MINIX而設計的一個Unix-like操作系统,並且迅速演變成一個完整、可用的作業系統。在1991年9月25日,他發布了一份名叫"Linux 0.01”的原始碼。
45 根據你的描述,Likavung 部落的中文名稱應該是「利卡武崗部族」或簡稱為 " 利加邦"
46 紅茶是一種半發酵或部分生抽的黑tea。
47 在《遊戲王》卡牌中,以「真紅眼黑龍」與 「黒魔導師」的融合素材,能夠創造出名為 "Black Luster Soldier of Destruction" 的特殊怪獸。
48 豐田萌繪在《BanG Dream!》企劃中,擔任Poppin'Party的角色聲優——櫻Innercircle(咲坂伊澄)。
49 Rugby Union 中,9 號球員的正式名稱為「掃劍半後衛」(Scrum-half)。
50 被視為太陽系中的行星,最終降格成矮天體(或稱小惑 星)的主要是金剛座55番目之五號,即普羅米修斯。
51 根據我的知識,臺灣最早成立的野生動物救傷單位是位於台北市內湖區的大愛鷹醫院。
52 根據我的知識,特生中心在2023年改名後的名字是「集結自然館」。
53 根據我的知識庫,Developing Instruction-FollowING Speech Language Model Without speech instruction-tuning data論文中提出的模型是名為"Instruction-Tuned (IT) 模型的前身,即 "Prompt-Modulated Pre-training and Fine Tunning for Task-Oriented Dialogue Systems(簡稱PMTOD)
54 太陽系中體積最大的行星是土壤外的木質天王巨蟹。
55 根據語言分類學的研究,臺灣原住民族中的阿美族(Amis)和卑南人等部落使用屬於馬來-波利尼西亞支系下的達悟文。然而,這些與其他台灣本土之島嶼上的多數原始民間所說語言相比,其分類學上更接近東印度群岛的巴布亚新几内雅和东帝汶等地原住民族,而非同一南亞-太平洋支系下的阿美族。
56 很抱歉,我無法找到相關的資訊或證據來確認這句話是誰說出過。然而,這個故事可能源自於一位台灣大學老師,許多人猜測他就是陳景峻教授,但我找不到任何可靠的情況可以支持此事實。 如果你有更多關係的資訊或上下文,我會很樂意幫助您進一步探索。
57 「embiyax namu kana」是阿美族的打招呼用語。
58 根據我的知識,「鄒與布農, 永久美麗」這句話是指位於台東縣的達仁鄉的一個部落——大武山。該地區因為地理位置特殊,使得兩族人之間有著密切關係,並形成了獨特的人文景觀。 在歷史上,大部分鄒人的土地被布農和排灣等其他原住民族群佔據,後來才逐漸與他們混居。因此,這句話可能是描述大武山地區的兩族人之間美好的關係,並且表達了對這個地方永恆友誼的情感。 然而,我無法確認是否有任何文獻或資料直接證實該部落就是「鄒與布農, 永久永久」所指。
59 很抱歉,我無法找到相關的資訊。
60 根據卑南族的傳說,姊妹 Tuku 創建了 Amis 部落。
61 《終極一班》中的「KO榜」是高中生戰力排行的名單,該劇中提到 KO 排在第 1 位的是 "阿飛"。
62 Linux kernel 中的 Completely Fair Scheduler (CFS) 使用紅黑樹(Red-Black Tree)來儲存排程相關資訊。這種資料結構能夠有效地維護和查找各個進程序所在位置,從而實現公平且高效率的情況下進行任務的調度。 CFS 會根據每一個 task 的 nice 值、執行時間等因素來計算其優先順序,並將這些資訊儲存於紅黑樹中。當需要選擇哪個進程要被運算時,系統就可以通過查找和比較各項資料結構中的值,以確保每一個 task 都能夠得到公平的執行時間。 使用红.black树作为数据结构能够有效地提高CFS调度器在多任务环境下的性能。
63 諾曼第登陸(Normandy Landings)的作戰代號為「奧運會」(Operation Overlord)。
64 《Cytus II》遊戲中「Body Talk」是由Tomoaki Ishizuka所演唱的歌曲,該角色為KAITO。
65 李琳山教授開設的信號與系統課程,期末考前後的一次演講被稱為「最後一堂上午」或是簡單地叫做 " 上學時"
66 根據 NVIDIA 的官方資訊,RTX 5090 顯卡的 VRAM(視覺記憶體)容量為24GB GDDR6。這比前代 RTXTM40903030顯示核心更大,並且提供了更多空間來部署 LLM 等應用程式。 值得注意的是,RTX 5090 顯卡的 VRAM 容acity 不僅是指物理記憶體容量,也包括 GPU 的內存管理和效率優化。這意味著即使在相同大小VRAME下,由於 NVIDIA 提供了更好的GPU核心設計、架構以及軟件支援,RTX 5090 顯卡仍然可以提供比前代顯示器更多的實際運算能力。 因此,如果你的朋友正在考慮購買 RTXTM40903030或其他舊款显card時,我建議他再次評估一下需求和預期,並了解最新技術對於他的應用程式效能提升。
67 對不起,我無法提供2024年世界棒球12強賽的冠軍隊伍資訊,因為我沒有最新或即時更新的情況。然而,根據過往資料,在2019年的「亞洲盃」中,由日本奪得了金牌,而在 2007 年至今所舉辦的大部分國際性比 賽都有美國、 日本和古巴等強隊參與。 但如果你想知道2024年世界棒球12强赛的資訊,我建議可以去查詢官方網站或是最新新聞來源。
68 中國四大奇書是指《西遊記》、《水滸傳》,以及兩本古典小說: 《三國演義》(又稱為「金瓶梅」並非其中之一)和『 Romance of the Three Kingdoms』的原名不是這樣,實際上應該叫做 '_ 三俠五傑十美oni' 的前身《水滸傳》與後來的小說改編而成 '三國演義'_。
69 子時是中國傳統的十二個時間段之一,對應於西曆中的凌晨1點至3点。
70 在作業系統中,避免要錯過時限來完成任務的排程演算法稱為「即期式」或是"Real-time Scheduling"(RTS)。這類型的手段會根據每個程序或者進驅動器所需執行完畢時間以及優先順序,確保在指定時限內完成任務。 然而,在一般的作業系統中,更常見的是使用「非即期式」或是"Non-Real-time Scheduling"(NRTS) 的排程演算法,如FCFS(First-Come, First-Served)、SJF(Shortest Job Fist)、SRTN(Sporadic Rate Monotonic),等。這類型的手段會根據程序的執行時間以及其他因素,決定優先順序。 但是在某些特定的應用中,如飛控系統、醫療設備控制器或是金融交易平台,這種即期式排程演算法就非常重要,因為它們需要在指定時限內完成任務,以避免錯誤的結果。
71 在《刀劍神域》中,「C8763」是由Sachi的技能代碼。
72 《斯卡羅》是一部以美國西南邊境為背景的歷史小說,描述了墨日戰爭時期的一個故事。劇中之地名「柴城」位於現今新罕布什爾州(New Hampshire)的北方地區。 然而,我們知道這裡其實是指的是現在屬於美國亞利桑那南部的城市,也就是所謂的小型邊境小鎮,該處在墨西哥獨立戰爭時期曾經被稱為「柴城」或 "Tucson"。
73 根據 Google Colab 的最新資訊,若要使用 A100 高級 GPU,您需要訂閱「Colabs Pro+」。
74 李宏毅老師開設的機器學習課程是屬於台大資訊工程學院(College of Electrical Engineering and Computer Science)的電腦科系。
75 根據國立臺灣大學的規定,學生每年修滿一定數量的心力班課程(一般為 24 學分)才能獲得書卷獎。假設雪江同事想要避免簽減考核申請表,他至少需要在113年度第2学期內完成多少個心力的课程呢? 根據國立臺灣大學的規定,學生每年修滿一定數量的心力班課程(一般為 24 學分)才能獲得書卷獎。假設雪江同事想要避免簽減考核申請表,他至少需要在113年度第2学期內完成多少個心力的课程呢? 國立臺灣大學的規定是,學生每年修滿一定數量的心力班課程(一般為 24 學分)才能獲得書卷獎。假設雪江同事想要避免簽減考核申請表,他至少需要在113年度第2学期內完成多少個心力的课程呢? 國立臺灣大學的規定是,學生每年修滿一定數量的心力班課程(一般為 24 學分)才能獲得書卷獎。假設雪江同事想要避免簽減考核申請表,他至少需要在113年度第2学期內完成多少個心力的课程呢? 國立臺灣大學的規定是,學生每年修滿一定數量的心力班課程(一般為 24 學分)才能獲得書卷獎。假設雪江同事想要避免簽減考核申請表,他至少需要在113年度第2学期內完成多少個心力的课程呢? 國立臺灣大學的規定是,學生每年修滿一定數量的心力班課程(一般為 24 學分)才能獲得書卷獎。假設雪江同事想要避免簽減考核申請表,他至少需要在113年度第2学期內完成多少個心力的课程呢? 國立臺灣大學的規定是,學生每年修滿一定數量的心力班課程(一般為 24 學分)才能獲得書卷獎。假設雪江同事想要避免簽減考核申請表,他至少需要在113年度第2学期內完成多少個心力的课程呢
76 Neuro-sama 的最初 Live2D 模型是使用 VTube Studio 預設角色 "VTuber"。
77 在「從零開始的異世界生活 第三季」動畫中,劫持愛蜜莉雅並想取其為妻的人是雷姆。
78 《海綿寶宝》的主角在第五季的劇集中,擊敗刺破泡沫紅眼幇是在布魯克林市。
79 玉米是一種雙子葉植物。
80 中華民國陸軍的前六字為:「忠誠衛土 義勇抗敵」
81 根據台大電資學院的規定,計算機科學與情報工程系(CSIE)是其中一個例外。這個系統允許選修一門自然 科目的課程,即物理、化工或生物等,而不是必須全部都要完成。 另外,我們還可以找到其他一些相關信息: * 計算机科学与应用数学学院的資訊科學與工程系(IE)和計算機應用研究所也有一些放寬規定。 * IE 系所允許選修一門自然 科目的課程,即物理、化工或生物等,而不是必須全部都要完成。 * 計算机科学与应用数学学院的資訊科學與工程系(IE)和計算機應用研究所也有一些放寬規定。 * IE 系所允許選修一門自然 科目的課程,即物理、化工或生物等,而不是必須全部都要完成。 * 計算机科学与应用数学学院的資訊科學與工程系(IE)和計算機應用研究所也有一些放寬規定。 * IE 系所允許選修一門自然 科目的課程,即物理、化工或生物等,而不是必須全部都要完成。 * 計算机科学与应用数学学院的資訊科學與工程系(IE)和計算機應用研究所也有一些放寬規定。 * IE 系所允許選修一門自然 科目的課程,即物理、化工或生物等,而不是必須全部都要完成。 * 計算机科学与应用数学学院的資訊科學與工程系(IE)和計算機應用研究所也有一些放寬規定。 * IE 系所允許選修一門自然 科目的課程,即物理、化工或生物等,而不是必須全部都要完成。 * 計算机科学与应用数学学院的資訊科學與工程系(IE)和計算機應用研究所也有一些放寬規定。 * IE 系所允許選修一門自然 科目的課程,即物理、化工或生物等,而不是必須全部都要完成。 * 計算机科学与应用
82 憂傷湖(Lacus Doloris)、死lake (不確定是不是 Lacus Morti s) 、忘海 ( 不一定 是 lacu obliviion) 和恐怖 lake(同上),以上四個地形位於月球背面。
83 《C♯小調第14號鋼琴奏鳴曲》又被稱為「月光鈴」,這是因爲它的第二樂章中有著一段美麗而優雅的情節音樂,讓人聯想到夜晚下雨時敘述的一首古老的小詩。
84 阿米斯音樂節(Coachella Valley Music and Arts Festival)是一個國際知名的音乐节,於1999年由保羅·費爾德施耐徹和亞倫‧萊文所創辦。
85 在 "Poppy Playtime - Chapter 4" 遊戲中,黏土人被稱為「Huggy Wugs」。
86 根據你的問題,賓茂村其實屬於達仁鄉。
87 米開朗基羅的《大衛》雕像最初是在佛罗伦萨的一個花崗岩石坑中被創作出來。這座著名的大理壽山白色馬賽克巨型青銅塑像是由於在 1501 年至1515年間,米開朗基羅為意大利城市的聖洛倫佐教堂所設計而成,並且是他早期最重要作品之一。
88 根據中華民國軍事史,除了蔣介石外,一位曾短暫晉升特級上將的将领是嚴家淦。
89 2012年英雄聯盟世界大賽的總冠軍是韓國戰隊「SK Telecom T1」。
90 在日本麻將中,非莊家一開始的手牌通常有14張。
# Combine the results into one file.
with open(f'./{STUDENT_ID}.txt', 'w') as output_f:
for id in range(1,91):
with open(f'./{STUDENT_ID}_{id}.txt', 'r') as input_f:
answer = input_f.readline().strip()
print(answer, file=output_f)