DeepSeek R1 蒸馏指导手册
参考工程:https://github.com/huggingface/open-r1
1、DeepSeek R1蒸馏原理
蒸馏是一种机器学习技术,其中较小的模型(“学生”)经过训练以模仿较大的预训练模型(“老师”)的行为。目标是保留老师的大部分表现,同时显着降低计算成本和内存占用。
DeepSeek R1 SFT蒸馏小模型的本质:将【DeepSeek R1大模型的推理轨迹】转移给小模型
具体过程:
-
蒸馏数据准备
- 准备数据集,包含“问题+答案”。
::: 问题:
Return your final response within \boxed{}. The operation $\otimes$ is defined for all nonzero numbers by $a\otimes b =\frac{a^{2}}{b}$. Determine $[(1\otimes 2)\otimes 3]-[1\otimes (2\otimes 3)]$.\n$\text{(A)}\ -\frac{2}{3}\qquad\text{(B)}\ -\frac{1}{4}\qquad\text{(C)}\ 0\qquad\text{(D)}\ \frac{1}{4}\qquad\text{(E)}\ \frac{2}{3}$
答案:
Thus, the answer is \(\boxed{A}\) :::
- 让DeepSeek R1模型回答数据集的“问题”,得到“思考过程+答案”。prompt示例如下:
::: Your role as an assistant involves thoroughly exploring questions through a systematic long thinking process before providing the final precise and accurate solutions. This requires engaging in a comprehensive cycle of analysis, summarizing, exploration, reassessment, reflection, backtracing, and iteration to develop well-considered thinking process. Please structure your response into two main sections: Thought and Solution. In the Thought section, detail your reasoning process using the specified format: <|begin_of_thought|> {thought with steps separated with ’\n\n’} <|end_of_thought|> Each step should include detailed considerations such as analisying questions, summarizing relevant findings, brainstorming new ideas, verifying the accuracy of the current steps, refining any errors, and revisiting previous steps. In the Solution section, based on various attempts, explorations, and reflections from the Thought section, systematically present the final solution that you deem correct. The solution should remain a logical, accurate, concise expression style and detail necessary step needed to reach the conclusion, formatted as follows: <|begin_of_solution|> {final formatted, precise, and clear solution} <|end_of_solution|> Now, try to solve the following question through the above guidelines: :::
- 用人工或者模型对以上数据集做筛选,去掉思考过程不合理或者答案不对的数据。获得可用于蒸馏的数据集,其中每一条数据包含“问题+思考过程+答案”。
用于蒸馏的数据示例:
::: 问题:
Return your final response within \boxed{}. The operation $\otimes$ is defined for all nonzero numbers by $a\otimes b =\frac{a^{2}}{b}$. Determine $[(1\otimes 2)\otimes 3]-[1\otimes (2\otimes 3)]$.\n$\text{(A)}\ -\frac{2}{3}\qquad\text{(B)}\ -\frac{1}{4}\qquad\text{(C)}\ 0\qquad\text{(D)}\ \frac{1}{4}\qquad\text{(E)}\ \frac{2}{3}$
思考过程:
| < | begin_of_thought | >\n\nOkay, let me try to figure out this problem. So, we have this operation defined as a⊗b = a²/b. And we need to compute [(1⊗2)⊗3] - [1⊗(2⊗3)]. Then choose the correct answer from the options given. Alright, let’s break it down step by step.\n\nFirst, I need to remember that the operation ⊗ is not associative, right? Because the problem is asking for the difference between two different groupings: (1⊗2)⊗3 and 1⊗(2⊗3). So, the order in which we perform the operations matters here. That’s probably why there’s a subtraction between them.\n\nLet me start by computing each part separately. Let’s tackle the first part: (1⊗2)⊗3.\n\nStarting with the innermost operation, which is 1⊗2. According to the definition, a⊗b = a²/b. So here, a is 1 and b is 2. Plugging those in: 1² / 2 = 1/2. So, 1⊗2 equals 1/2.\n\nNow, we take that result and perform the next operation with 3. So, (1⊗2)⊗3 becomes (1/2)⊗3. Again, using the same definition: a is now 1/2 and b is 3. So, ( (1/2)² ) / 3 = (1/4) / 3 = 1/12. So, (1⊗2)⊗3 equals 1/12.\n\nAlright, that’s the first part. Now let’s compute the second part: 1⊗(2⊗3). Again, starting with the innermost operation, which is 2⊗3. Applying the definition: a is 2 and b is 3. So, 2² / 3 = 4/3. Therefore, 2⊗3 equals 4/3.\n\nNow, we need to compute 1⊗(4/3). Here, a is 1 and b is 4/3. Using the operation definition: 1² / (4/3) = 1 / (4/3) = 3/4. So, 1⊗(2⊗3) equals 3/4.\n\nNow, the problem asks for the difference between the two results: [(1⊗2)⊗3] - [1⊗(2⊗3)] = (1/12) - (3/4). To subtract these fractions, they need a common denominator. The denominators are 12 and 4, so 12 is the common denominator.\n\nConverting 3/4 to twelfths: 3/4 = 9/12. So, 1/12 - 9/12 = (1 - 9)/12 = -8/12. Simplifying that fraction by dividing numerator and denominator by 4: -8/12 = -2/3.\n\nHmm, looking at the answer choices, option A is -2/3. So, is that the answer? Wait, but let me double-check my calculations to make sure I didn’t make a mistake somewhere.\n\nFirst, checking (1⊗2): 1² / 2 = 1/2. Correct. Then, (1/2)⊗3: (1/2)² / 3 = (1/4)/3 = 1/12. That seems right.\n\nNow, for 2⊗3: 2² / 3 = 4/3. Correct. Then, 1⊗(4/3): 1² / (4/3) = 1 / (4/3) = 3/4. Yes, that’s correct.\n\nSubtracting 3/4 from 1/12: 1/12 - 3/4. Convert 3/4 to 9/12, so 1/12 - 9/12 = -8/12 = -2/3. Yes, that all checks out. So the answer should be -2/3, which is option A.\n\nWait, but let me think again. The operation is defined for all nonzero numbers, so we don’t have any issues with division by zero here. 2⊗3 is 4/3, which is fine, and then 1⊗(4/3) is 3/4. Correct.\n\nAlternatively, maybe there’s a different way to approach the problem? Let me try expanding both expressions using variables to see if there’s a pattern.\n\nLet’s denote the first expression: (a⊗b)⊗c. Using the definition:\n\nFirst, compute a⊗b = a²/b.\n\nThen, take that result and ⊗ with c: (a²/b)⊗c = ( (a²/b)² ) / c = a⁴ / (b² c).\n\nNow, the second expression: a⊗(b⊗c). First compute b⊗c = b²/c.\n\nThen, a⊗(b²/c) = a² / (b²/c) = a² * (c / b²) = (a² c) / b².\n\nTherefore, the difference between the two expressions is:\n\n(a⁴ / (b² c)) - (a² c / b²) = (a⁴ - a² c²) / (b² c) = a² (a² - c²) / (b² c).\n\nHmm, factoring that, it’s a² (a - c)(a + c) / (b² c).\n\nBut in our specific problem, a = 1, b = 2, c = 3. Plugging those values in:\n\n1² (1 - 3)(1 + 3) / (2² * 3) = 1 * (-2)(4) / (4 * 3) = (-8) / 12 = -2/3. Same result. So that confirms the answer is indeed -2/3.\n\nTherefore, I think my initial calculation was correct, and the answer is option A.\n\n**Final Answer**\n\boxed{A}\n\n< | end_of_thought | >\n\n< | begin_of_solution | >\n\nTo determine the value of \([(1 \otimes 2) \otimes 3] - [1 \otimes (2 \otimes 3)]\) where the operation \(\otimes\) is defined by \(a \otimes b = \frac{a^2}{b}\), we proceed as follows:\n\nFirst, compute \(1 \otimes 2\):\n\[\n1 \otimes 2 = \frac{1^2}{2} = \frac{1}{2}\n\]\nNext, use this result to compute \((1 \otimes 2) \otimes 3\):\n\[\n\left(\frac{1}{2}\right) \otimes 3 = \frac{\left(\frac{1}{2}\right)^2}{3} = \frac{\frac{1}{4}}{3} = \frac{1}{12}\n\]\n\nNow, compute \(2 \otimes 3\):\n\[\n2 \otimes 3 = \frac{2^2}{3} = \frac{4}{3}\n\]\nThen, use this result to compute \(1 \otimes (2 \otimes 3)\):\n\[\n1 \otimes \left(\frac{4}{3}\right) = \frac{1^2}{\frac{4}{3}} = \frac{1}{\frac{4}{3}} = \frac{3}{4}\n\]\n\nFinally, find the difference between the two results:\n\[\n\frac{1}{12} - \frac{3}{4} = \frac{1}{12} - \frac{9}{12} = \frac{1 - 9}{12} = \frac{-8}{12} = -\frac{2}{3}\n\]\n\n |
答案:
Thus, the answer is \(\boxed{A}\) :::
-
模型微调
- 选择基座模型,选择合适框架,如open_r1,用以上整理得到的蒸馏数据对基座模型进行微调
-
微调结果测试
- 用测试集和测试脚本来进行模型效果测试
本教程只包含第2步模型微调部分和第3步测试部分。
-
蒸馏数据为社区已经整理好的Bespoke-Stratos-17k
- 原始Berkeley Sky-T1数据集让DeepSeek R1填充思考过程,再经过筛选得到Bespoke-Stratos-17k。
-
基座模型选用Qwen2.5-Math-1.5B。
-
测试集选用aime_2024,MATH-500和gpqa。
2、蒸馏过程–一键启动版
2.1、环境准备
2.1.1、基础环境要求
-
硬件配置:8xC500 (也适用沐曦同系列产品C550)
-
操作系统:Ubuntu 20.04.3 LTS
-
软件版本:maca 2.29.0.3
2.1.2、数据和模型下载
mkdir ~/openr1_datas
下载基础模型:git clone https://www.modelscope.cn/Qwen/Qwen2.5-Math-1.5B.git
下载蒸馏数据:git clone https://huggingface.co/datasets/HuggingFaceH4/Bespoke-Stratos-17k
下载测试集:
git clone https://www.modelscope.cn/datasets/HuggingFaceH4/aime_2024.git
git clone https://www.modelscope.cn/datasets/HuggingFaceH4/MATH-500.git
git clone https://www.modelscope.cn/datasets/modelscope/gpqa.git
2.2、蒸馏过程–从头部署版
- 下载安装包
::: 下载沐曦带torch的镜像,如http://172.23.4.108/release/C500/Protein3.0/container/2.29.0.5/mxc500-torch2.1-py310-mc2.29.0.5-ubuntu22.04-amd64.container.xz :::
- 加载镜像
::: docker load -i mxc500-torch2.1-py310-mc2.29.0.5-ubuntu22.04-amd64.container.xz :::
- 容器的实例化
按照以下命令将指定的镜像id(<image_id>参数)实例化为指定名字的容器(–name 参数),需要映射的路径根据自己需要进行调整(<-v>参数)。如
::: docker run -it –device=/dev/dri –device=/dev/mxcd –group-add video –name openr1_sft –shm-size ’100gb’ -v /openr1_datas:~/openr1_datas mxc500-torch2.1-py310:mc2.29.0.5-ubuntu22.04-amd64 /bin/bash :::
- 克隆项目
::: git clone https://github.com/huggingface/open-r1.git :::
代码文件修改:
_deps = [
"accelerate>=1.2.1",
"bitsandbytes>=0.43.0",
"datasets>=3.2.0",
#"deepspeed==0.15.4",
"distilabel[vllm,ray,openai]>=1.5.2",
"einops>=0.8.0",
"flake8>=6.0.0",
#"flash_attn>=2.7.4.post1",
"hf_transfer>=0.1.4",
"huggingface-hub[cli]>=0.19.2,<1.0",
"isort>=5.12.0",
"latex2sympy2_extended>=1.0.6",
"liger_kernel==0.5.2",
"lighteval",#@ git+https://github.com/huggingface/lighteval.git@86f62259f105ae164f655e0b91c92a823a742724#egg=lighteval[math]",
"math-verify==0.5.2", # Used for math verification in grpo
"packaging>=23.0",
"parameterized>=0.9.0",
"pytest",
"ruff>=0.9.0",
"safetensors>=0.3.3",
"sentencepiece>=0.1.99",
#"torch==2.5.1",
"transformers",
"trl",
#"vllm==0.7.1",
"wandb>=0.19.1",
]
extras = {}
extras["tests"] = deps_list("pytest", "parameterized", "math-verify")
#extras["torch"] = deps_list("torch")
extras["quality"] = deps_list("ruff", "isort", "flake8")
extras["train"] = []# deps_list("flash_attn")
extras["eval"] = deps_list("lighteval", "math-verify")
extras["dev"] = extras["quality"] + extras["tests"] + extras["eval"] + extras["train"]
# core dependencies shared across the whole project - keep this to a bare minimum :)
install_requires = [
deps["accelerate"],
deps["bitsandbytes"],
deps["einops"],
deps["datasets"],
#deps["deepspeed"],
deps["hf_transfer"],
deps["huggingface-hub"],
deps["latex2sympy2_extended"],
deps["math-verify"],
deps["liger_kernel"],
deps["packaging"], # utilities from PyPA to e.g., compare versions
deps["safetensors"],
deps["sentencepiece"],
deps["transformers"],
deps["trl"],
]
-
环境安装
-
安装沐曦适配的vllm
-
安装沐曦适配的deepspeed
-
::: cd open-r1
pip install -e .[dev] :::
- 训练
可根据实际情况修改模型位置和数据集位置
::: accelerate launch –config_file=recipes/accelerate_configs/zero3.yaml src/open_r1/sft.py \
–model_name_or_path /openr1_datas/Qwen2.5-Math-1.5B \
–dataset_name /openr1_datas/Bespoke-Stratos-17k \
–learning_rate 2.0e-5 \
–num_train_epochs 1 \
–packing \
–max_seq_length 4096 \
–per_device_train_batch_size 1 \
–gradient_accumulation_steps 16 \
–gradient_checkpointing \
–bf16 \
–output_dir data/Qwen2.5-1.5B-Open-R1-Distill :::
- 测试
::: MODEL=data/Qwen2.5-1.5B-Open-R1-Distill
MODEL_ARGS=”pretrained=$MODEL,dtype=bfloat16,max_model_length=4096,gpu_memory_utilisation=0.8”
OUTPUT_DIR=data/evals/$MODEL
# AIME 2024
TASK=aime24
| lighteval vllm $MODEL_ARGS ”custom | $TASK | 0 | 0” \ |
–custom-tasks src/open_r1/evaluate.py \
–use-chat-template \
–output-dir $OUTPUT_DIR
# MATH-500
TASK=math_500
| lighteval vllm $MODEL_ARGS ”custom | $TASK | 0 | 0” \ |
–custom-tasks src/open_r1/evaluate.py \
–use-chat-template \
–output-dir $OUTPUT_DIR
# GPQA Diamond
TASK=gpqa:diamond
| lighteval vllm $MODEL_ARGS ”custom | $TASK | 0 | 0” \ |
–custom-tasks src/open_r1/evaluate.py \
–use-chat-template \
–output-dir $OUTPUT_DIR :::
2.3、蒸馏过程–一键启动版本
1、从沐曦habor上拉取镜像
::: docker pull ….. :::
2、加载镜像
::: docker load -i /path/to/image.tar :::
3、利用镜像创建容器,注意要把下载了模型和数据的路径映射进去
::: docker run -it –device=/dev/dri –device=/dev/mxcd –group-add video –name openr1_sft_tmp –shm-size ’100gb’ -v /openr1_datas:/openr1_datas openr1_sft:v0.1 /bin/bash :::
4、训练过程
::: cd /open-r1
bash train.sh :::
训练一个epoch时间估计在3h左右
输出以下日志表示正常进入训练流程

5、测试过程
::: bash eval.sh :::
输出示例:



全套测试时间估计在20min左右。如上图就表示三个数据集的pass@1指标分别是6.67/45.5/28.79。
3、蒸馏结果
3.1、测试集说明
| 测试集 | 测试集说明 |
|---|---|
| aime24 | 美国数学竞赛题30题 |
| math_500 | 数学题500题 |
| gpqa:diamond | 生物化学物理题198题 |
3.2、预期测试结果
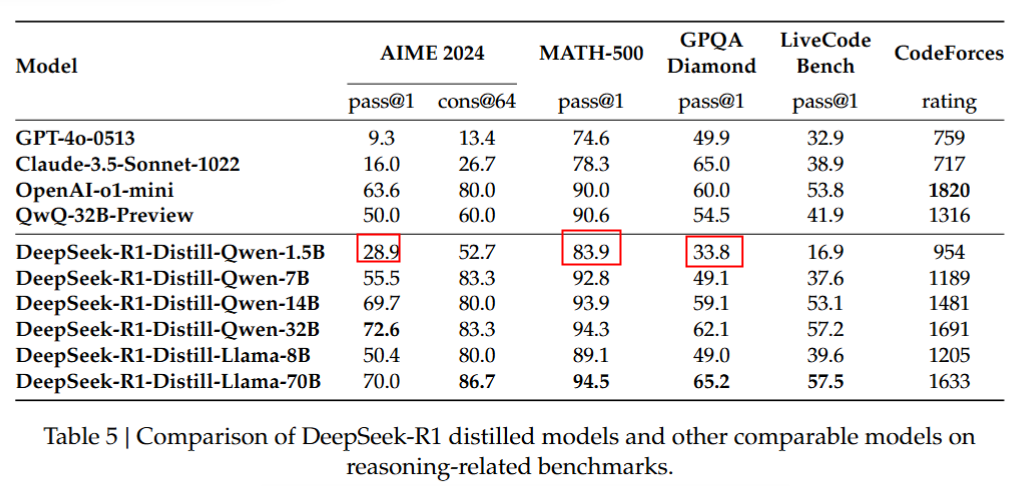
| 测试结果(%) | Qwen2.5-Math-1.5B | Qwen2.5-1.5B-Open-R1-Distill | Qwen2.5-Math-1.5B_ours_1epoch |
|---|---|---|---|
| aime_2024 | 3.33 | 30(paper28.9) | 6.67 |
| MATH-500 | 23.6 | 83(paper 83.9) | 45.4 |
| GPQA Diamond | 25.75 | 32.83(paper 33.8) | 28.79 |
-
Qwen2.5-Math-1.5B列表示蒸馏前模型的效果
-
Qwen2.5-1.5B-Open-R1-Distill:是下载的官方给出的80万数据蒸馏出的模型DeepSeek-R1-Distill-Qwen-1.5B(https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B),这里记录模型在当前的测试脚本里测试的结果,括号里的paper是该模型在文章里的测试结果,会有一定随机性。此列表明测试脚本的正确性。
-
Qwen2.5-Math-1.5B_ours_1epoch:表示训练到1个epoch的效果
可以观察到,Qwen模型经过1个epoch蒸馏后,在推理测试集上的效果明显好于蒸馏前,即模型获得了更强的推理能力。
3.3、 总结
得益于DeepSeekR1的思考过程数据,蒸馏后的Qwen模型相比于蒸馏前模型,在推理测试集上效果提升明显。受限于训练轮数和训练数据,还未能完全到达论文中的效果,后续有很大优化空间。
此文档仅作为方法指导,数据集和基座模型可按照需要进行替换。e