最近在做agent的工作,一篇对agent技术深入浅出的博文https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-llm-agents,写的很棒,特地翻译下。
正文
LLM agent正变得越来越普遍,似乎正在取代我们熟悉的“常规”对话式 LLM。这些令人难以置信的功能并不容易实现,需要许多组件协同工作。
通过这篇文章中的 60 多个自定义视觉效果,您将探索 LLM agent领域及其主要组件,并探索多agent框架。
感谢您阅读《探索语言模型》!订阅即可收到有关Gen AI和《动手操作大型语言模型》一书的新帖子
订阅
👈 点击左侧的行堆栈以查看目录(ToC)
什么是 LLM agent?
要了解什么是 LLM agent,我们首先来了解一下 LLM 的基本功能。传统上,LLM 的作用无非是预测下一个 token。
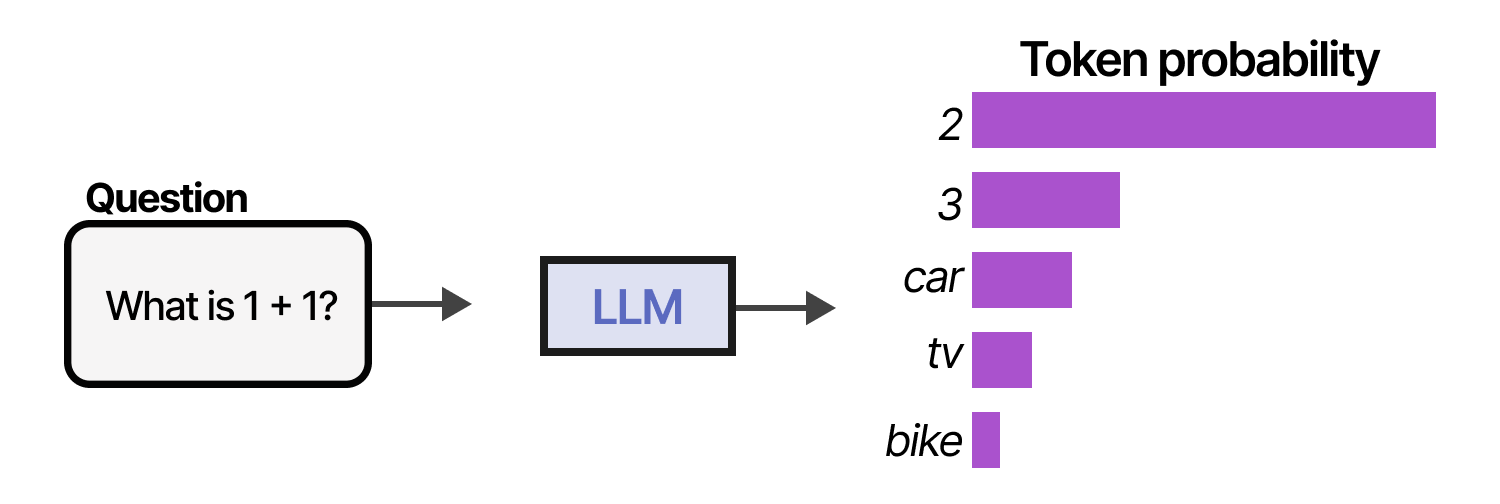
通过连续采样许多标记,我们可以模拟对话并使用 LLM 为我们的查询提供更广泛的答案。

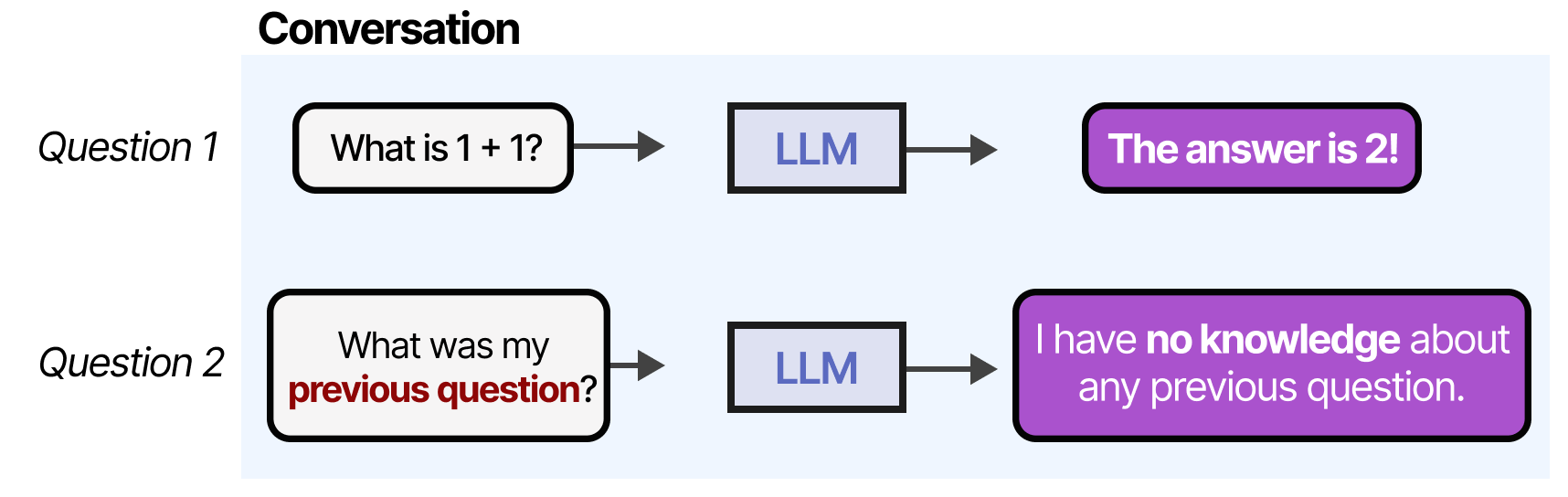
然而,当我们继续“对话”时,任何 LLM 都会暴露出它的一个主要缺点:它不记得对话!
LLM 经常在许多其他任务上失败,包括乘法和除法等基本数学运算:
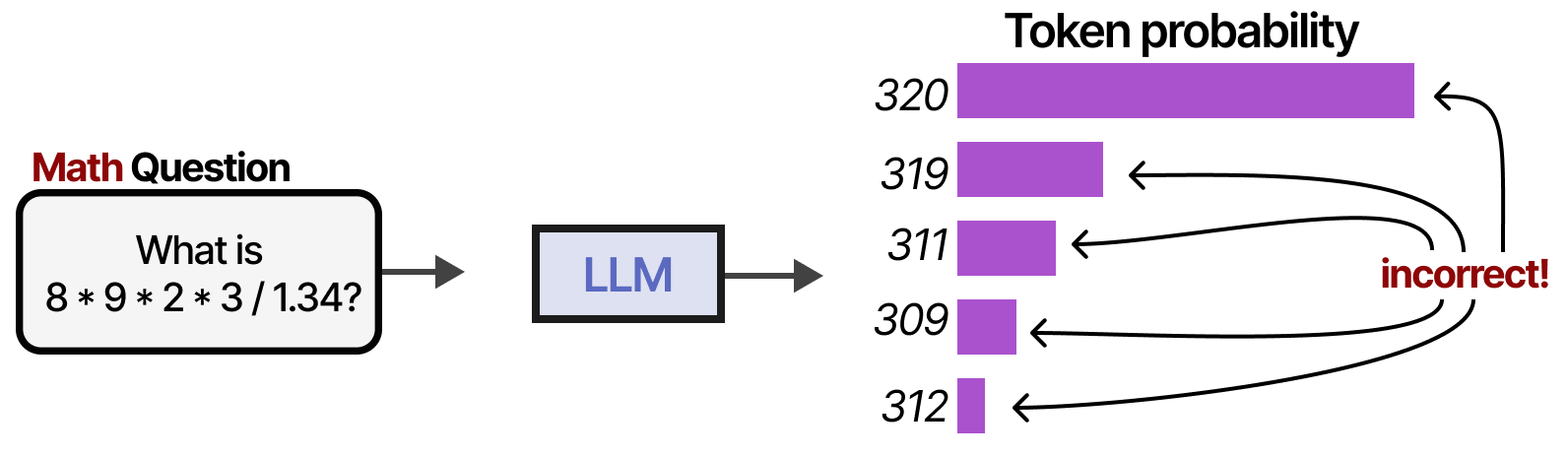
这是否意味着 LLM 很糟糕?绝对不是!LLM 没有必要面面俱到,我们可以通过外部工具、记忆和检索系统来弥补其劣势。
通过外部系统,LLM的能力可以得到增强。Anthropic 称之为“增强型LLM”。
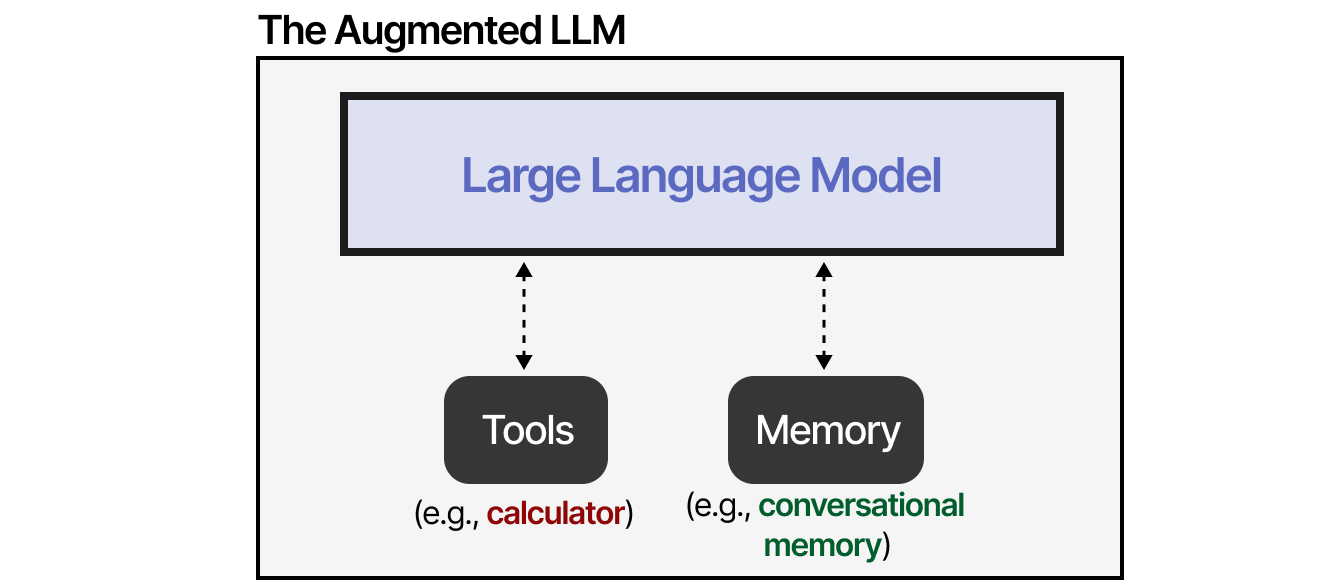
例如,当面对数学问题时,LLM可能会决定使用适当的工具(计算器)。
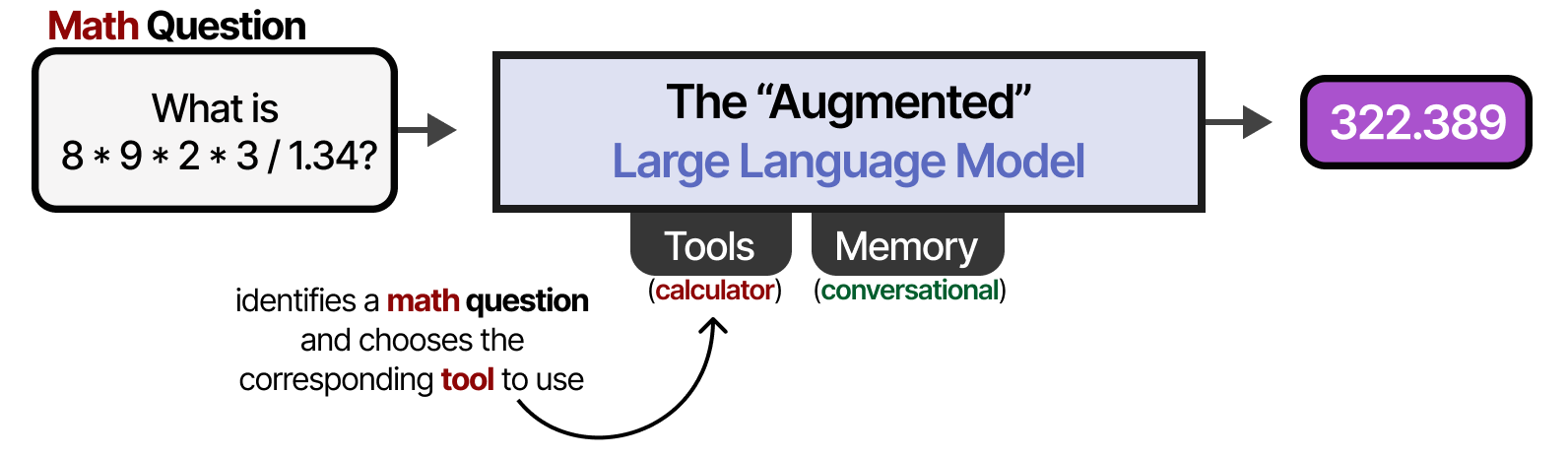
那么这个“增强型LLM”是agent人吗?不,也许有点是……
让我们首先来定义一下agent:1
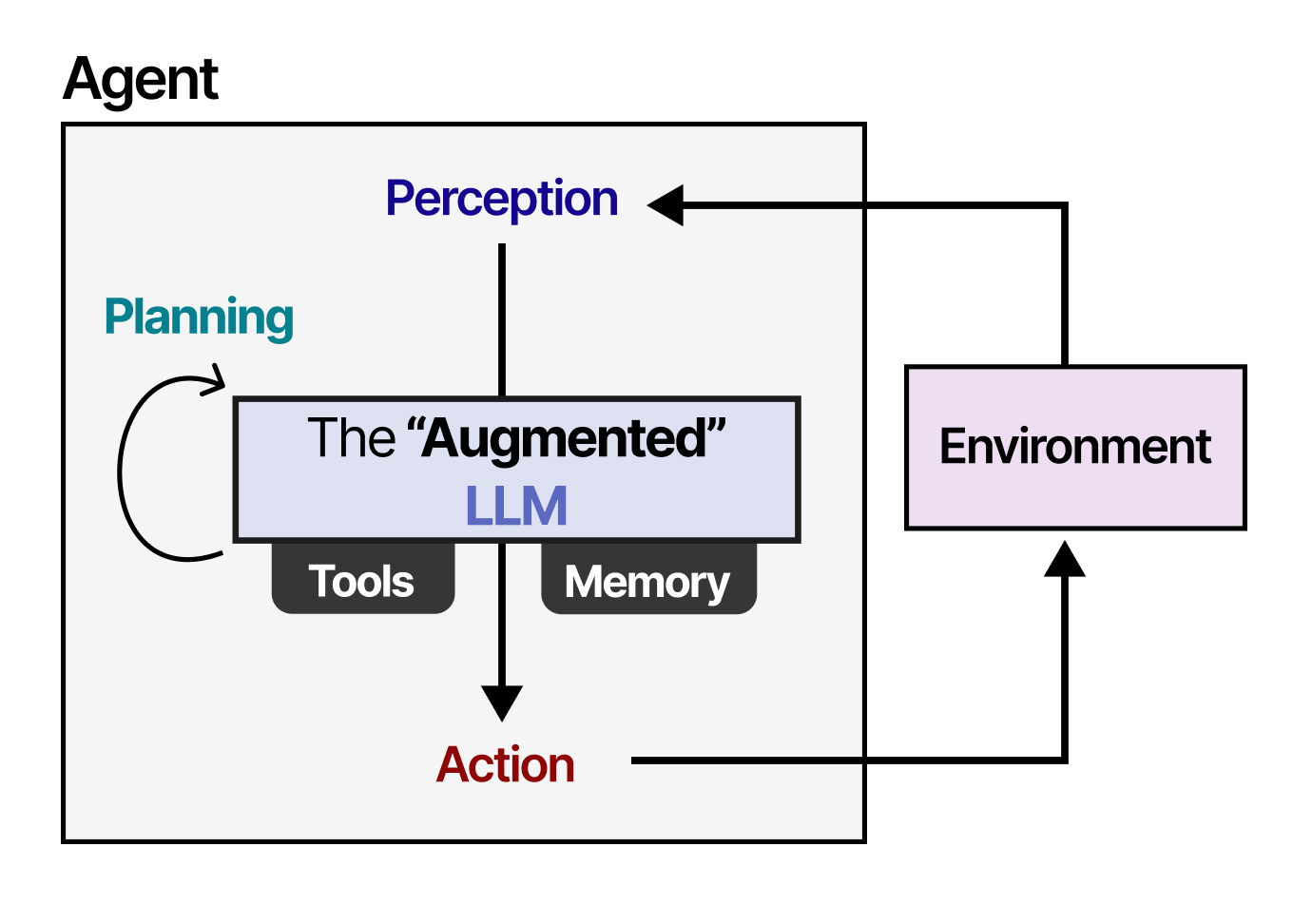
agent是指任何可以通过传感器感知环境并通过执行器对环境采取行动的事物。
—— Russell 和 Norvig, 《人工智能:一种现代方法》(2016 年)
agent与其环境交互,通常由几个重要组件组成:
- Environments——agent与之交互的世界
- Sensors——用于观察环境
- Actuators ——用于与环境交互的工具
- Effectors——决定如何从观察到行动的“大脑”或规则
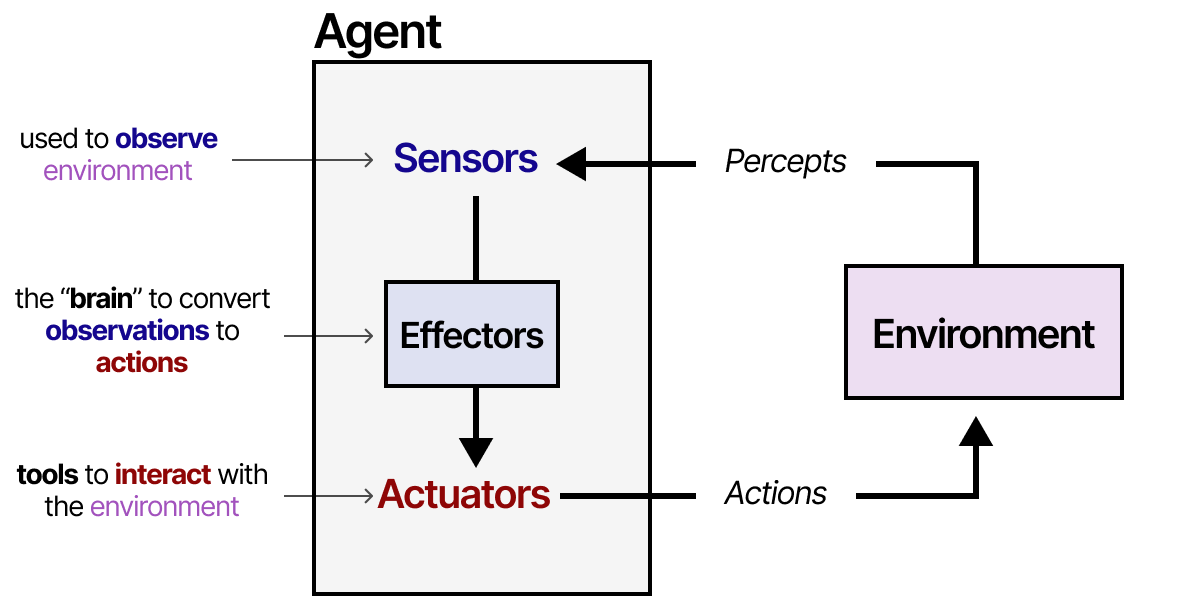
该框架用于与各种环境交互的各种agent,如机器人与其物理环境交互或人工智能agent与软件交互。
我们可以稍微概括一下这个框架,使其适合“增强型 LLM”。
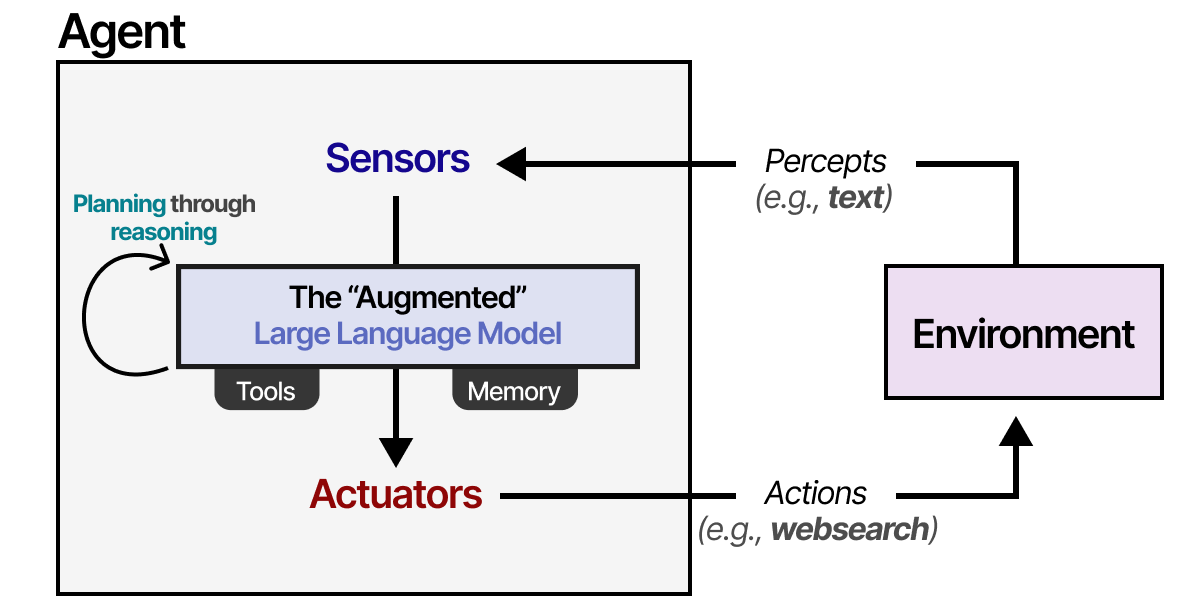
使用“增强型” LLM,agent可以通过文本输入观察环境(因为 LLM 通常是文本模型)并通过使用工具执行某些操作(例如搜索网络)。
为了选择要采取哪些行动,LLM agent有一个至关重要的组成部分:规划能力。为此,LLM 需要能够通过思路链等方法进行“推理”和“思考”。
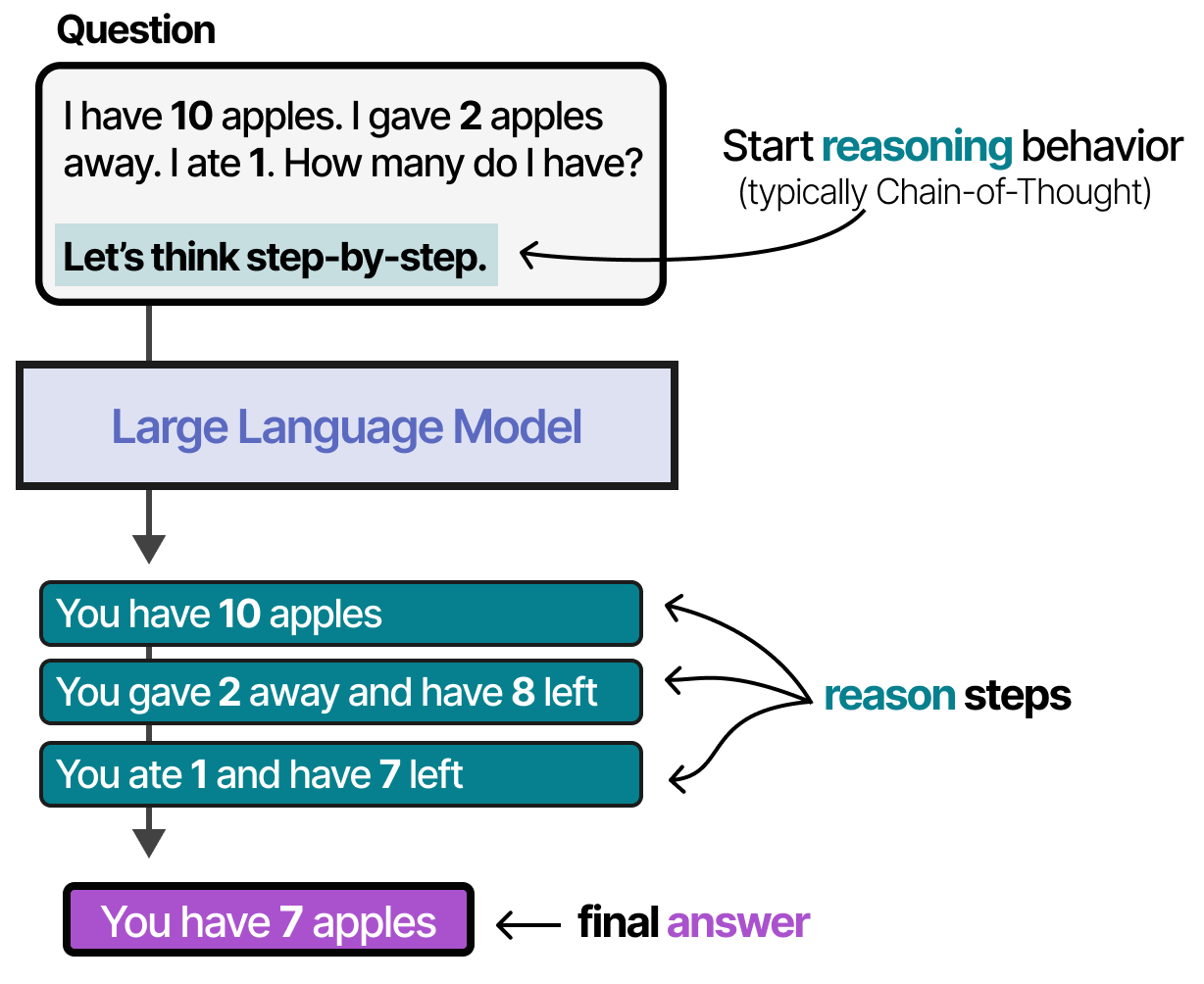
有关推理的更多信息,请参阅《推理 LLM 视觉指南》
利用这种推理行为,LLM agent将规划出需要采取的必要行动。
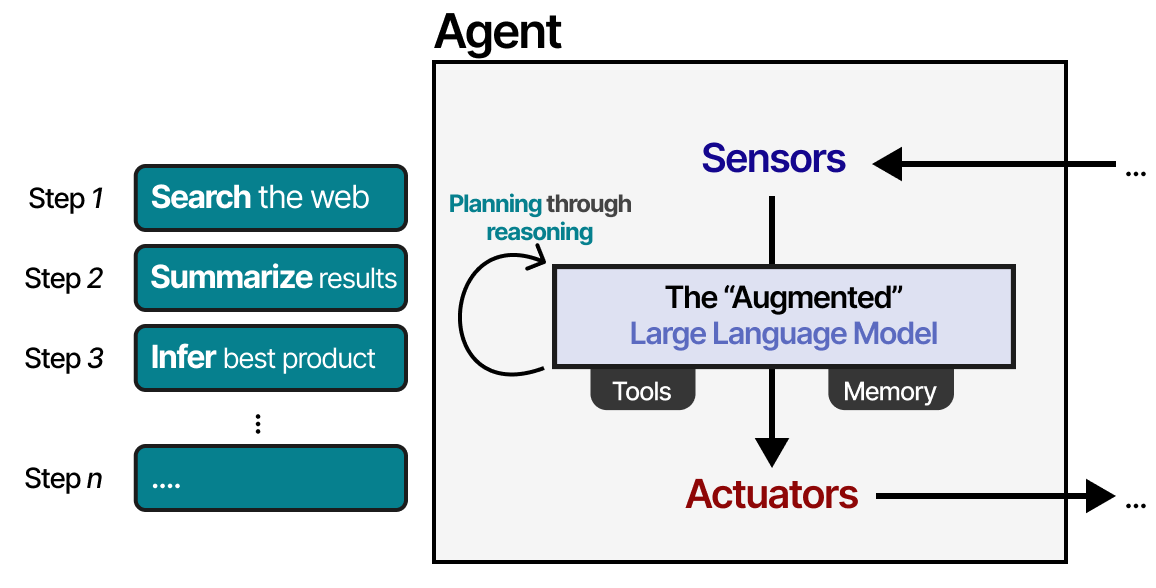
这种规划行为使agent能够了解情况(LLM )、规划下一步(规划)、采取行动(工具)并跟踪已采取的行动(记忆)。
根据系统不同,您可以拥有不同程度的自主权的 LLM agent。
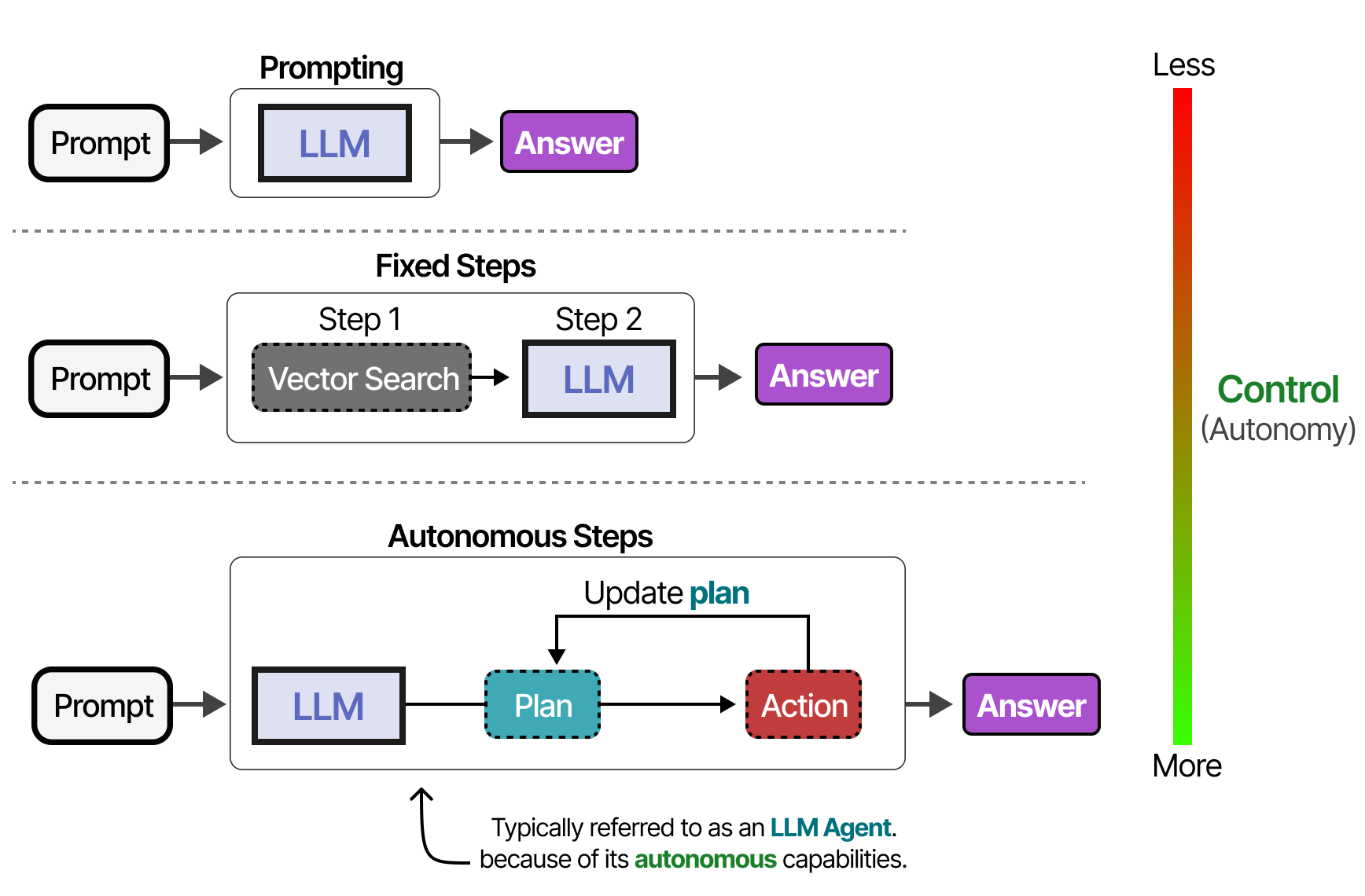
取决于你问谁,系统越“agent”,LLM 就越多地决定系统如何运行。
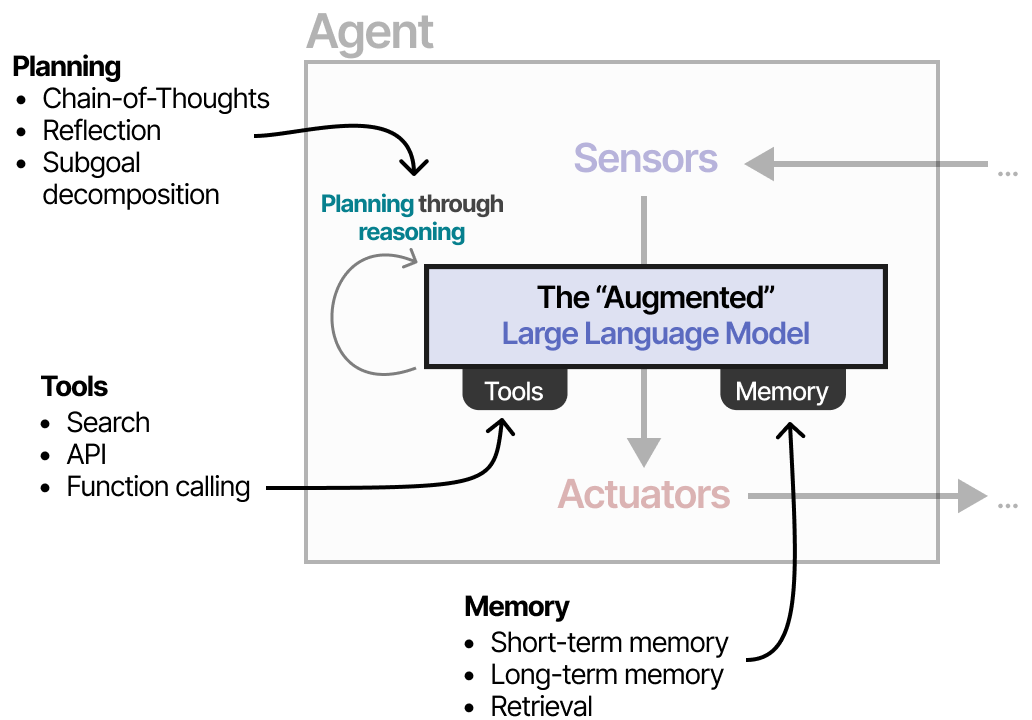
在接下来的部分中,我们将通过 LLM Agent 的三个主要组件:内存、工具和规划,介绍自主行为的各种方法。
记忆
LLM 是易遗忘的系统,或者更准确地说,在与它们交互时根本不进行任何记忆。
例如,当你向LLM (LLM) 提出一个问题,然后又提出另一个问题时,它不会记住前者。
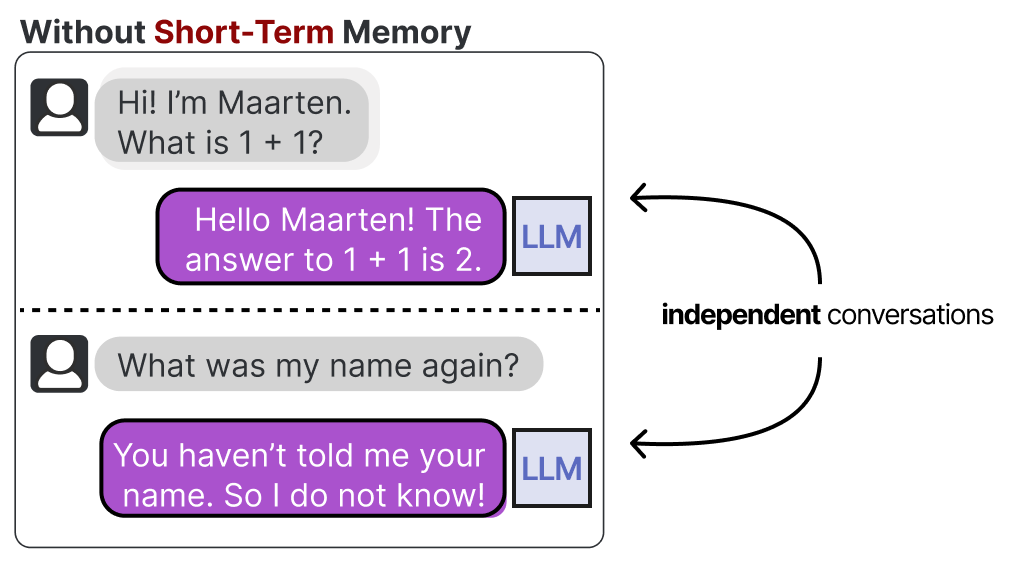
我们通常将其称为短期记忆,也称为工作记忆,它充当(近)即时上下文的缓冲。这包括 LLM agent最近采取的行动。
然而,LLM agent还需要跟踪可能数十个步骤,而不仅仅是最近的操作。
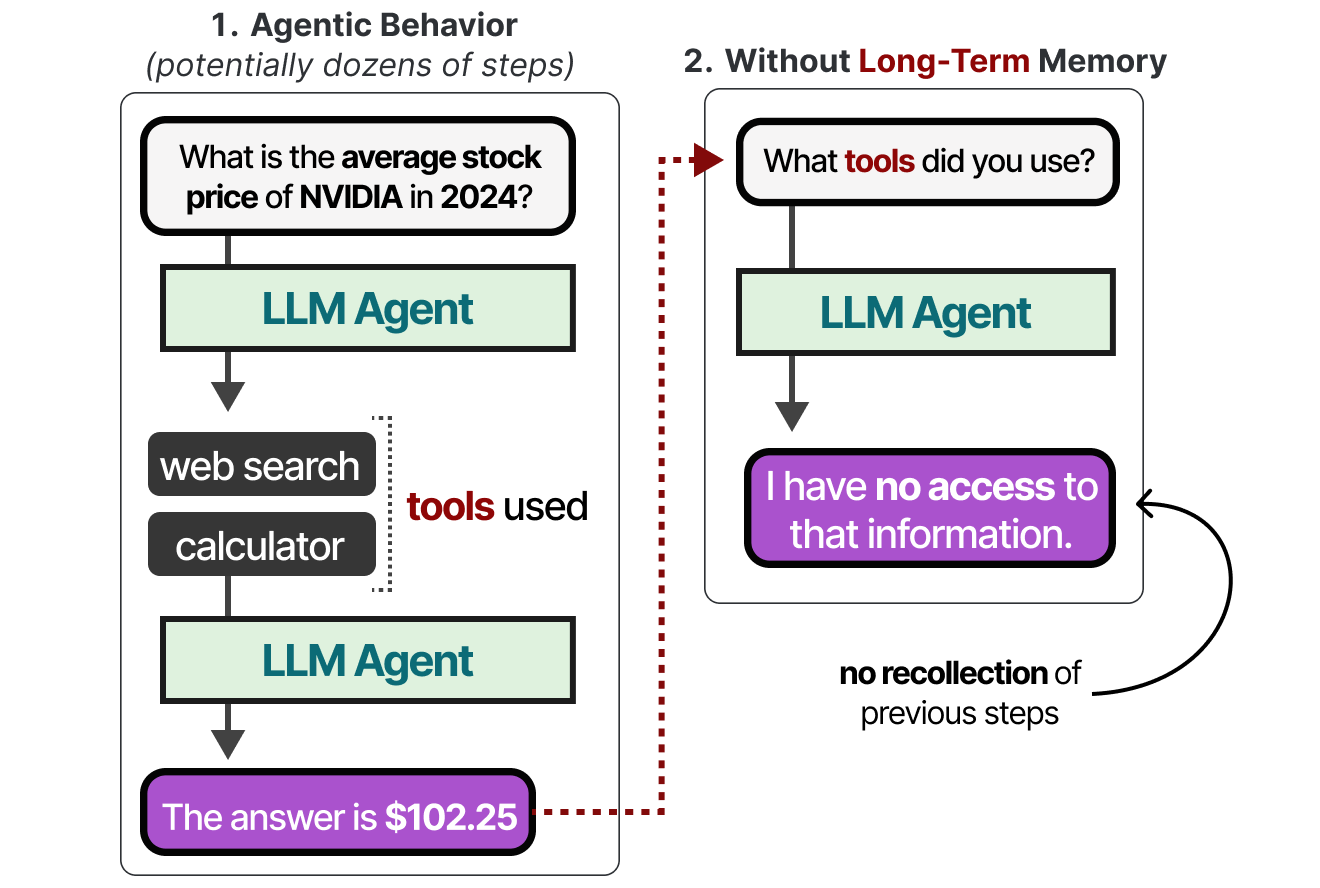
这被称为长期记忆,因为 LLM agent理论上可以记住数十个甚至数百个需要记住的步骤。
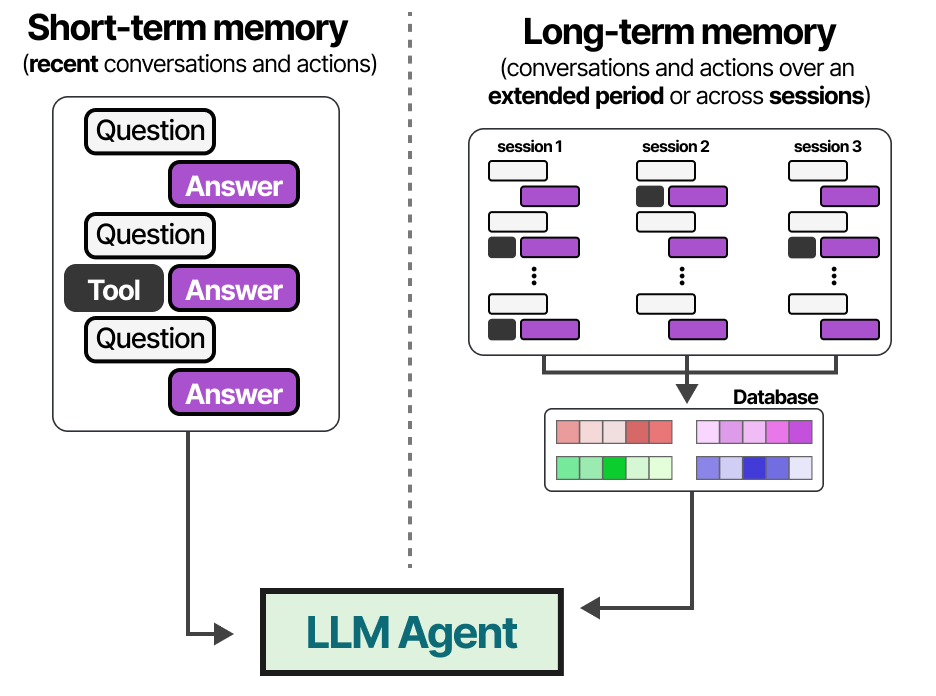
让我们探索一下为这些模型提供记忆的几种技巧。
短期记忆
实现短期记忆的最直接方法是使用模型的上下文窗口,它本质上是 LLM 可以处理的标记数。
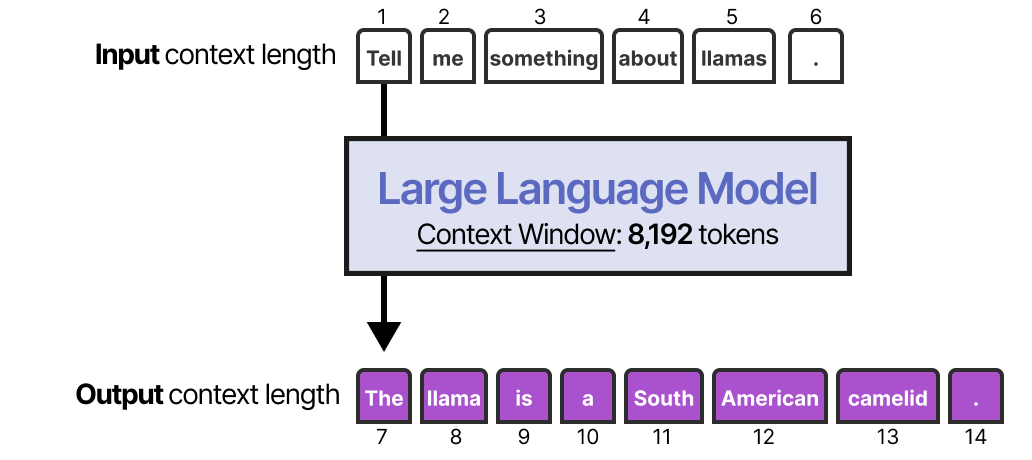
上下文窗口往往至少有 8192 个标记,有时可以扩展到数十万个标记!
可以使用大型上下文窗口来跟踪完整的对话历史记录作为输入提示的一部分。
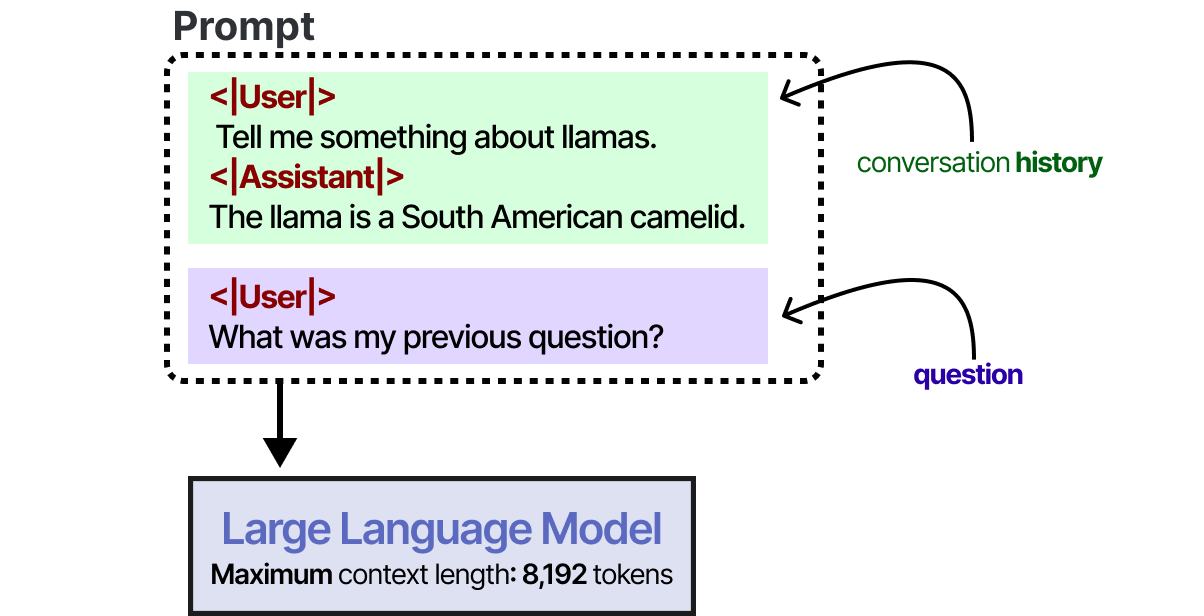
只要对话历史符合 LLM 的上下文窗口,这种方法就有效,而且是模仿记忆的好方法。但是,我们实际上不是记住对话,而是“告诉”LLM 那次对话是什么。
对于上下文窗口较小的模型,或者对话历史记录很大时,我们可以使用另一个 LLM 来总结迄今为止发生的对话。
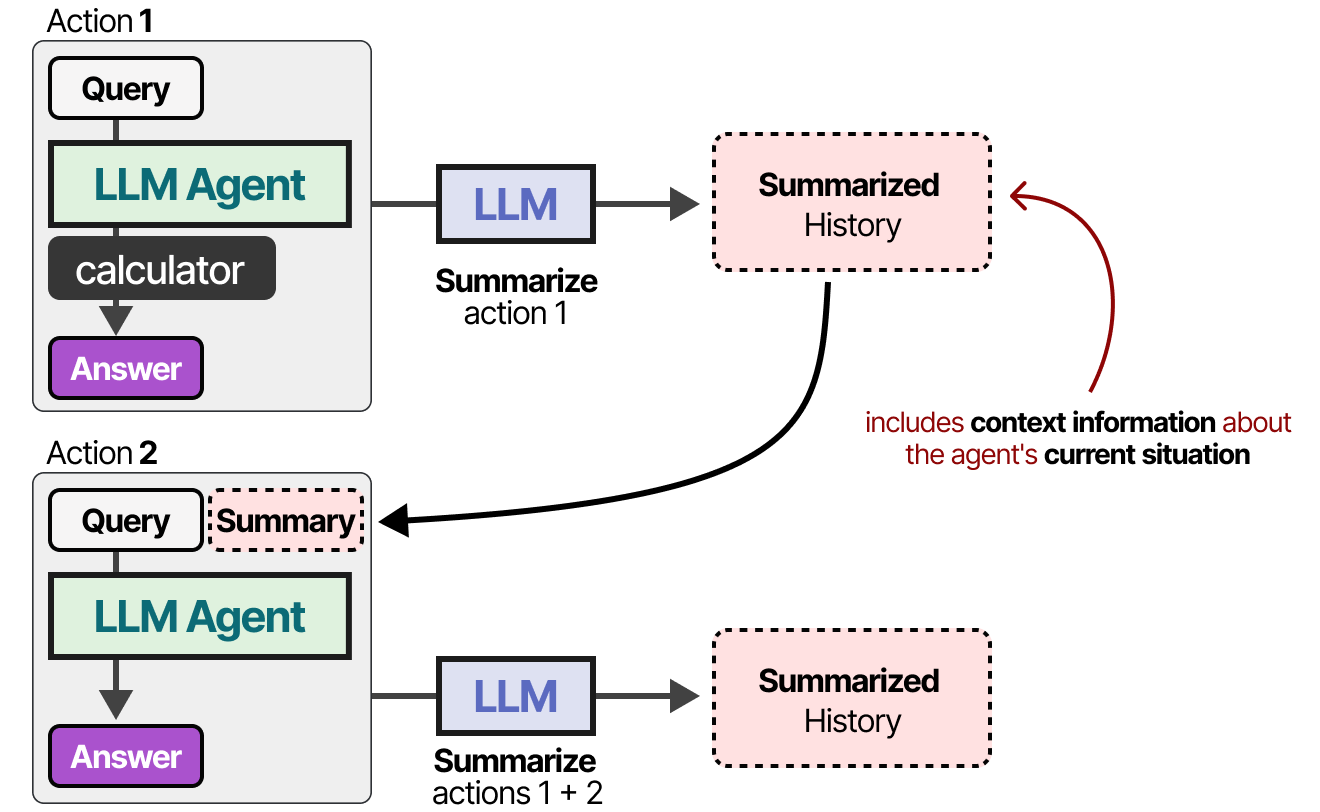
通过不断总结对话,我们可以将对话的规模保持在较小水平。这将减少标记的数量,同时仅跟踪最重要的信息。
长期记忆
LLM agent中的长期记忆包括需要在较长时间内保留的agent过去的动作空间。
实现长期记忆的一种常用技术是将所有以前的交互、操作和对话存储在外部矢量数据库中。
为了建立这样的数据库,首先将对话嵌入到能够捕捉其含义的数字表示中。
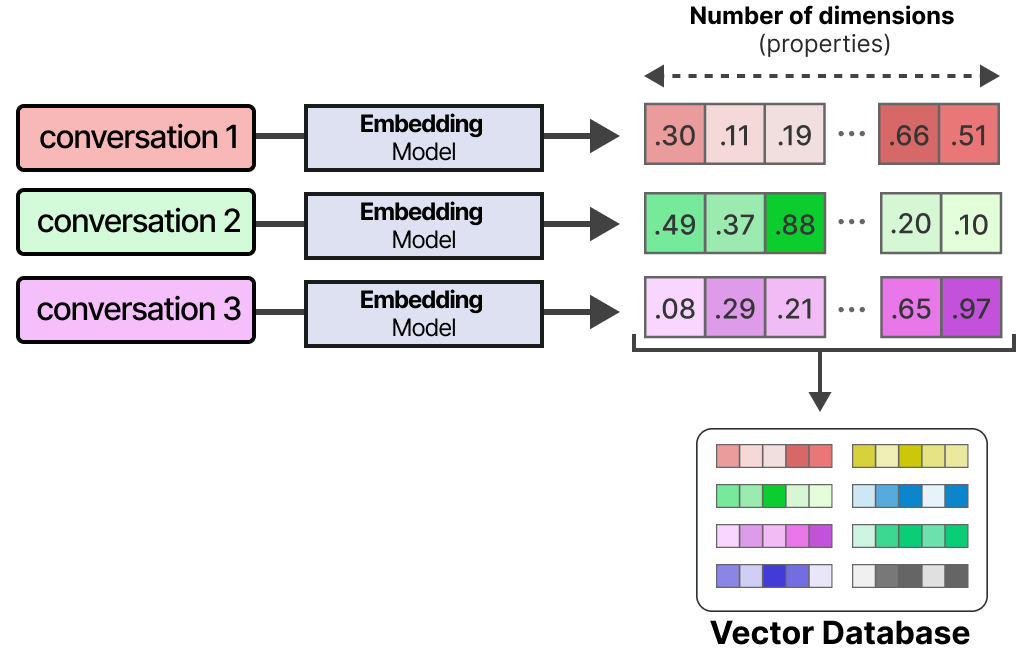
建立数据库后,我们可以嵌入任何给定的提示,并通过将提示嵌入与数据库嵌入进行比较来在向量数据库中找到最相关的信息。
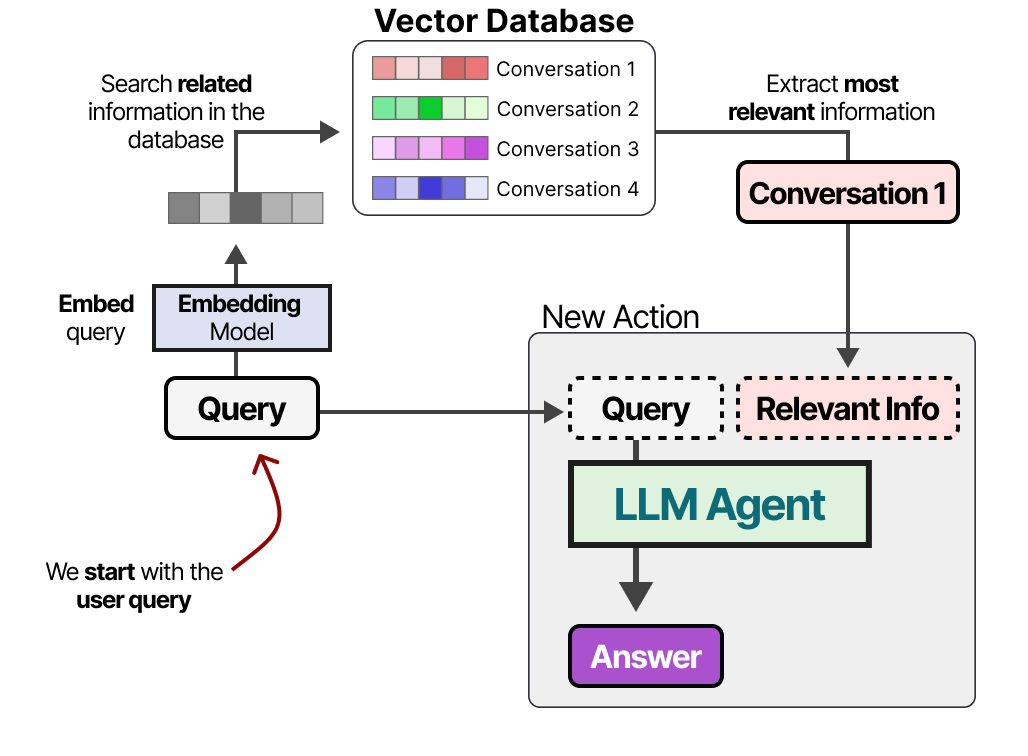
这种方法通常被称为检索增强生成(RAG)。
长期记忆还可能涉及保留来自不同会话的信息。例如,您可能希望 LLM agent记住它在之前的会话中所做的任何研究。
不同类型的信息也可以与要存储的不同类型的记忆相关联。在心理学中,有许多类型的记忆需要区分,但《语言agent的认知架构》论文将其中四种与 LLM agent联系起来。2

这种区分有助于构建agent框架。语义记忆(关于世界的事实)可能存储在与工作记忆(当前和最近的情况)不同的数据库中。
工具
工具允许给定的 LLM 与外部环境(例如数据库)交互或使用外部应用程序(例如运行自定义代码)。

工具通常有两种用例:获取数据以检索最新信息和采取行动,例如安排会议或订购食物。
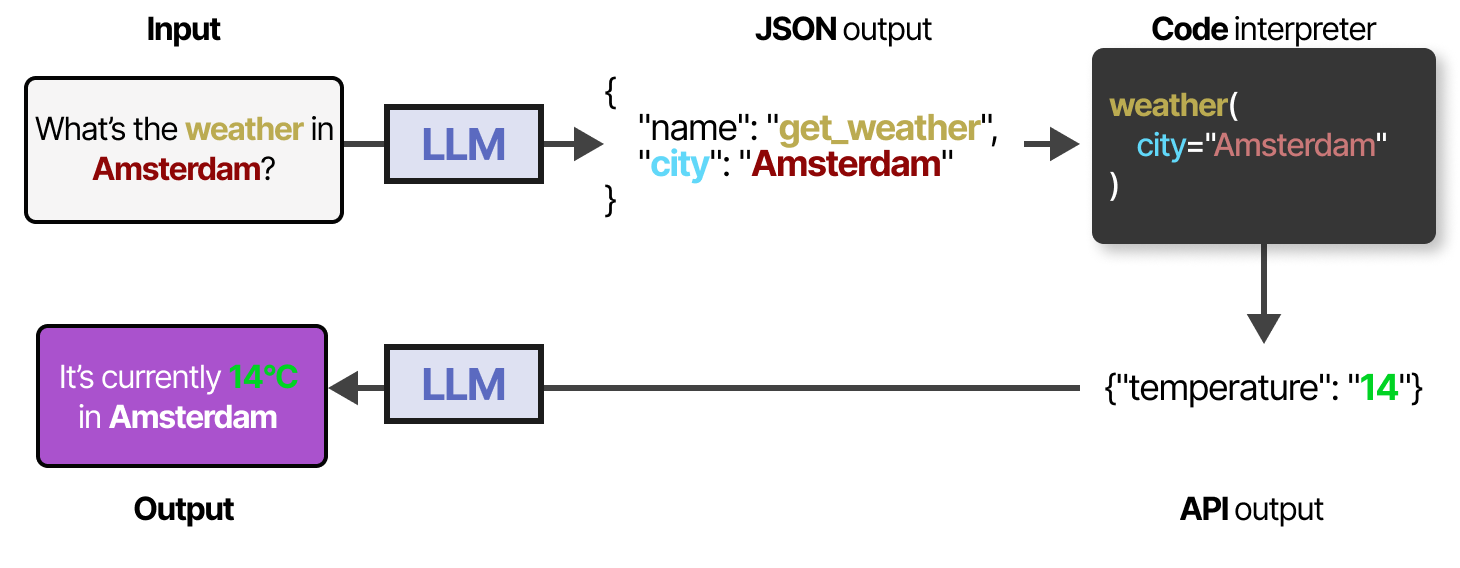
要实际使用工具,LLM 必须生成适合给定工具 API 的文本。我们倾向于期望可以格式化为JSON 的字符串,以便可以轻松地将其输入到代码解释器中。
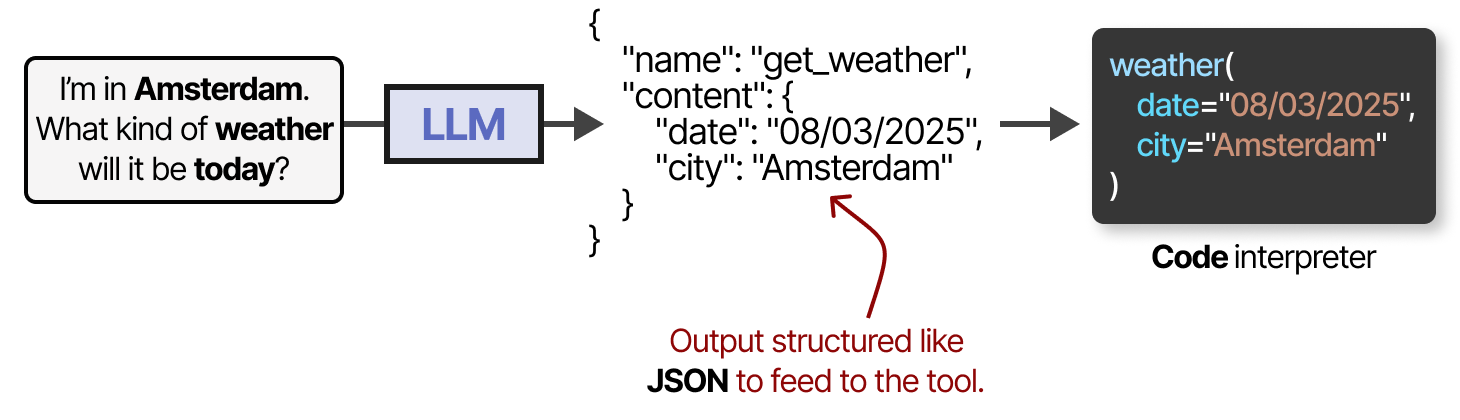
请注意,这不仅限于 JSON,我们还可以在代码本身中调用该工具!
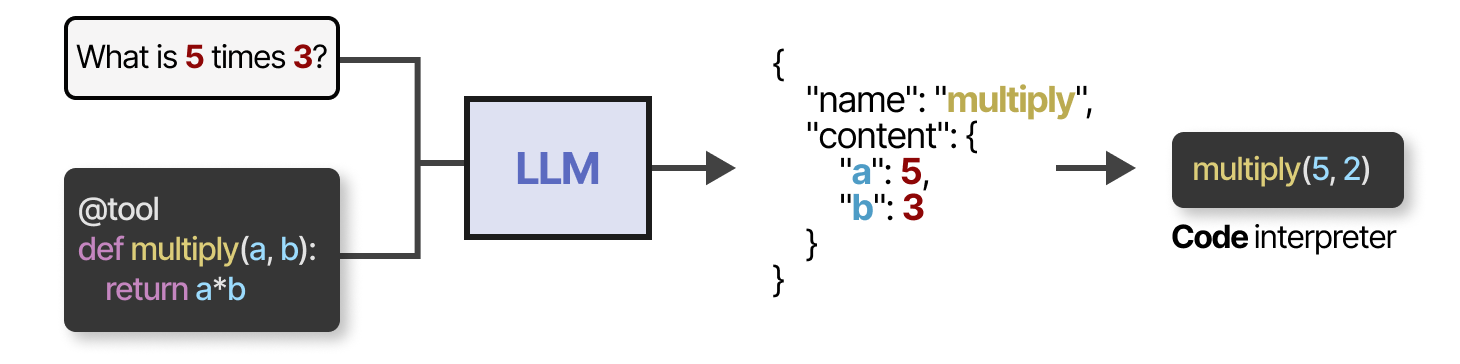
您还可以生成 LLM 可以使用的自定义函数,例如基本乘法函数。这通常称为函数调用。
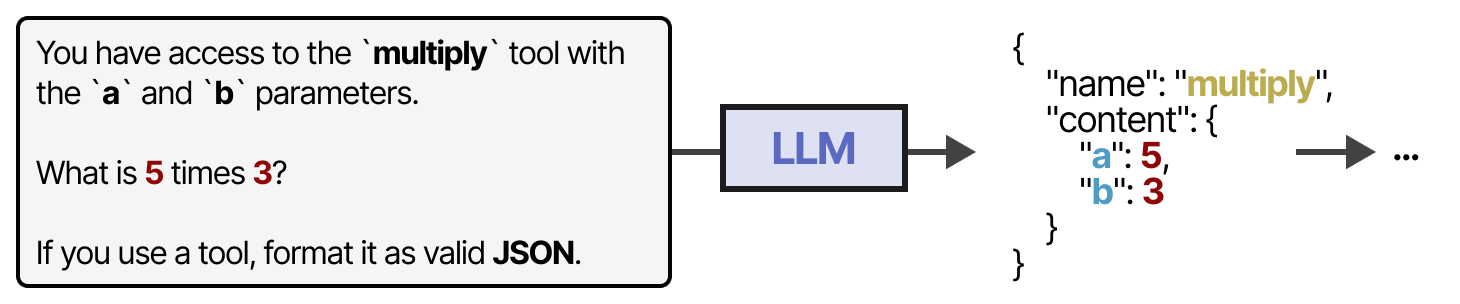
有些 LLM 可以使用任何工具,只要得到正确而广泛的提示即可。工具使用是大多数当前 LLM 都具备的能力。
访问工具的更稳定的方法是通过微调 LLM(稍后会详细介绍!)。
如果agent框架是固定的,那么工具可以按照给定的顺序使用……
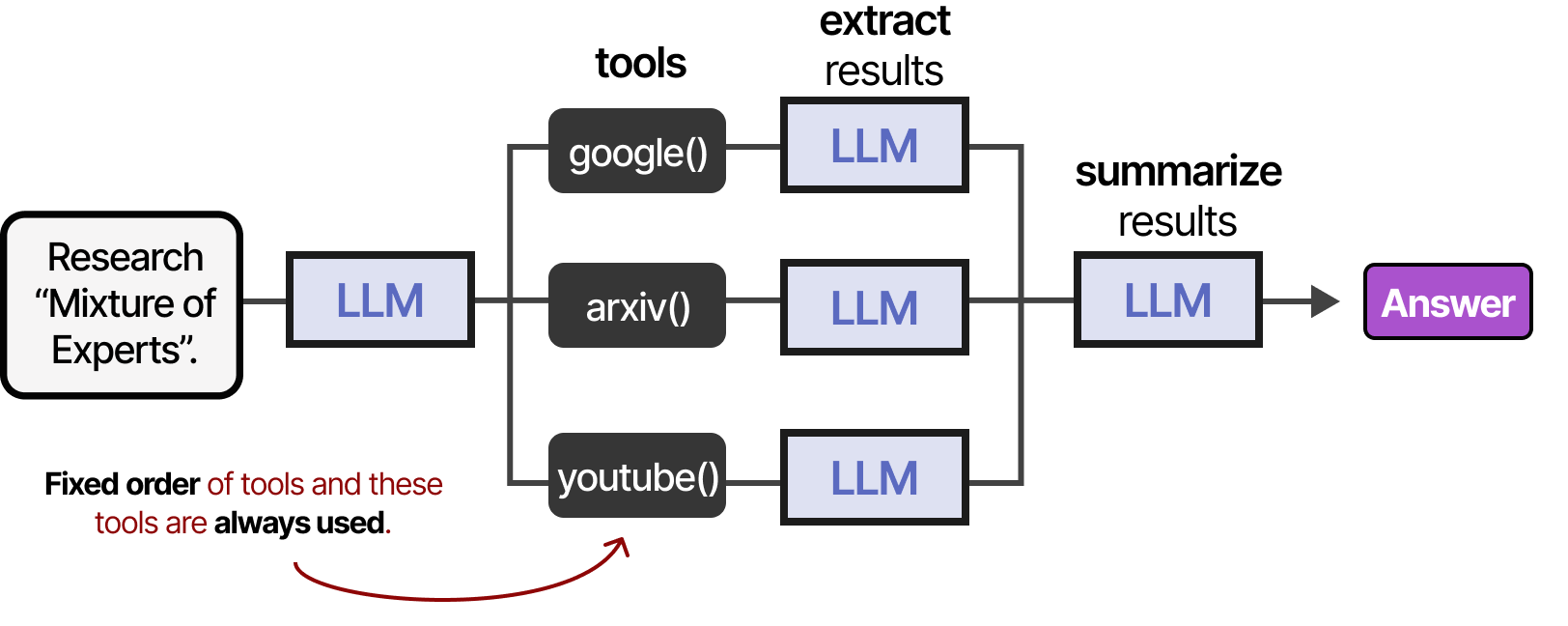
…或者 LLM 可以自主选择使用哪种工具以及何时使用。LLM agent,如上图所示,本质上是 LLM 调用的序列(但可以自主选择操作/工具/等等)。
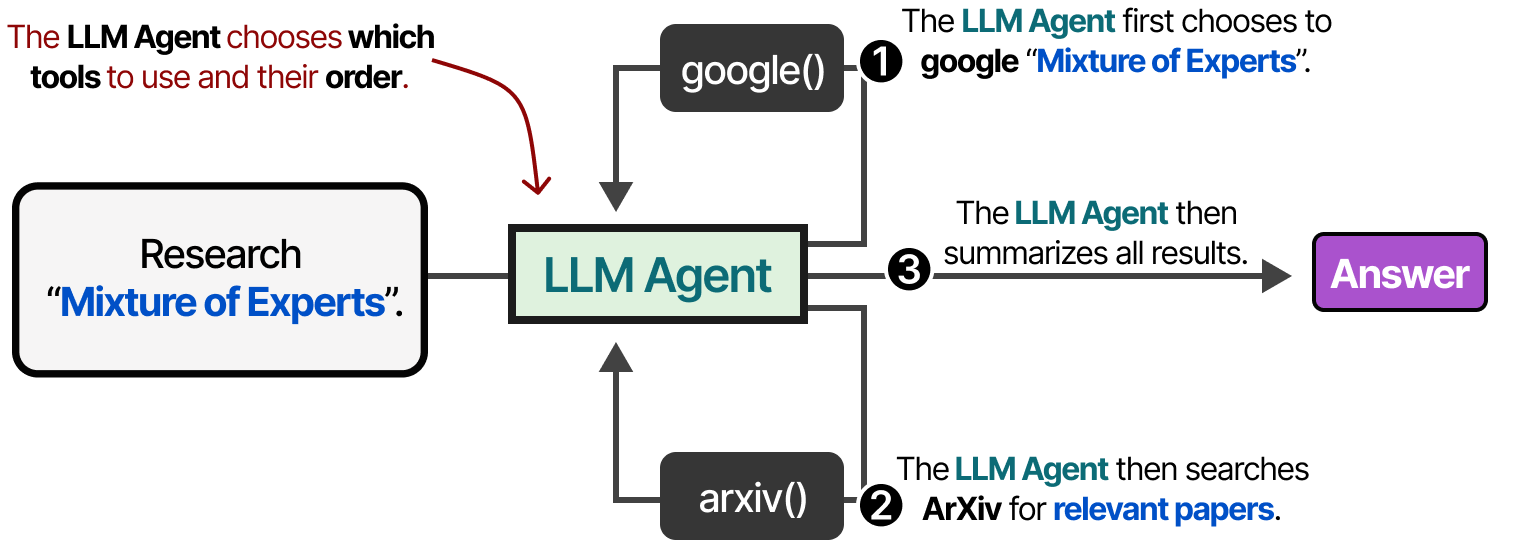
换句话说,中间步骤的输出被反馈到LLM中以继续处理。
Toolformer
工具使用是加强LLM能力和弥补其劣势的有力方法。因此,工具使用和学习方面的研究在过去几年中迅速兴起。
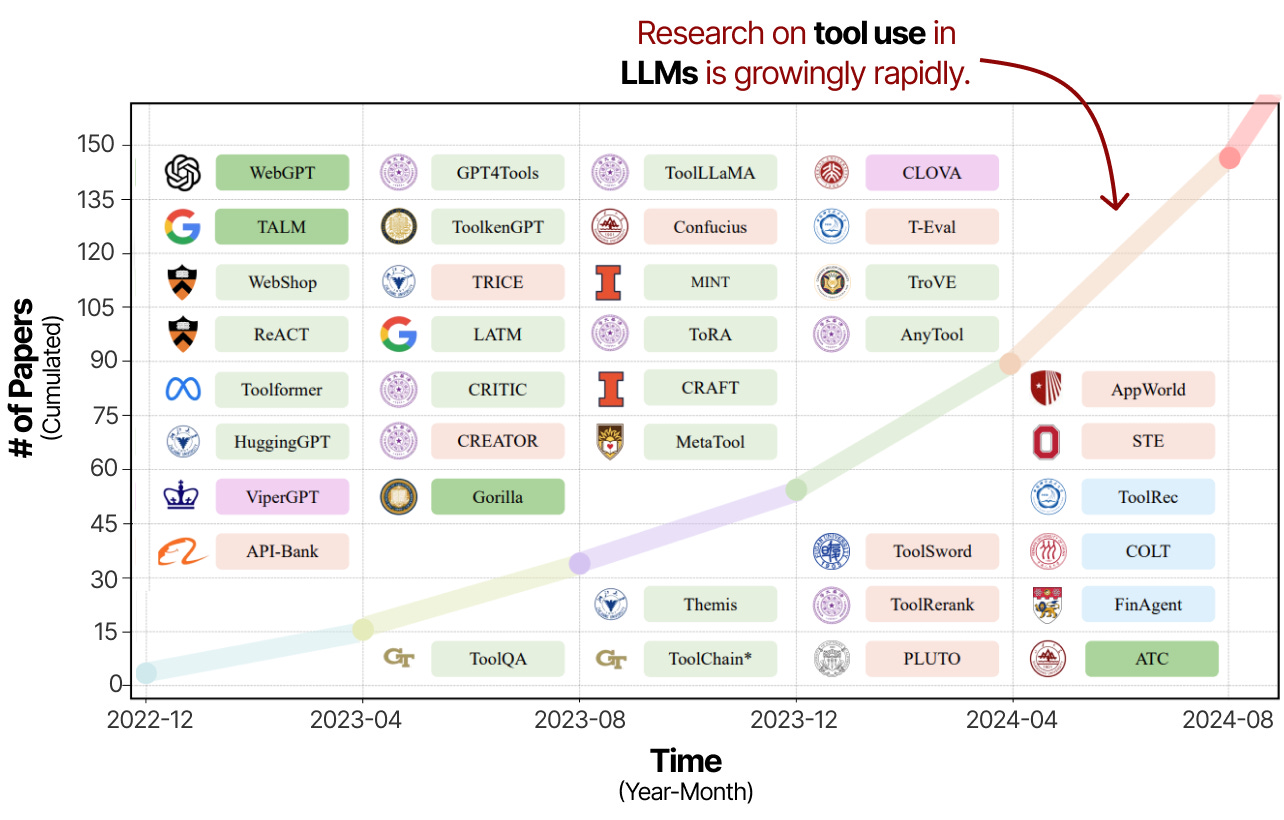
“使用大型语言模型进行工具学习:调查”论文的注释和裁剪图片。随着对工具使用的关注度不断提高,(Agentic)LLM 有望变得更加强大。
这项研究的大部分内容不仅涉及促使LLM使用工具,还涉及对他们进行专门的工具使用培训。
实现这一目标的首批技术之一是 Toolformer,这是一种经过训练的模型,可以决定调用哪些 API 以及如何调用。3
它通过使用 [ 和标记来指示调用工具的开始和结束来实现这一点。当给出提示时,例如“ 5 乘以 3 等于多少?”,它会开始生成标记,直到到达标记。 ] [

此后,它会不断生成令牌,直到到达 → 表示 LLM 停止生成令牌的令牌为止。

然后,将调用该工具,并将输出添加到迄今为止生成的令牌中。
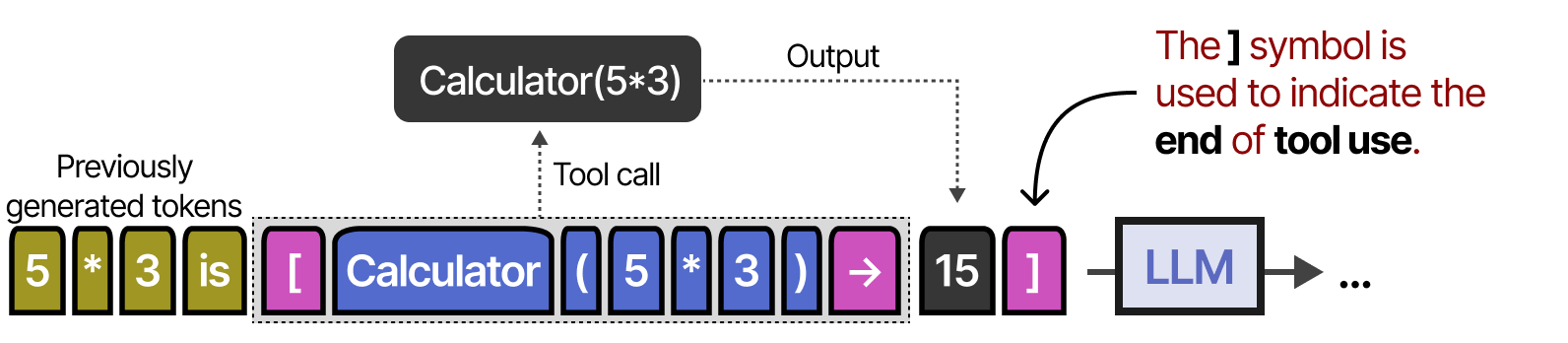
该 ] 符号表示 LLM 现在可以根据需要继续生成。
Toolformer 通过精心生成一个数据集来创建此行为,该数据集包含许多可供模型训练的工具用途。对于每个工具,都会手动创建一个小样本提示,并用于对这些工具的输出进行采样。
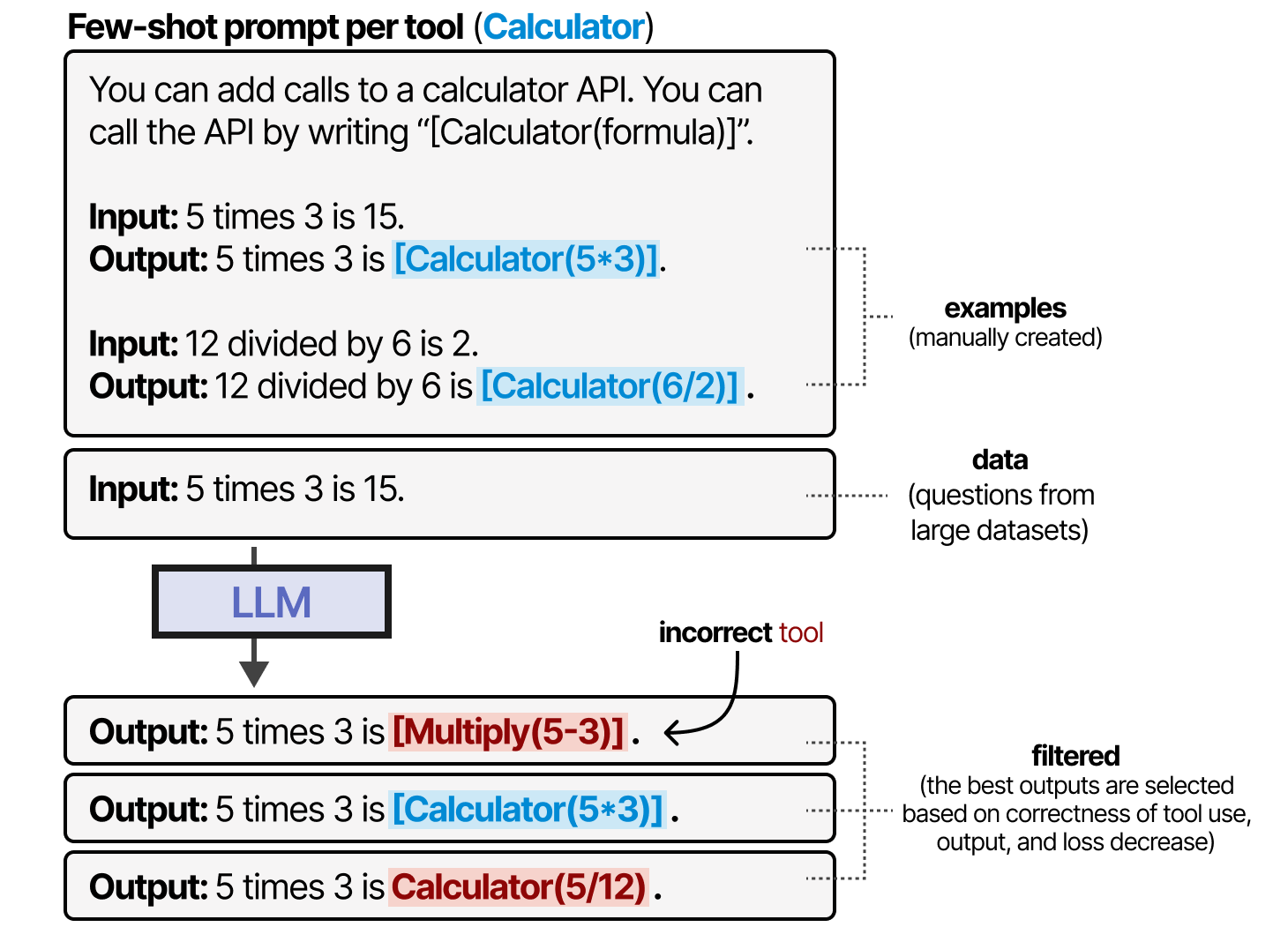
根据工具使用、输出和损失减少的正确性对输出进行过滤。生成的数据集用于训练 LLM 以遵循这种工具使用格式。
自 Toolformer 发布以来,已经出现了许多令人兴奋的技术,例如可以使用数千种工具的 LLM(ToolLLM4)或可以轻松检索最相关工具的 LLM(Gorilla5)。
无论哪种方式,大多数当前的 LLM(2025 年初)都已接受过训练,可以通过 JSON 生成轻松调用工具(如我们之前所见)。
模型上下文协议 (MCP)
工具是 Agentic 框架的重要组成部分,允许 LLM 与世界互动并扩展其功能。但是,当您有许多不同的 API 时,启用工具的使用会变得很麻烦,因为任何工具都需要:
- 手动跟踪并输入到 LLM
- 手动描述(包括其预期的 JSON 模式)
- 当 API 发生变化时,手动更新
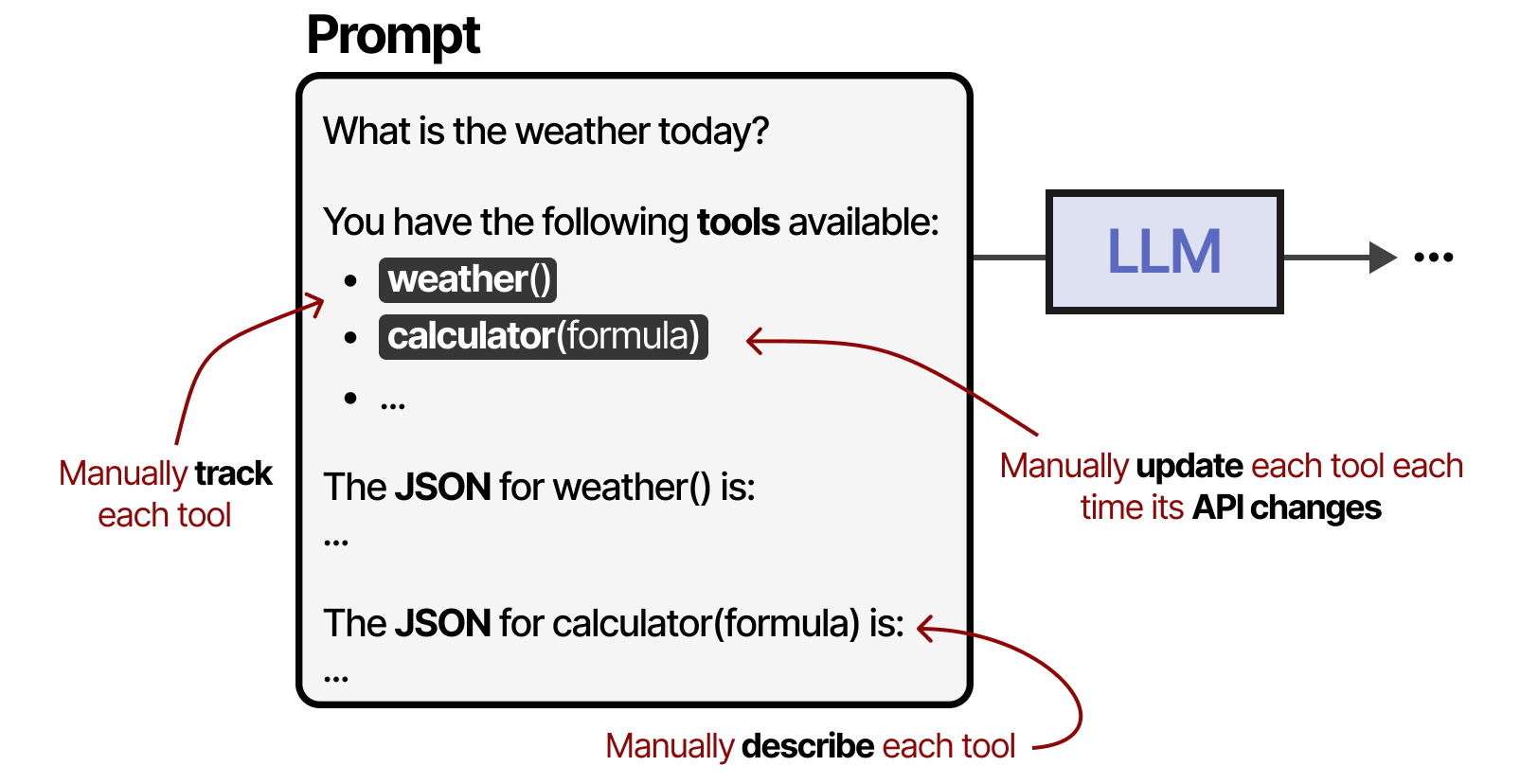
为了使工具更容易为任何给定的 Agentic 框架实现,Anthropic 开发了模型上下文协议 (MCP)。6MCP 标准化了天气应用程序和 GitHub 等服务的 API 访问。
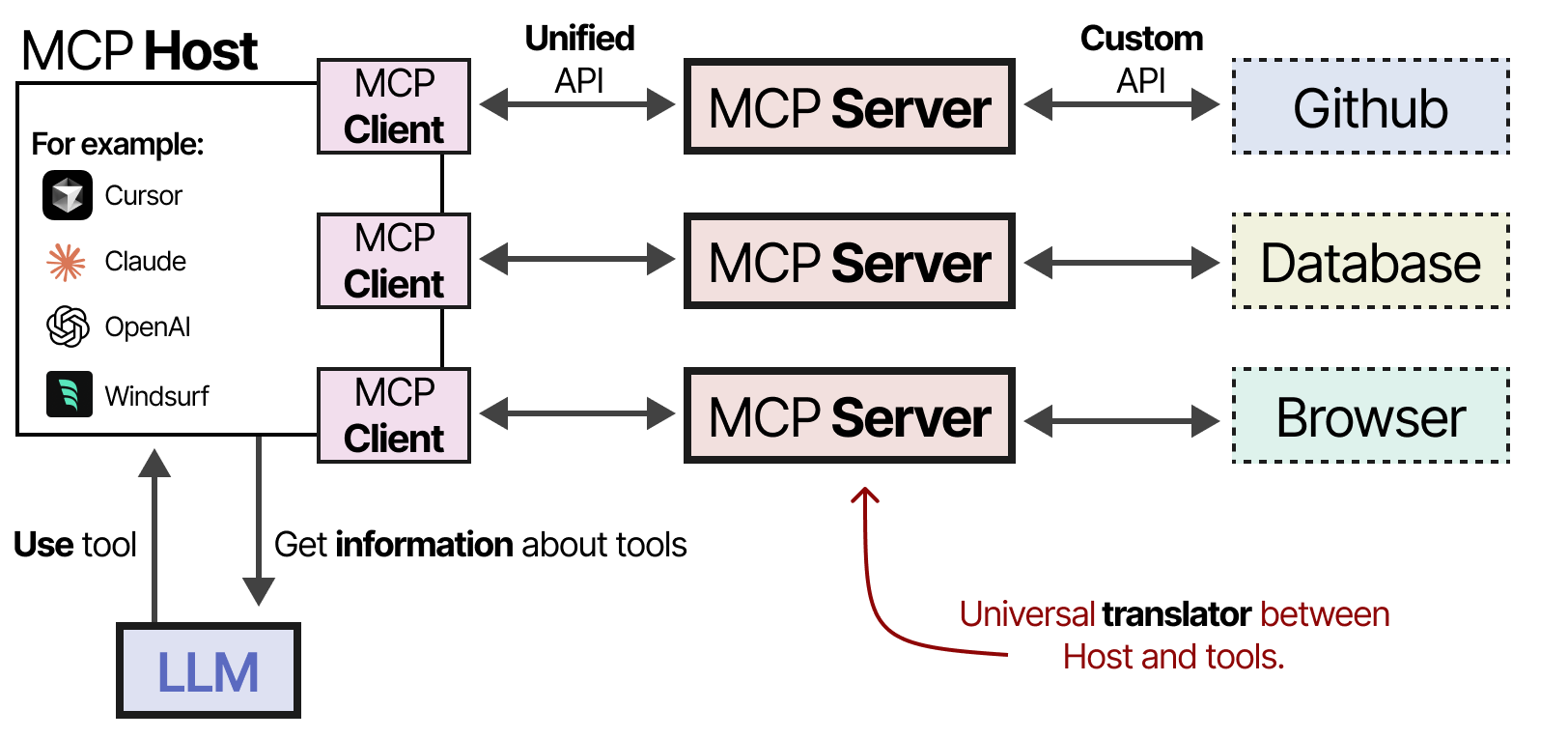
它由三个部分组成:
- MCP Host — 管理连接的 LLM 应用程序(例如 Cursor)
- MCP客户端— 与 MCP 服务器保持 1:1 连接
- MCP服务器— 为 LLM 提供上下文、工具和功能
例如,假设您希望给定的 LLM 应用程序总结存储库中最新的 5 个提交。
MCP Host(与客户端一起)会首先调用 MCP Server 询问有哪些工具可用。
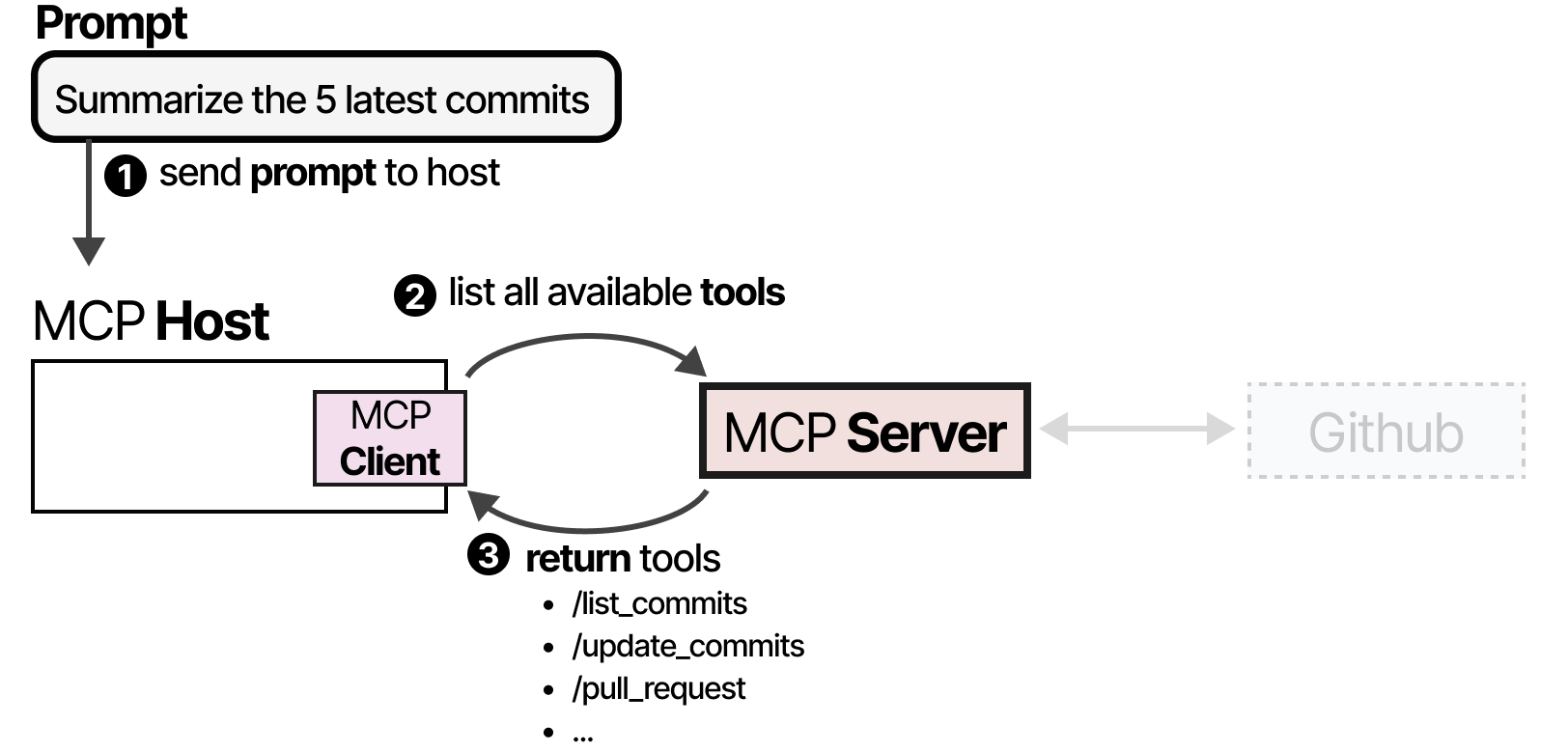
LLM 收到信息后,可以选择使用某个工具。它通过 Host 向 MCP Server 发送请求,然后接收结果,包括所使用的工具。
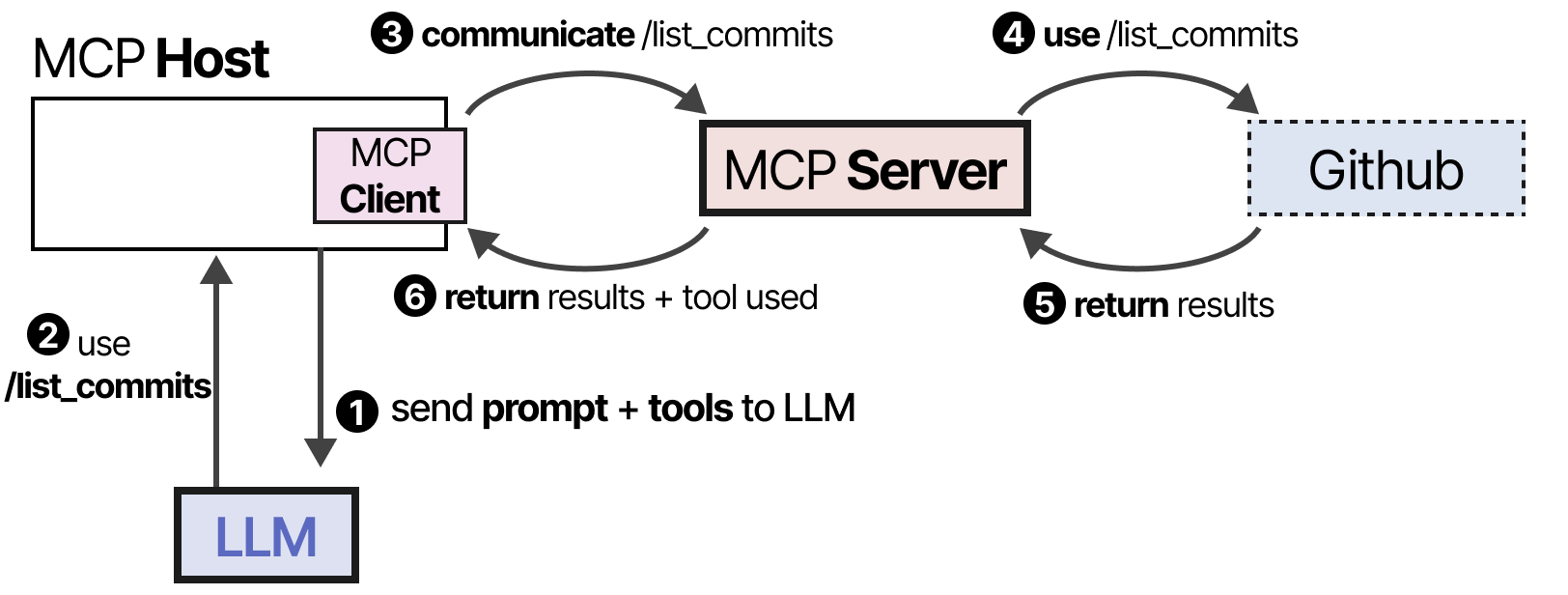
最后,LLM 接收结果并可以向用户解析答案。
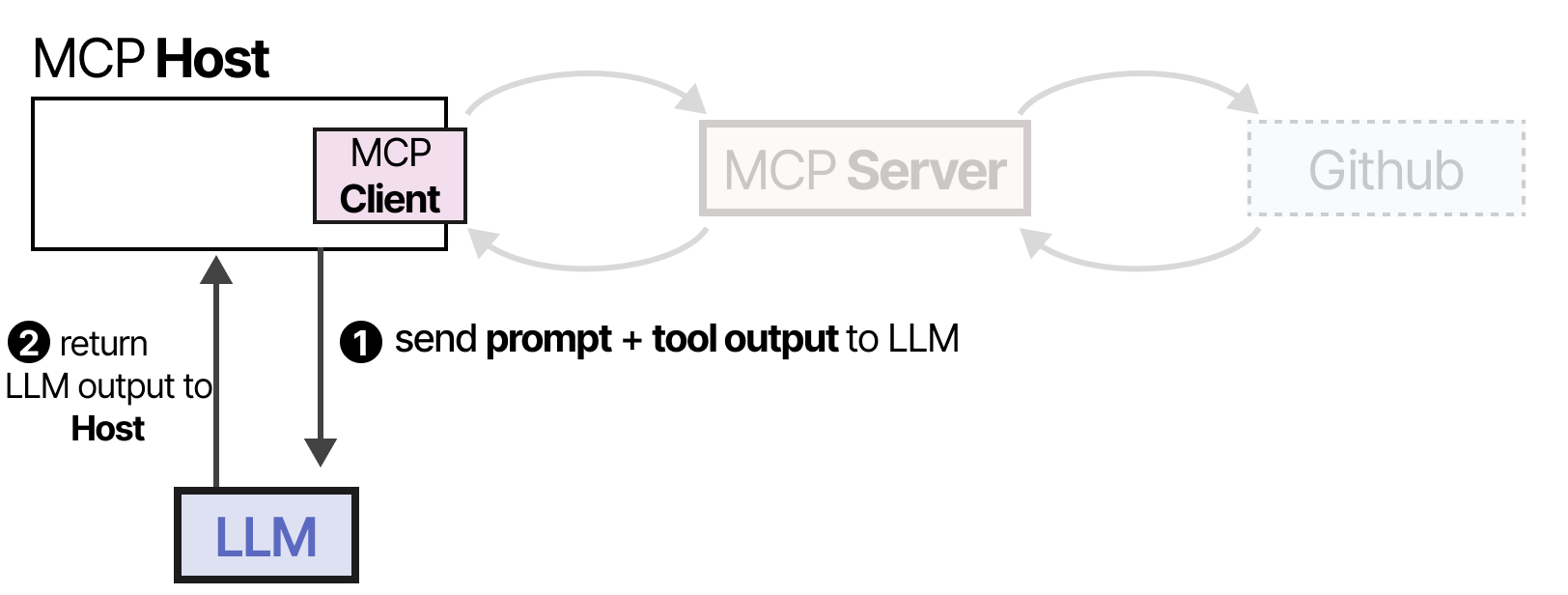
该框架通过连接到任何 LLM 应用程序都可以使用的 MCP 服务器,使创建工具变得更加容易。因此,当您创建 MCP 服务器与 Github 交互时,任何支持 MCP 的 LLM 应用程序都可以使用它。
规划
使用工具可提高 LLM 的功能。它们通常使用类似 JSON 的请求进行调用。
但是在agent系统中,LLM如何决定何时使用哪种工具?
这就是规划开始发挥作用的地方。LLM agent中的规划涉及将给定的任务分解为可操作的步骤。
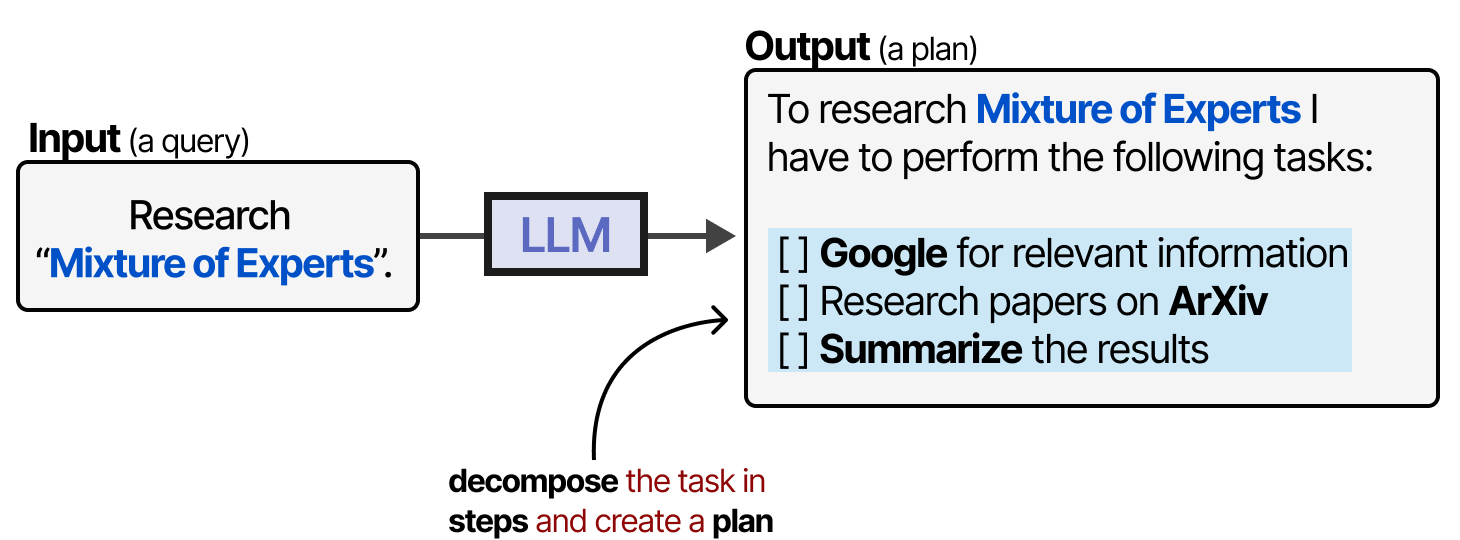
该计划允许模型迭代地反映过去的行为并在必要时更新当前计划。

我喜欢计划顺利完成的感觉!
为了实现 LLM Agent 中的规划,我们首先来看一下这项技术的基础,即推理。
推理
规划可行步骤需要复杂的推理行为。因此,LLM 必须能够展示这种行为,然后才能在规划任务的下一步之前展示这种行为。
“推理”LLM指的是那些在回答问题之前倾向于“思考”的人。
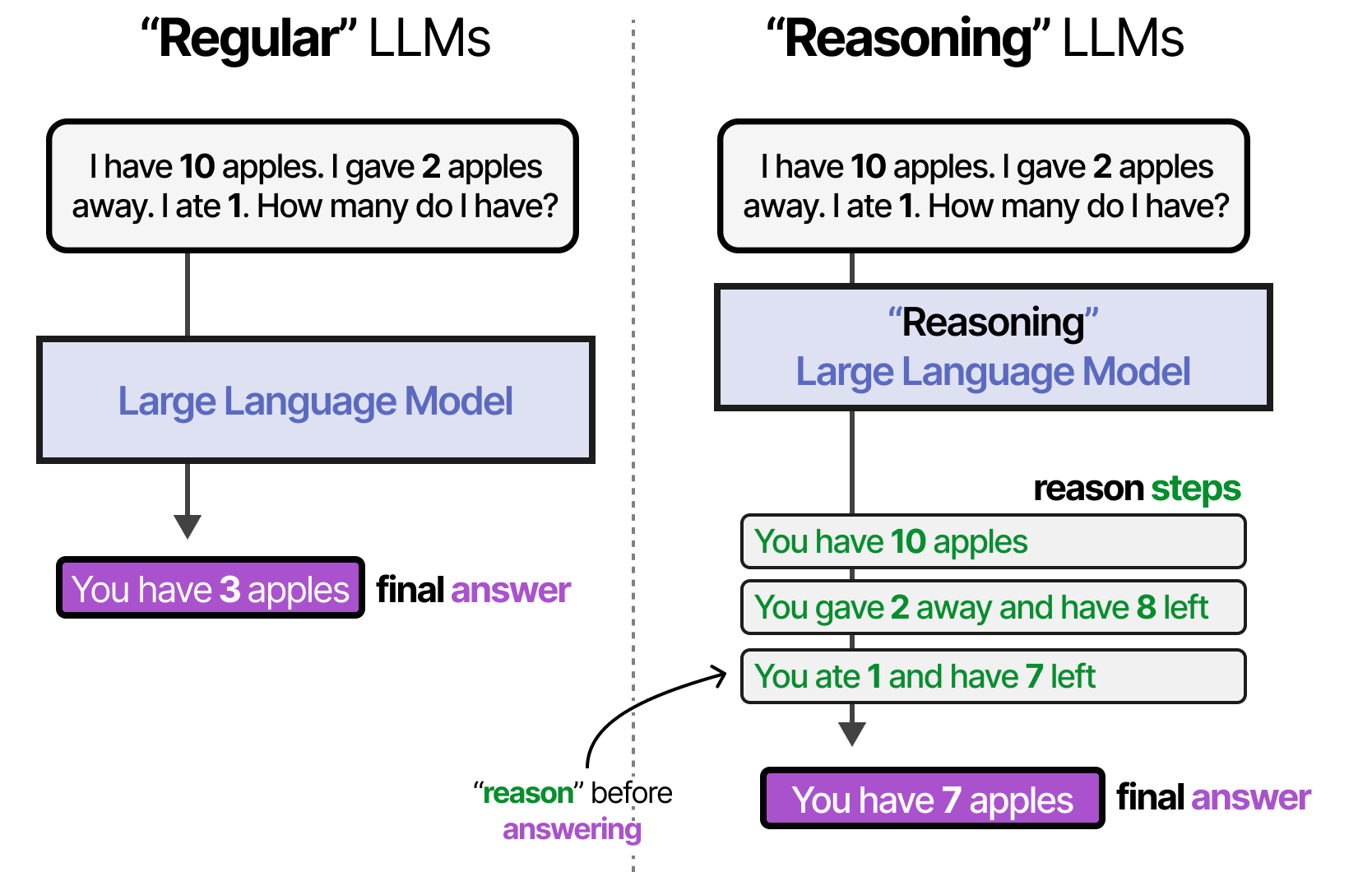
我使用“推理”和“思考”这两个术语有点宽泛,因为我们可以争论这是否是类似人类的思考,或者仅仅是将答案分解为结构化步骤。
这种推理行为可以通过大致两种选择来实现:微调 LLM 或特定的提示工程。
通过提示工程,我们可以创建 LLM 应该遵循的推理过程的示例。提供示例(也称为小样本提示)7) 是引导 LLM 行为的好方法。
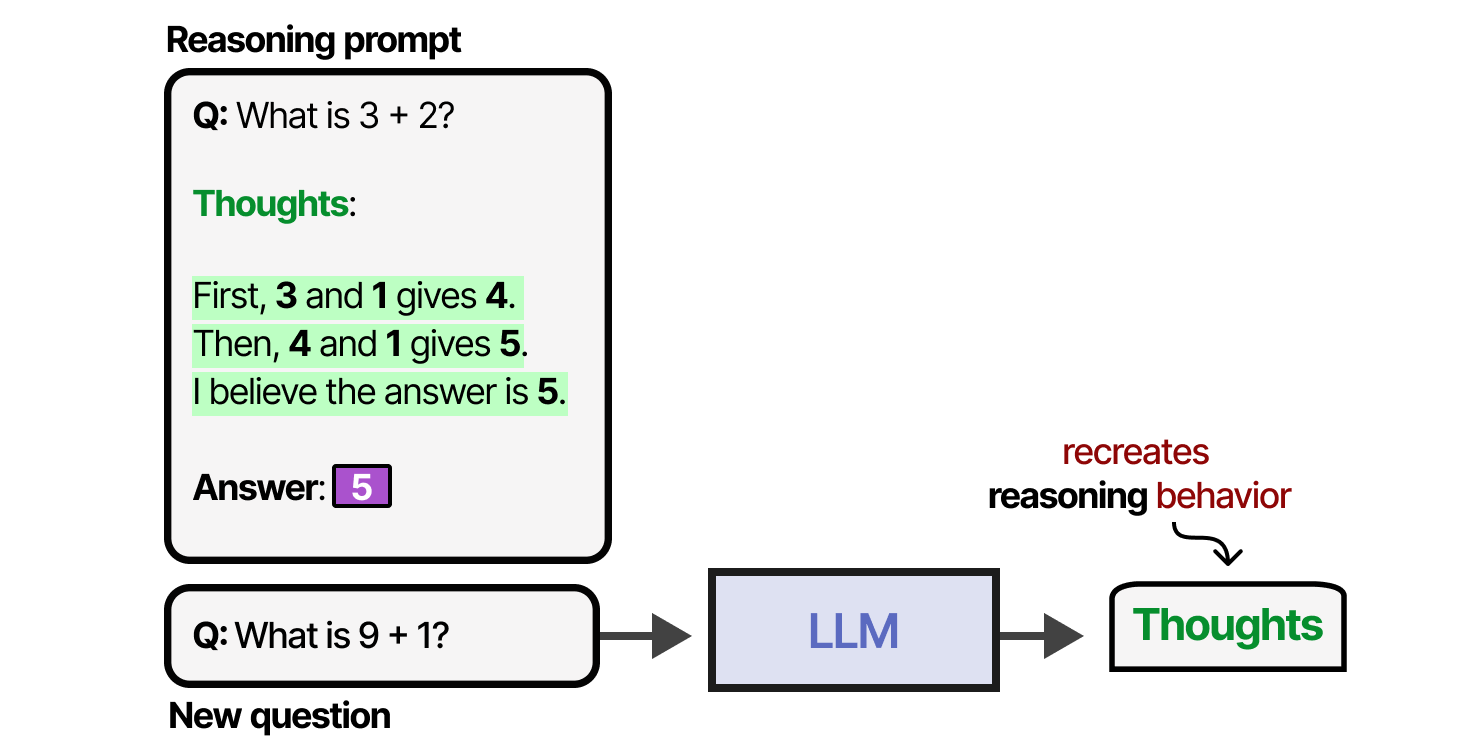
这种提供思维过程示例的方法称为思维链,可以实现更复杂的推理行为。8
只需说“让我们一步一步思考”,就可以在没有任何示例(零样本提示)的情况下启用思路链。9

在训练 LLM 时,我们可以为其提供足够数量的包含类似思想的示例的数据集,或者 LLM 可以发现自己的思维过程。
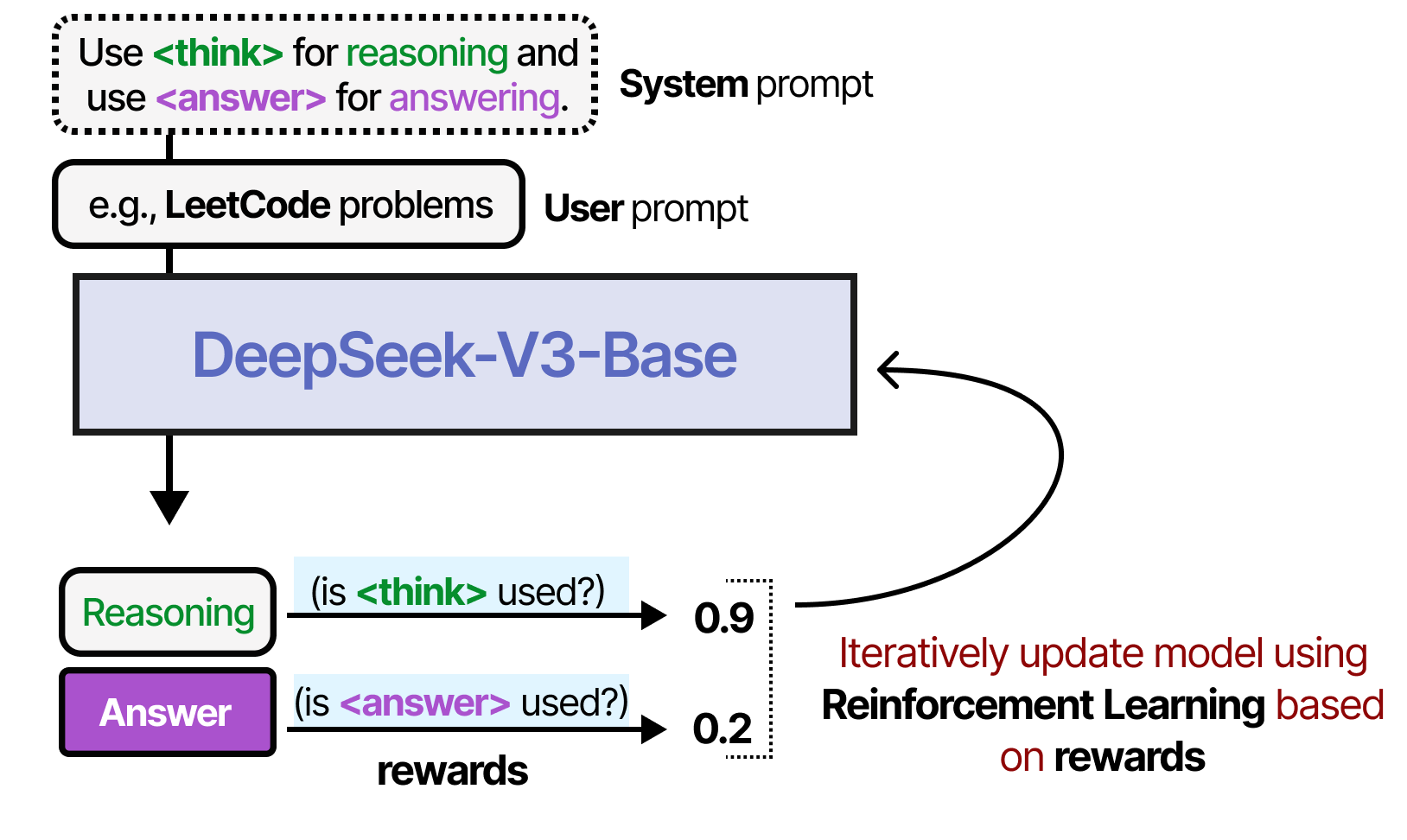
一个很好的例子是 DeepSeek-R1,它使用奖励来指导思考过程的使用。
推理与行动
在 LLM 中实现推理行为非常好,但并不一定能够规划出可行的步骤。
到目前为止,我们关注的技术要么展示推理行为,要么通过工具与环境互动。

例如,思维链 (Chain-of-Thought) 纯粹侧重于推理。
将这两个过程结合起来的首批技术之一被称为 ReAct(理性与行动)。10
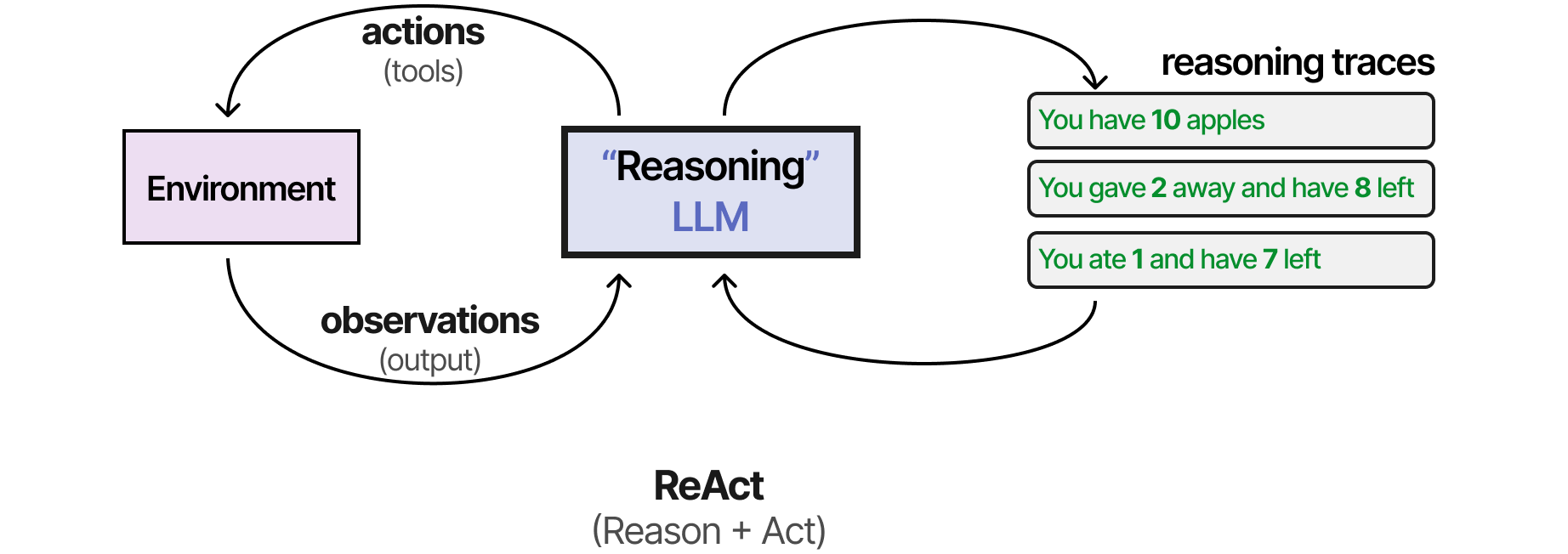
ReAct 通过精心的提示工程来实现这一目标。ReAct 提示描述了三个步骤:
- 思考——对当前情况进行推理
- 操作- 要执行的一组操作(例如工具)
- 观察——对行动结果的推理步骤
提示本身就非常简单。

LLM 使用这个提示(可以用作系统提示)来引导其行为在思想、行动和观察的循环中发挥作用。
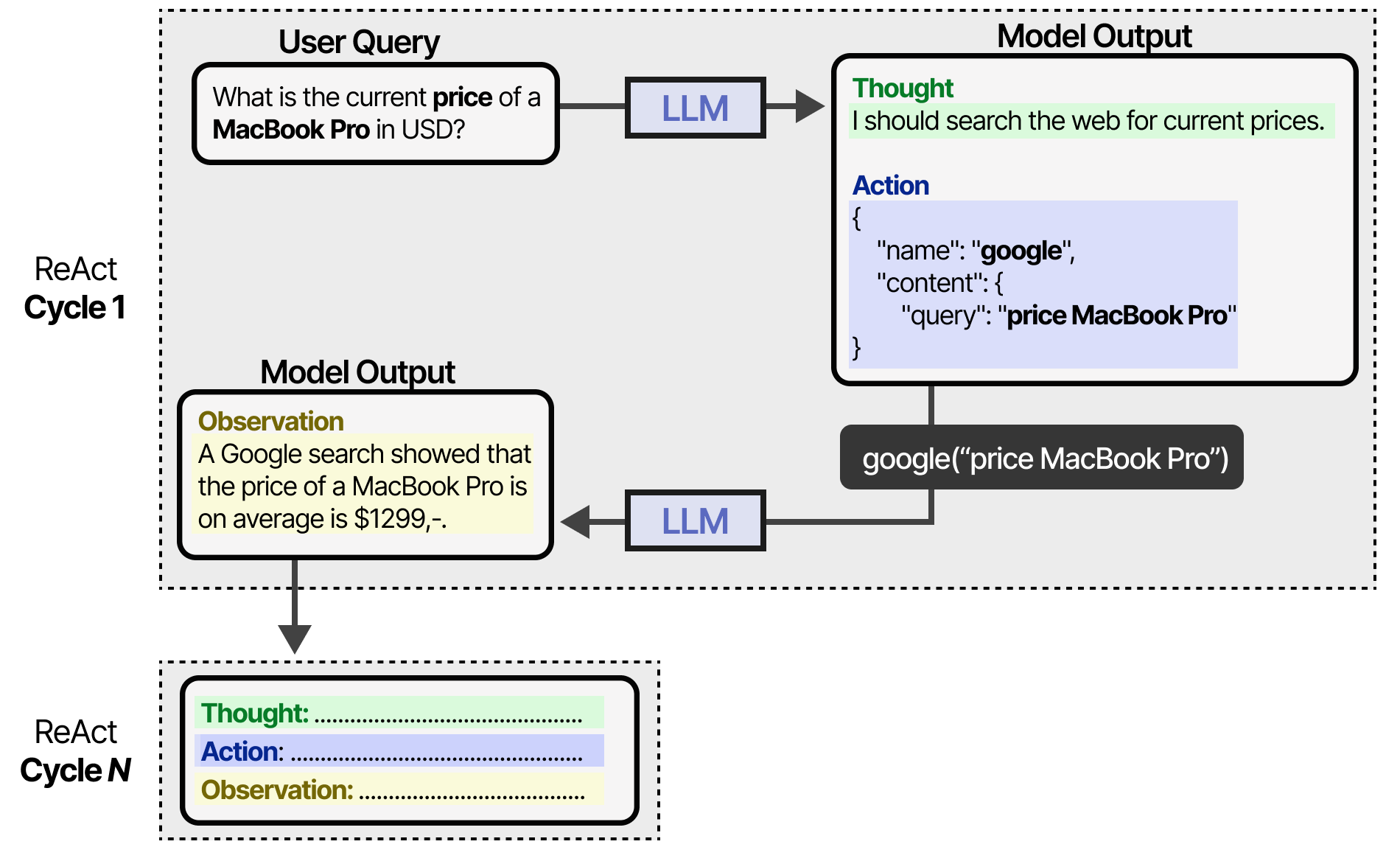
它会持续这种行为,直到某个操作指定返回结果。通过迭代想法和观察,LLM 可以规划出操作,观察其输出并进行相应调整。
因此,与具有预定义和固定步骤的agent相比,该框架使 LLM 能够展示更多自主的agent行为。
反思
没有人能够完美地完成每一项任务,即使是 ReAct LLM也不例外。只要你能反思这个过程,失败就是过程的一部分。
ReAct 缺少这一过程,而这正是 Reflexion 发挥作用的地方。Reflexion 是一种使用口头强化来帮助agent从以前的失败中吸取教训的技术。11
该方法假设三个 LLM 角色:
- 参与者——根据状态观察选择并执行动作。我们可以使用 Chain-of-Thought 或 ReAct 等方法。
- 评估者——对参与者产生的输出进行评分。
- 自我反思——反思参与者采取的行动和评估者给出的分数。
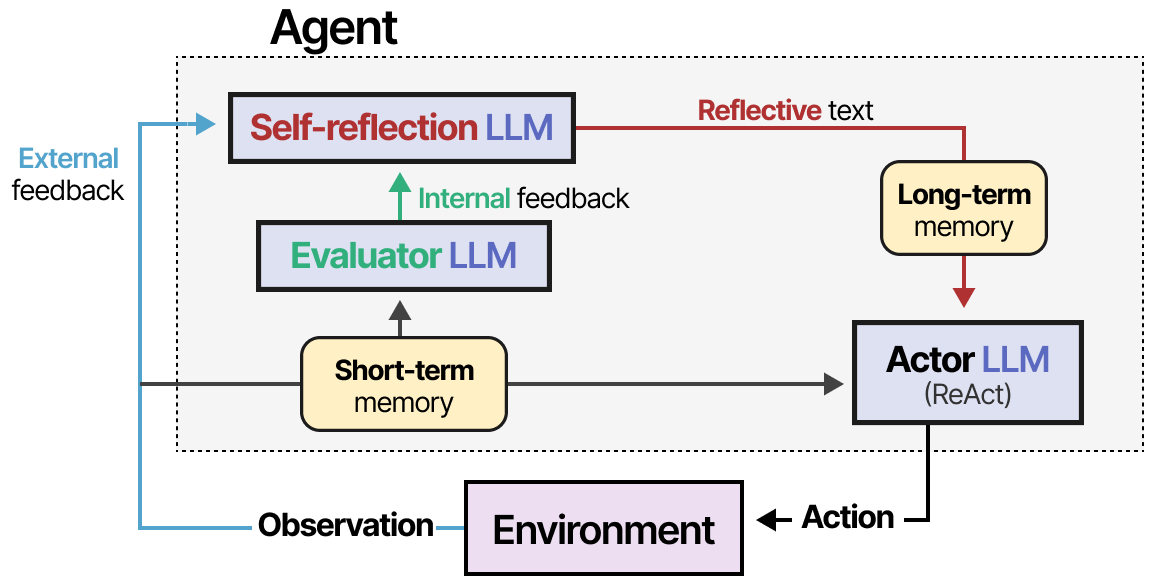
添加记忆模块来跟踪动作(短期)和自我反思(长期),帮助agent从错误中吸取教训并确定改进的动作。
一种类似且优雅的技术被称为“自我完善”,其中重复完善输出和生成反馈的操作。12
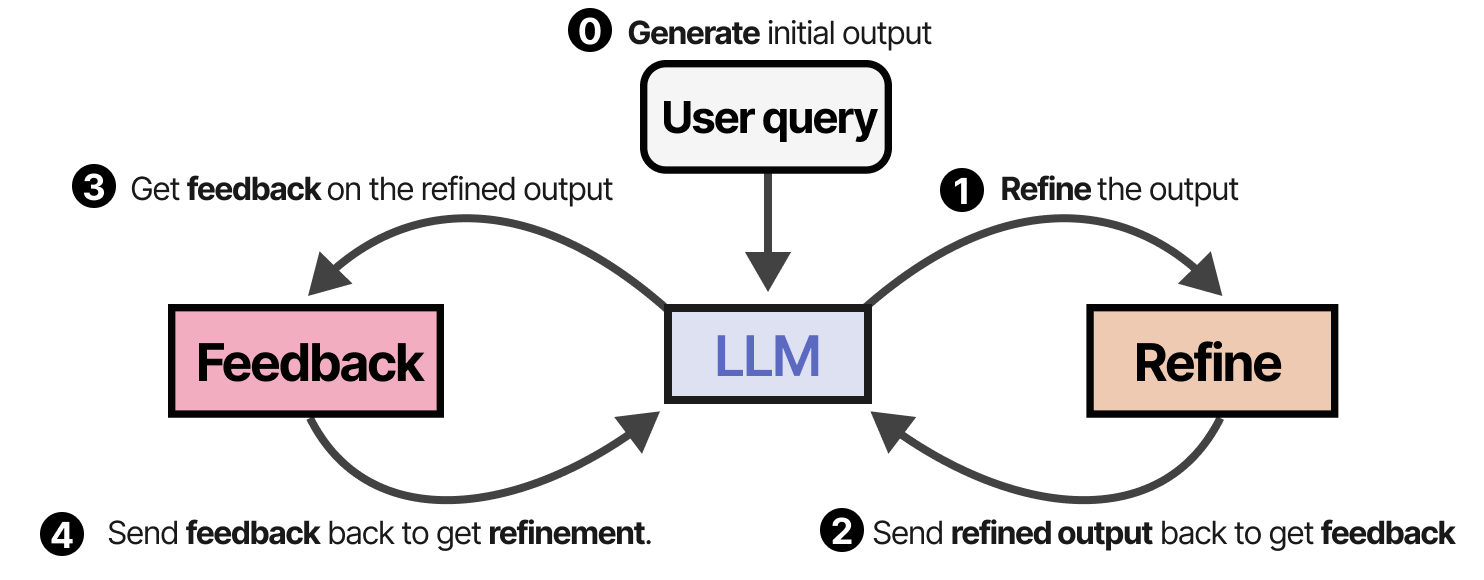
同一个 LLM 负责生成初始输出、精细输出和反馈。
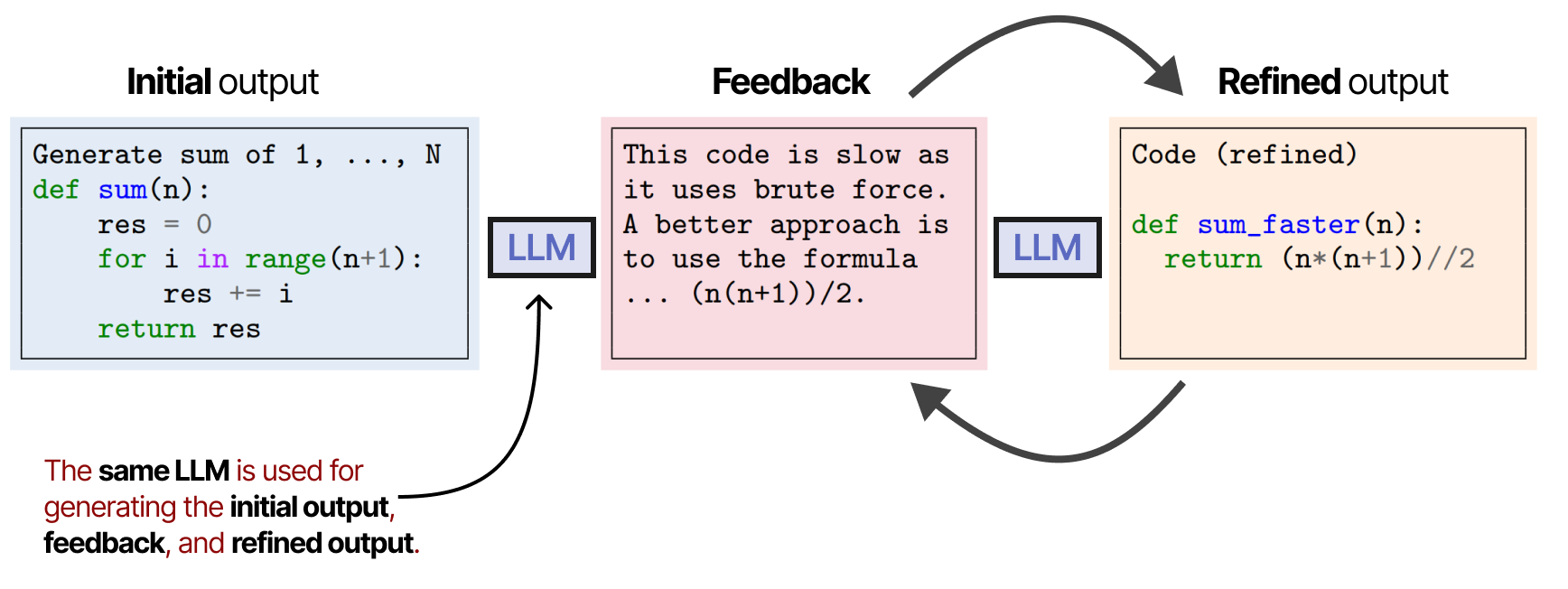
“ SELF-REFINE:带有自反馈的迭代细化”论文的注释图。
有趣的是,这种自我反思行为(反思和自我完善)与强化学习非常相似,强化学习根据输出的质量给予奖励。
多agent协作
我们探索的单个agent有几个问题:太多工具可能会使选择变得复杂,环境变得过于复杂,并且任务可能需要专业化。
相反,我们可以研究多智能体,即多个智能体(每个智能体都可以访问工具、内存和规划)相互交互并与环境交互的框架:
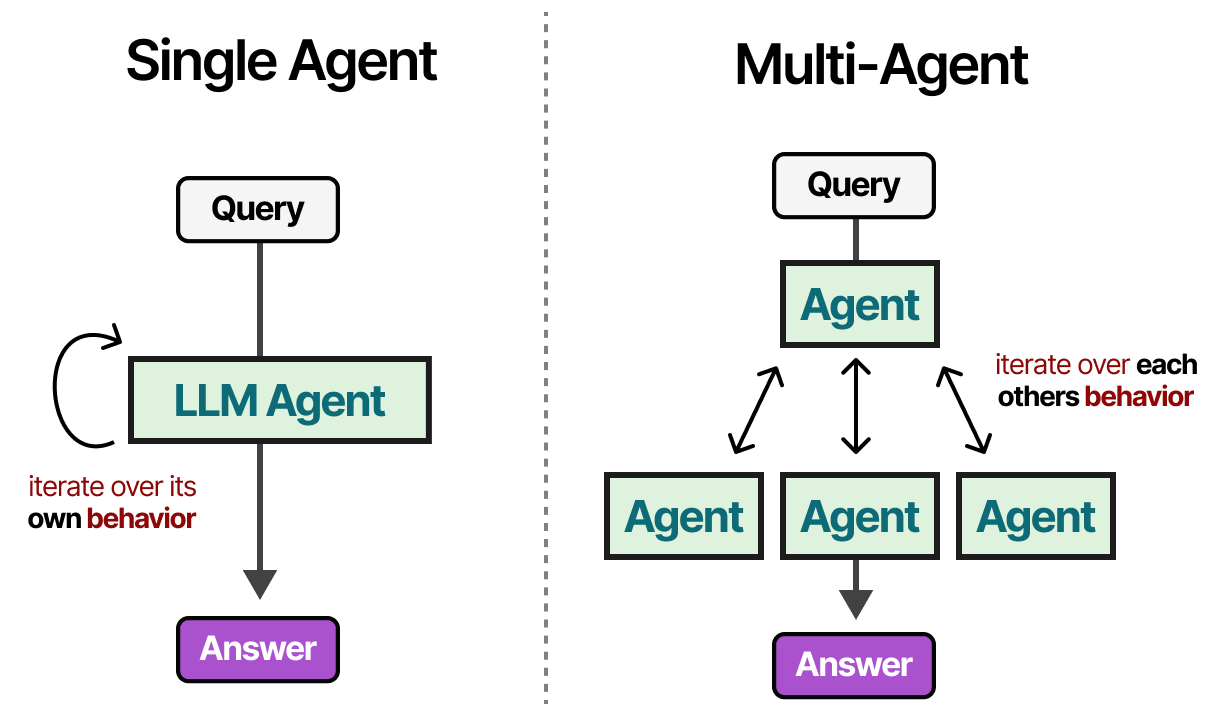
这些多agent系统通常由专门的agent组成,每个agent都配备了自己的工具集并由supervisor监督。supervisor管理agent之间的通信,并可以为专门的agent分配特定任务。
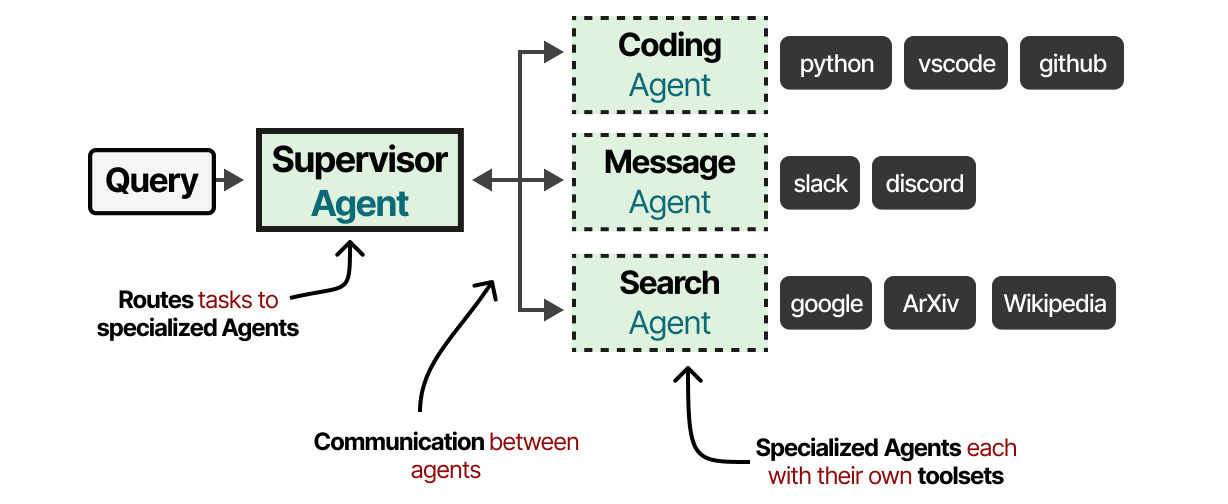
每个agent可能有不同类型的可用工具,但也可能有不同的记忆系统。
在实践中,有几十种多智能体架构,其核心有两个组件:
- agent初始化——如何创建单个(专门的)agent?
- agent编排——所有agent如何协调?
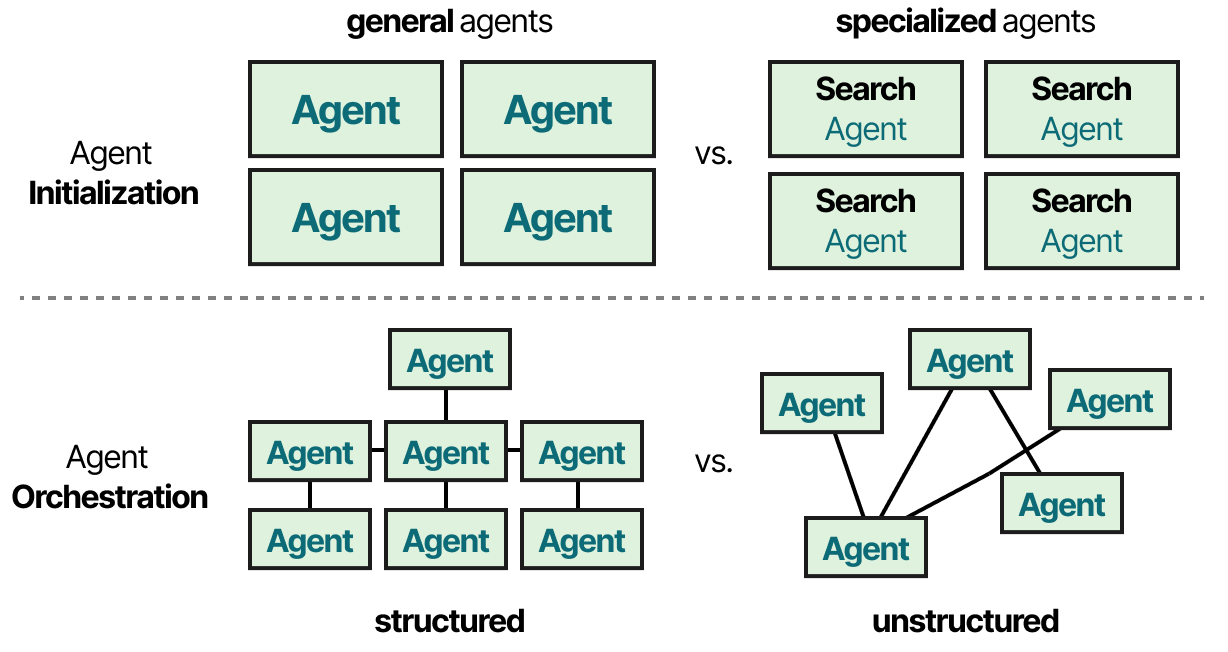
让我们探索各种有趣的多agent框架并重点介绍这些组件的实现方式。
人类行为的交互式模拟
可以说,最具影响力、坦率地说非常酷的多智能体论文之一名为“生成智能体:人类行为的交互式模拟”。十三
在本文中,他们创建了模拟可信人类行为的计算软件agent,他们称之为生成agent。

每个生成agent所赋予的配置文件使它们以独特的方式行事,并有助于创建更有趣和更具活力的行为。
每个agent都由三个模块(内存、规划和反射)初始化,非常类似于我们之前在 ReAct 和 Reflexion 中看到的核心组件。
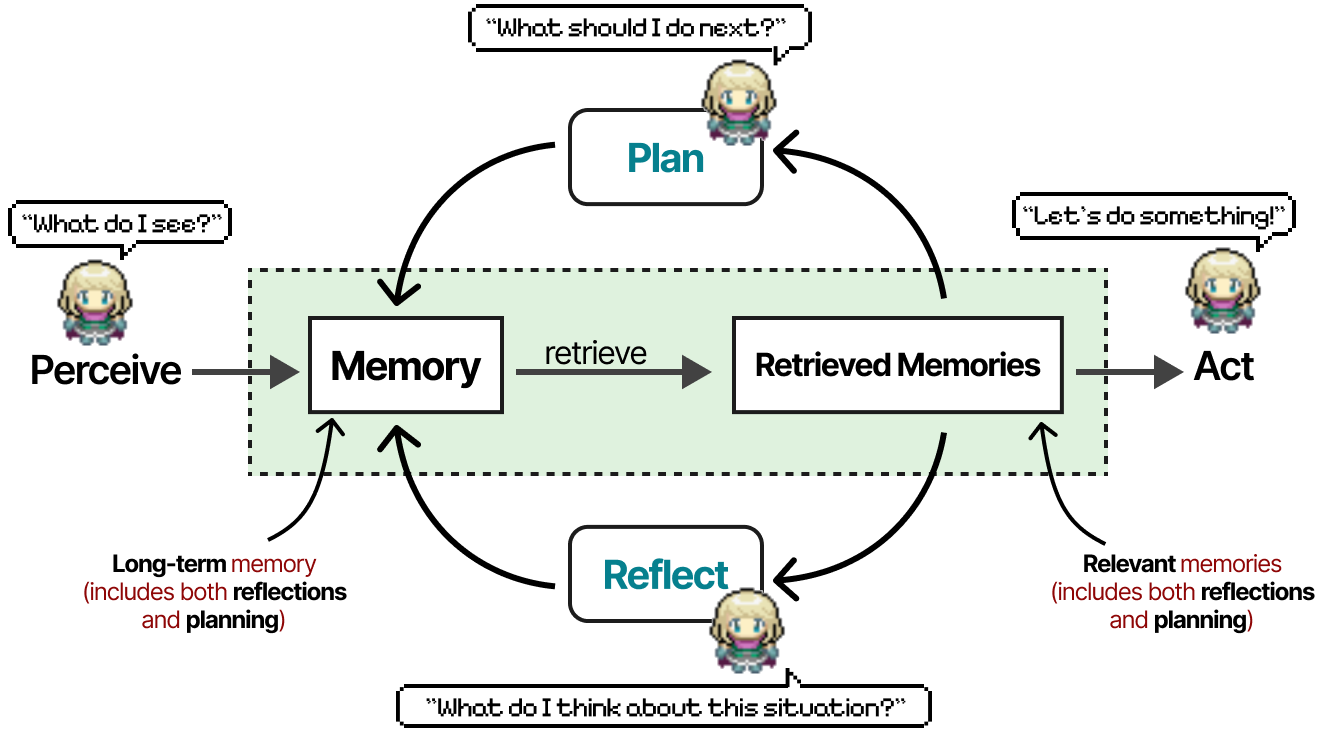
记忆模块是这个框架中最重要的组件之一。它存储了计划和反思行为,以及迄今为止的所有事件。
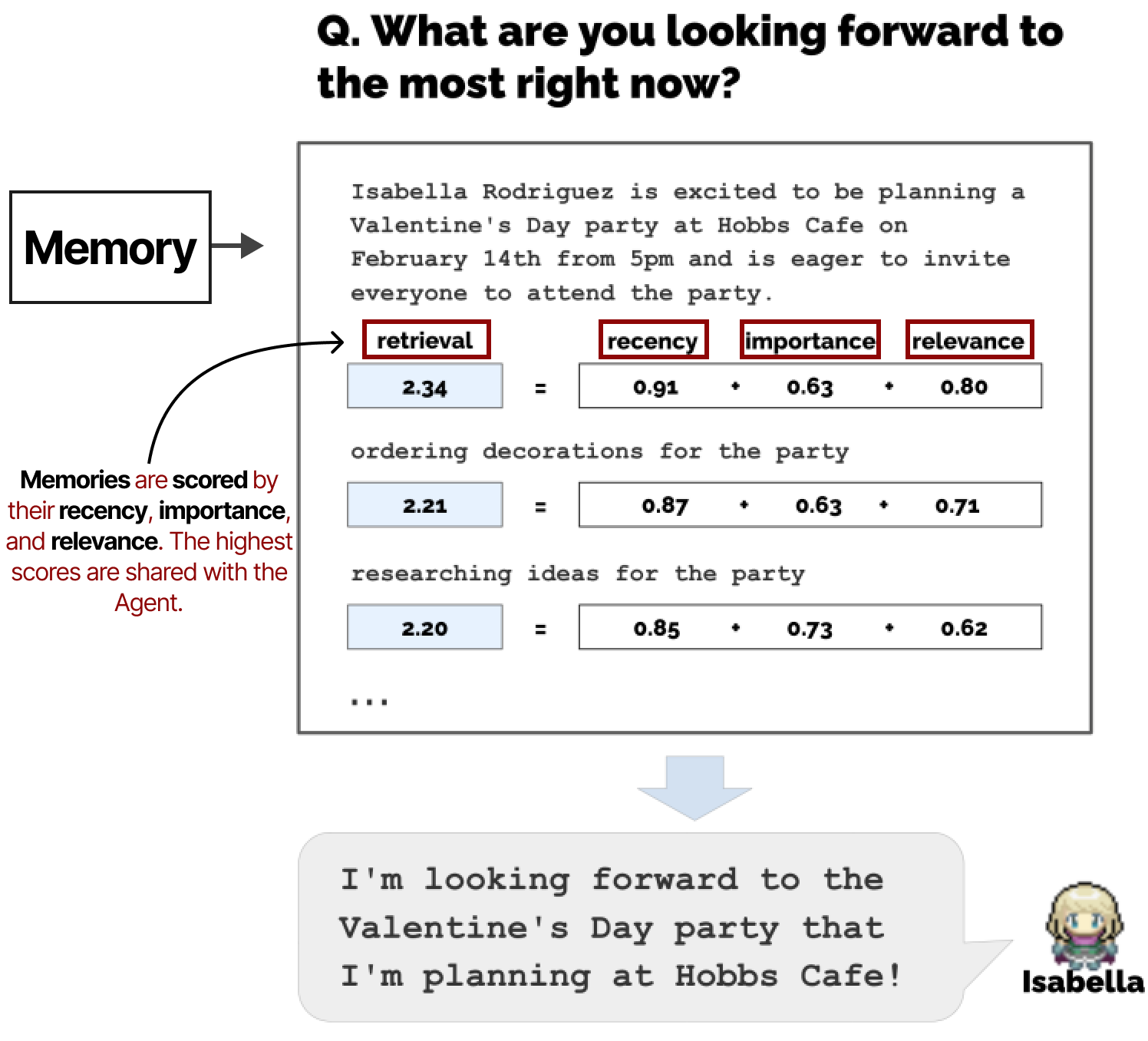
对于任何给定的下一步或问题,都会检索记忆并根据其相近性、重要性和相关性进行评分。得分最高的记忆将与agent共享。
它们共同允许 Agent 自由地开展其行为并相互交互。因此,Agent 的协调工作非常少,因为它们没有特定的工作目标。
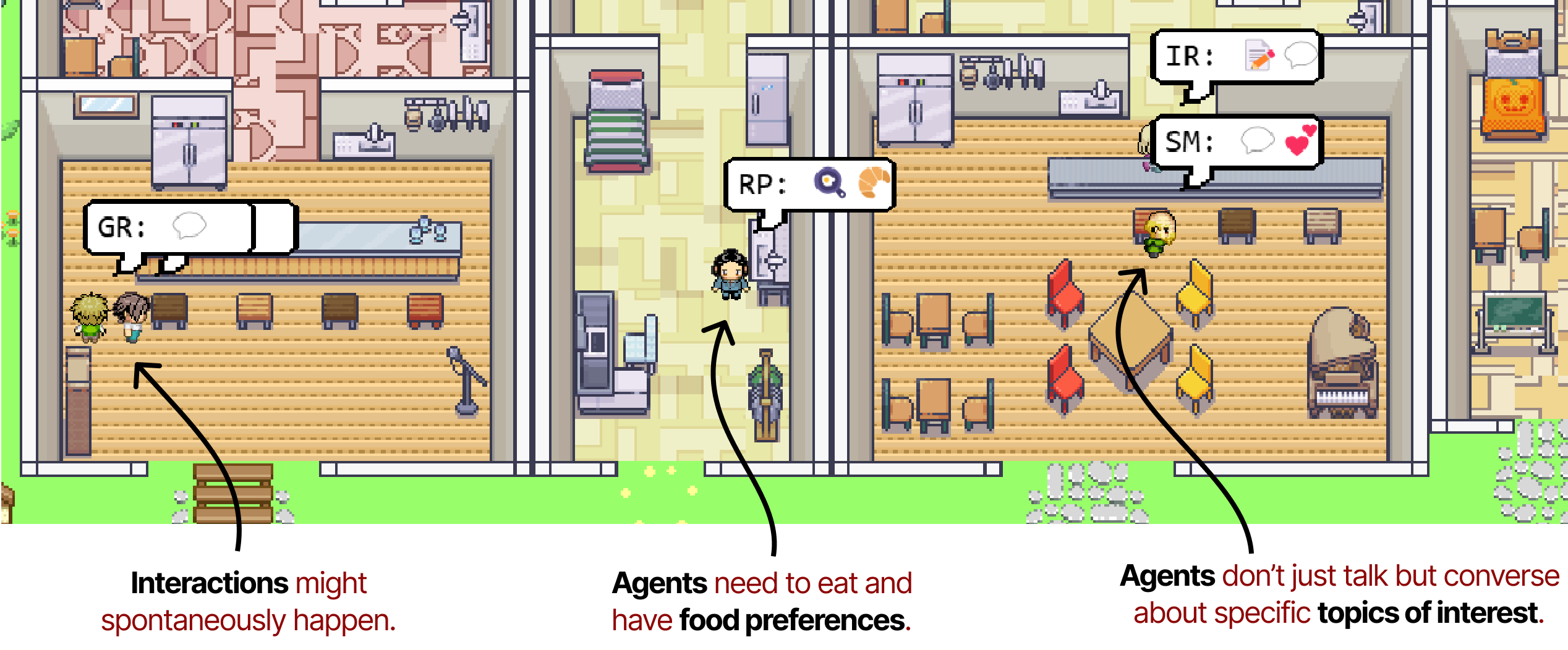
来自交互式演示的带注释的图像。
本文中有太多令人惊叹的信息片段,但我想强调它们的评估指标。14
他们的评估以agent行为的可信度作为主要指标,并由人类评估员对其进行评分。
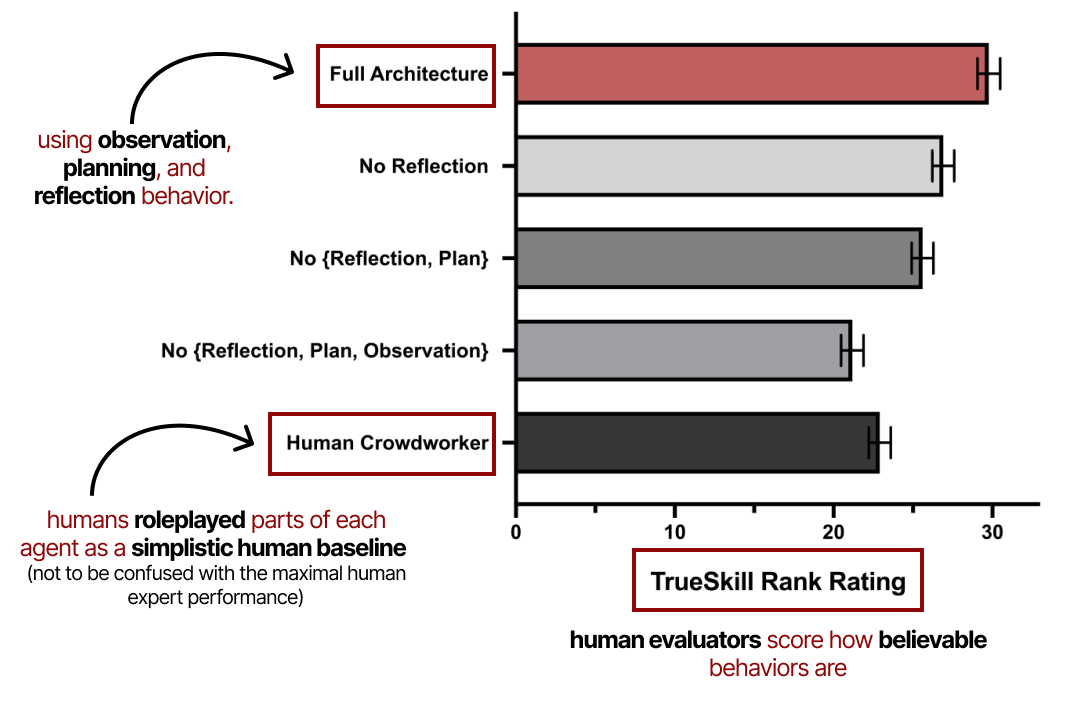
生成agent:人类行为的交互式模拟论文的注释图。
它展示了观察、规划和反思在这些生成agent的性能中的重要性。如前所述,如果没有反思行为,规划就不完整。
模块化框架
无论您选择哪种框架来创建多智能体系统,它们通常都由几个要素组成,包括其配置文件、对环境的感知、记忆、规划和可用的操作。1516
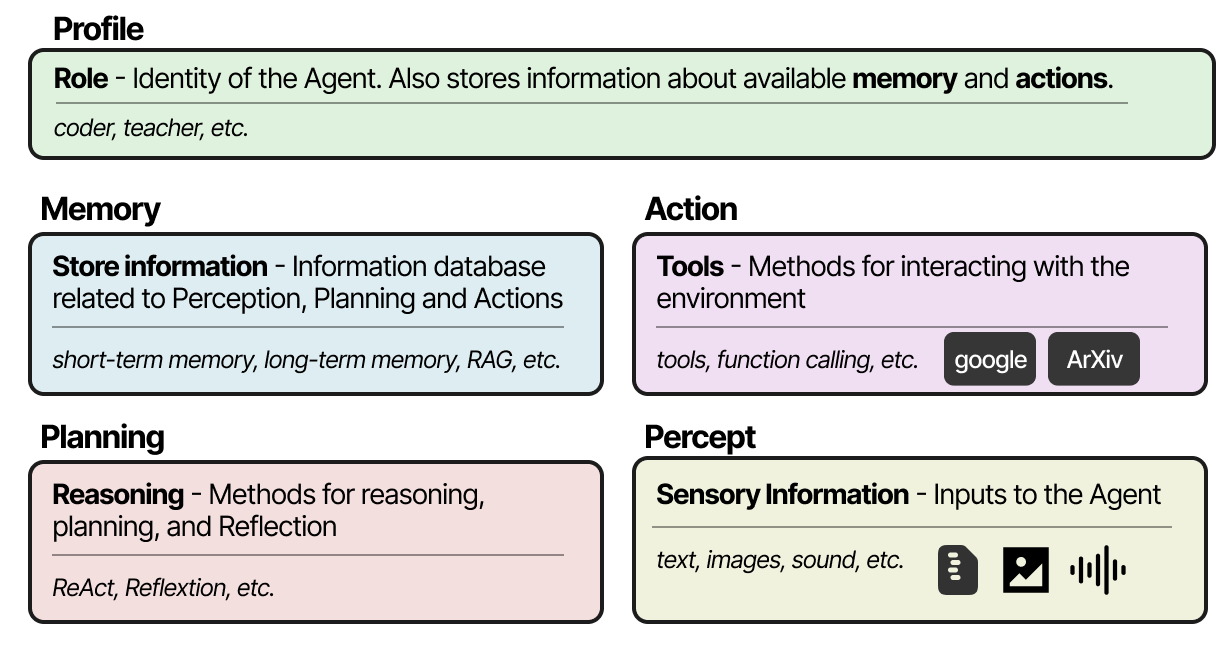
实现这些组件的流行框架是 AutoGen17、MetaGPT18和 CAMEL19。但是,每个框架处理每个 Agent 之间的通信的方式略有不同。
例如,使用 CAMEL,用户首先创建问题并定义AI 用户和AI 助手角色。AI 用户角色代表人类用户并将指导该过程。

之后,AI用户和AI助手将通过相互交互来协作解决查询。
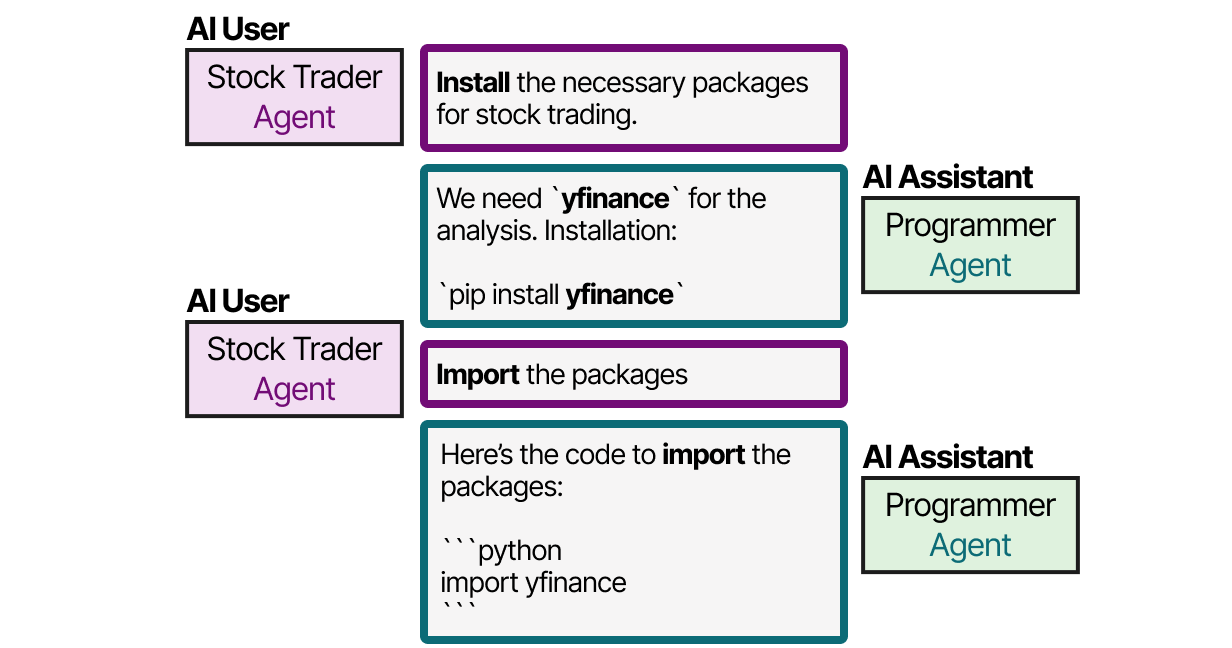
这种角色扮演方法使得agent之间能够进行协作通信。
AutoGen 和 MetaGPT 的沟通方式不同,但归根结底都是这种协作沟通方式。客服人员有机会相互交流,以更新他们的当前状态、目标和后续步骤。
在过去的一年里,特别是最近几周,这些框架的增长呈爆炸式增长。
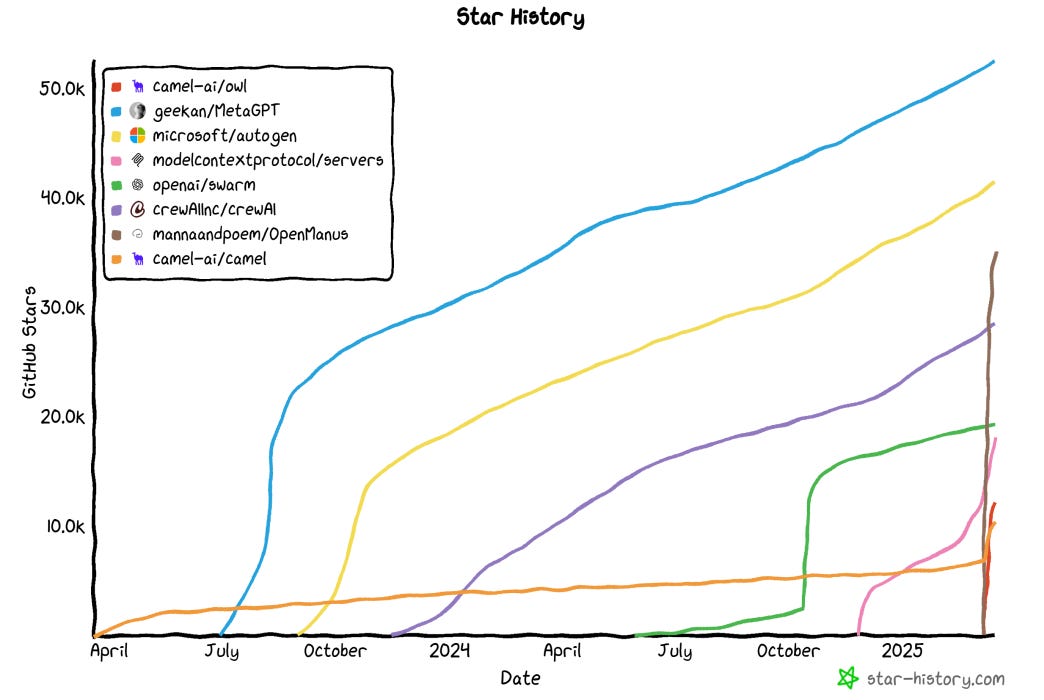
随着这些框架不断成熟和发展,2025 年将是真正令人兴奋的一年!
结论
这就是我们 LLM agent之旅的结束!希望这篇文章能让您更好地理解 LLM agent的构建方式。
Russell, S. J., & Norvig, P. (2016). Artificial intelligence: a modern approach. pearson.
Sumers, Theodore, et al. “Cognitive architectures for language agents.” Transactions on Machine Learning Research (2023).
Schick, Timo, et al. “Toolformer: Language models can teach themselves to use tools.” Advances in Neural Information Processing Systems 36 (2023): 68539-68551.
Qin, Yujia, et al. “Toolllm: Facilitating large language models to master 16000+ real-world apis.” arXiv preprint arXiv:2307.16789 (2023).
Patil, Shishir G., et al. “Gorilla: Large language model connected with massive apis.” Advances in Neural Information Processing Systems 37 (2024): 126544-126565.
“Introducing the Model Context Protocol.” Anthropic, www.anthropic.com/news/model-context-protocol. Accessed 13 Mar. 2025.
Mann, Ben, et al. “Language models are few-shot learners.” arXiv preprint arXiv:2005.14165 1 (2020): 3.
Wei, Jason, et al. “Chain-of-thought prompting elicits reasoning in large language models.” Advances in neural information processing systems 35 (2022): 24824-24837.
Kojima, Takeshi, et al. “Large language models are zero-shot reasoners.” Advances in neural information processing systems 35 (2022): 22199-22213.
Yao, Shunyu, Zhao, Jeffrey, Yu, Dian, Du, Nan, Shafran, Izhak, Narasimhan, Karthik, and Cao, Yuan. ReAct: Synergizing Reasoning and Acting in Language Models. Retrieved from https://par.nsf.gov/biblio/10451467. International Conference on Learning Representations (ICLR).
Shinn, Noah, et al. “Reflexion: Language agents with verbal reinforcement learning.” Advances in Neural Information Processing Systems 36 (2023): 8634-8652.
Madaan, Aman, et al. “Self-refine: Iterative refinement with self-feedback.” Advances in Neural Information Processing Systems 36 (2023): 46534-46594.
Park, Joon Sung, et al. “Generative agents: Interactive simulacra of human behavior.” Proceedings of the 36th annual acm symposium on user interface software and technology. 2023.
To see a cool interactive playground of the Generative Agents, follow this link: https://reverie.herokuapp.com/arXiv_Demo/
Wang, Lei, et al. “A survey on large language model based autonomous agents.” Frontiers of Computer Science 18.6 (2024): 186345.
Xi, Zhiheng, et al. “The rise and potential of large language model based agents: A survey.” Science China Information Sciences 68.2 (2025): 121101.
Wu, Qingyun, et al. “Autogen: Enabling next-gen llm applications via multi-agent conversation.” arXiv preprint arXiv:2308.08155 (2023).
Hong, Sirui, et al. “Metagpt: Meta programming for multi-agent collaborative framework.” arXiv preprint arXiv:2308.00352 3.4 (2023): 6.
Li, Guohao, et al. “Camel: Communicative agents for” mind” exploration of large language model society.” Advances in Neural Information Processing Systems 36 (2023): 51991-52008.