cuda入门
参考B站CUDA编程基础入门系列(持续更新)的学习笔记
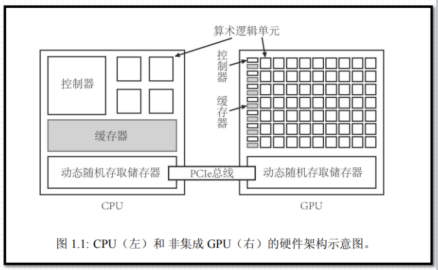
CPU+GPU异构架构
GPU不能单独计算, CPU+GPU组成异构计算架构;CPU起到控制作用, 一般称为主机(Host) ; GPU可以看作CPU的协处理器, 一般称为设备(Device) ;主机和设备之间内存访问一般通过PCIe总线链接。
查询GPU详细信息
查询GPU详细信息 nvidia-smi –q
查询特定GPU详细信息 nvidia-smi –q –I 0
显示GPU特定信息 nvidia-smi –q –I 0 –d MEMORY
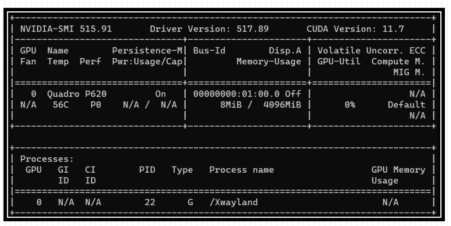
1、NVIDIA-SMI版本号
2、 Driver Version:驱动版本号
3、 CUDA Version:CUDA版本号
4、 GPU型号及序号
5、 风扇
6、 温度
7、 Perf性能状态
8、 Persistence-M:持续模式状态
9、 Pwr:Usage/Cap:表示显卡功率
10、 Bus-Id:总线
11、 Disp.A: Display Active,表示GPU是否初始化
12、 Memory-Usage:显存使用率
13、 Volatile GPU-UTil: GPU使用率
14、 ECC:是否开启错误检查和纠错技术,
0/DISABLED, 1/ENABLED
15、 Compute M:计算模式
CUDA核函数
- 核函数 (Kernel function)
1、核函数在GPU上进行并行执行
2、 注意:(1) 限定词__global__ 修饰(2) 返回值必须是void
1、 核函数只能访问GPU内存
2、 核函数不能使用变长参数
3、 核函数不能使用静态变量
4、 核函数不能使用函数指针
5、 核函数具有异步性
3、 形式:
(1) __global__ void kernel_function(argument arg)
{
printf(“Hello World from the GPU!\n”);
}
(2) void __global__ kernel_function(argument arg)
{
printf(“Hello World from the GPU!\n”);
}
-
CUDA程序编写流程
int main(void) { 主机代码 核函数调用 主机代码 return 0; } 注意:核函数不支持C++的iostream
CUDA线程模型
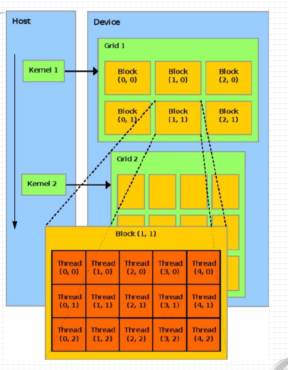
01 线程模型结构
1、 线程模型重要概念: (1) grid 网格(2) block 线程块
2、 线程分块是逻辑上的划分, 物理上线程不分块
3、 配置线程: «<grid_size, block_size»>
4、 最大允许线程块大小: 1024最大允许网格大小: 2^{31} - 1 (针对一维网格)
02 线程组织管理
1、 每个线程在核函数中都有一个唯一的身份标识;
2、 每个线程的唯一标识由这两个«<grid_size, block_size»>确定; grid_size, block_size保存在内建变量(build-in variable) , 目前考虑的是一维的情况:(1) gridDim.x:该变量的数值等于执行配置中变量grid_size的值;(2) blockDim.x:该变量的数值等于执行配置中变量block_size的值。
3、 线程索引保存成内建变量( build-in variable) :(1) blockIdx.x:该变量指定一个线程在一个网格中的线程块索引值, 范围为0~ gridDim.x-1;(2) threadIdx.x:该变量指定一个线程在一个线程块中的线程索引值, 范围为0~ blockDim.x-1。
03 网格和线程块限制
网格大小限制:
gridDim.x 最大值———— 231 - 1
gridDim.y 最大值———— 216 - 1
gridDim.z 最大值———— 216 - 1
线程块大小限制:
blockDim.x 最大值———— 1024
blockDim.y 最大值———— 1024
blockDim.z 最大值———— 64
注意:线程块总的大小最大为1024!!
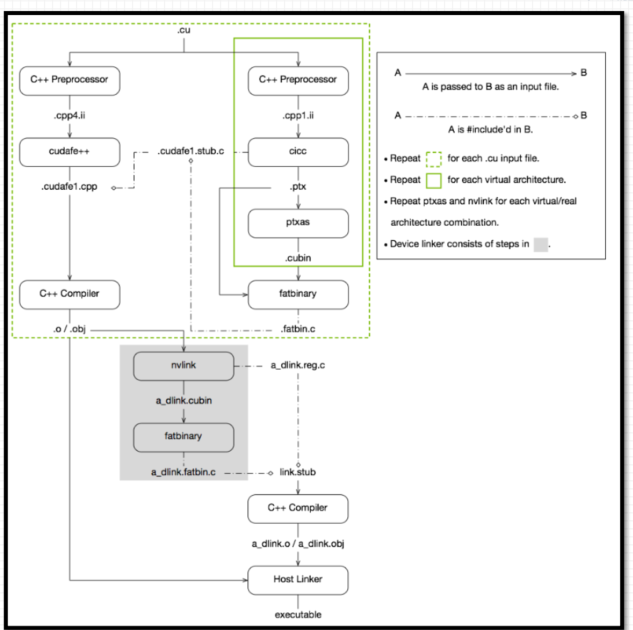
nvcc编译流程与GPU计算能力
nvcc编译流程
1、 nvcc分离全部源代码为: (1) 主机代码 (2) 设备代码
2、 主机(Host) 代码是C/C++语法, 设备(device) 代码是C/C++扩展语言编写
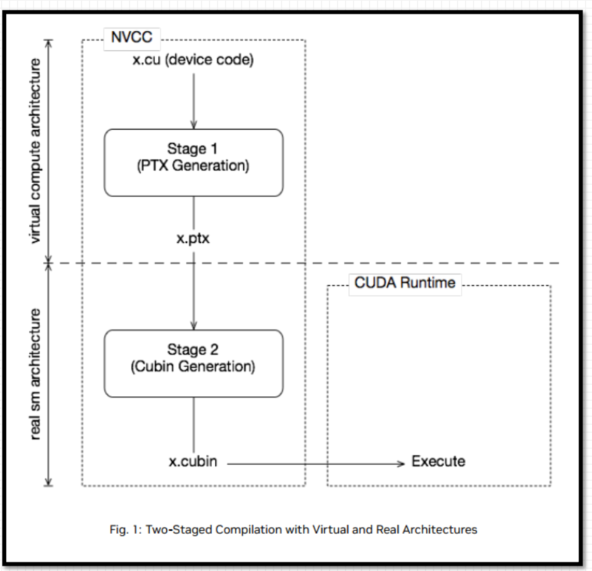
3、 nvcc先将设备代码编译为PTX(Parallel Thread Execution) 伪汇编代码, 再将PTX代码编译为二进制的cubin目标代码
4、 在将源代码编译为 PTX 代码时, 需要用选项-arch=compute_XY指定一个虚拟架构的计算能力,用以确定代码中能够使用的CUDA功能。
5、 在将PTX代码编译为cubin代码时, 需要用选项-code=sm_ZW指定一个真实架构的计算能力, 用以确定可执行文件能够使用的GPU
PTX
PTX( Parallel Thread Execution) 是CUDA平台为基于GPU的通用计算而定义的虚拟机和指令集
nvcc编译命令总是使用两个体系结构:一个是虚拟的中间体系结构, 另一个是实际的GPU体系结构
虚拟架构更像是对应用所需的GPU功能的声明
虚拟架构应该尽可能选择低—-适配更多实际GPU真实架构应该尽可能选择高—-充分发挥GPU性能
GPU架构与计算能力
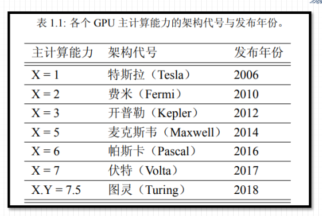
1、每款GPU都有用于标识“计算能力”( compute capability )的版本号
2、形式X.Y, X标识主版本号, Y表示次版本号

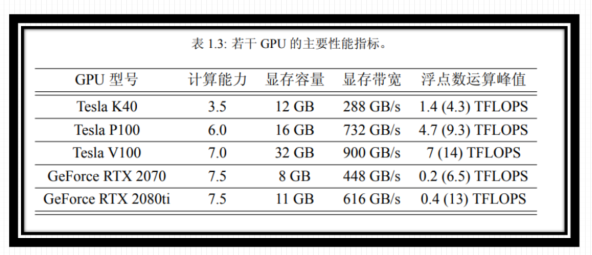
并非GPU 的计算能力越高,性能就越高
CUDA程序兼容性问题
指定虚拟架构计算能力
C/C++源码编译为PTX时, 可以指定虚拟架构的计算能力, 用来确定代码中能够使用的CUDA功能
C/C++源码转化为PTX这一步骤与GPU硬件无关
编译指令(指定虚拟架构计算能力) :-arch=compute_XYXY: 第一个数字X代表计算能力的主版本号, 第二个数字Y代表计算能力的次版本号
PTX的指令只能在更高的计算能力的GPU使用
例如:nvcc helloworld.cu –o helloworld -arch=compute_61 编译出的可执行文件helloworld可以在计算能力>=6.1的GPU上面执行, 在计算能力小于6.1的GPU则不能执行。
PTX指令转化为二进制cubin代码与具体的GPU架构有关
编译指令(指定真实架构计算能力) :
-code=sm_XY XY: 第一个数字X代表计算能力的主版本号, 第二个数字Y代表计算能力的次版本号注意: (1) 二进制cubin代码, 大版本之间不兼容!!!(2) 指定真实架构计算能力的时候必须指定虚拟架构计算能力!!!(3) 指定的真实架构能力必须大于或等于虚拟架构能力!!!
真实架构可以实现低小版本到高小版本的兼容!
使得编译出来的可执行文件可以在多GPU中执行
同时指定多组计算能力:
编译选项 -gencode arch=compute_XY –code=sm_XY
编译出的可执行文件包含4个二进制版本, 生成的可执行文件称为胖二进制文件(fatbinary)
注意: (1) 执行上述指令必须CUDA版本支持7.0计算能力, 否则会报错(2) 过多指定计算能力, 会增加编译时间和可执行文件的大小
nvcc即时编译
在运行可执行文件时, 从保留的PTX代码临时编译出cubin文件
在可执行文件中保留PTX代码, nvcc编译指令指定所保留的PTX代码虚拟架构:
指令: -gencode arch=compute_XY ,code=compute_XY
注意: (1) 两个计算能力都是虚拟架构计算能力(2) 两个虚拟架构计算能力必须一致
例如: -gencode=arch=compute_35,code=sm_35 -gencode=arch=compute_50,code=sm_50 -gencode=arch=compute_61,code=sm_61 -gencode=arch=compute_61,code=compute_61简化: -arch=sm_XY等价于
-gencode=arch=compute_61,code=sm_61
-gencode=arch=compute_61,code=compute_61
nvcc编译默认计算能力
不同版本CUDA编译器在编译CUDA代码时, 都有一个默认计算能力
CUDA 6.0及更早版本: 默认计算能力1.0 CUDA 6.5~~~CUDA 8.0: 默认计算能力2.0 CUDA 9.0~~~CUDA 10.2: 默认计算能力3.0 CUDA 11.6: 默认计算能力5.2
CUDA矩阵加法运算程序
CUDA程序基本框架
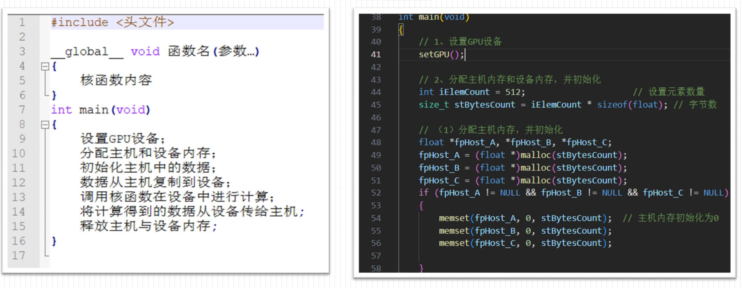
设置GPU设备
1、 获取GPU设备数量代码:int iDeviceCount = 0; cudaGetDeviceCount(&iDeviceCount);

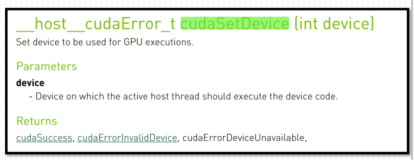
2、 设置GPU执行时使用的设备代码:int iDev = 0;cudaSetDevice(iDev)
内存管理
CUDA 通过内存分配、 数据传递、 内存初始化、 内存释放进行内存管理
内存分配
主机分配内存: extern void *malloc(unsigned int num_bytes);
代码: float *fpHost_A;fpHost_A = (float *)malloc(nBytes);
设备分配内存:
代码: float *fpDevice_A; cudaMalloc((float**)&fpDevice_A, nBytes);

数据拷贝
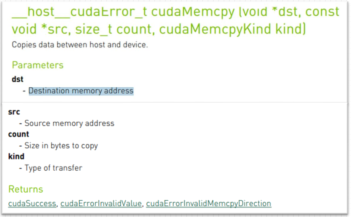
主机数据拷贝: void memcpy(void *dest, const void *src, size_t n);
代码: memcpy((void)d, (void)s, nBytes);
设备数据拷贝:
代码: cudaMemcpy(Device_A, Host_A, nBytes, cudaMemcpyHostToHost)

内存初始化
主机内存初始化: void *memset(void *str, int c, size_t n);
代码:memset(fpHost_A, 0, nBytes);
设备内存初始化:
代码:cudaMemset(fpDevice_A, 0, nBytes);
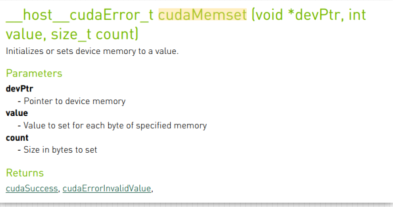
内存释放
释放主机内存:代码:free(pHost_A);
释放设备内存:代码:cudaFree(pDevice_A);
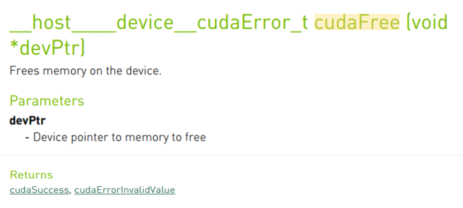
自定义设备函数
1、 设备函数(device function)(1) 定义只能执行在GPU设备上的函数为设备函数(2) 设备函数只能被核函数或其他设备函数调用(3) 设备函数用 device 修饰
2、 核函数(kernel function)(1) 用 global 修饰的函数称为核函数, 一般由主机调用, 在设备中执行(2) global 修饰符既不能和__host__同时使用, 也不可与__device__ 同时使用
3、 主机函数(host function)(1) 主机端的普通 C++ 函数可用 host 修饰(2) 对于主机端的函数, host__修饰符可省略(3) 可以用 __host 和 device 同时修饰一个函数减少冗余代码。 编译器会针对主机和设备分别编译该函数。
CUDA错误检查
运行时API错误代码
1、 CUDA运行时API大多支持返回错误代码, 返回值类型: cudaError_t
2、 运行时API成功执行, 返回值为cudaSuccess
3、 运行时API返回的执行状态值是枚举变量

错误检查函数
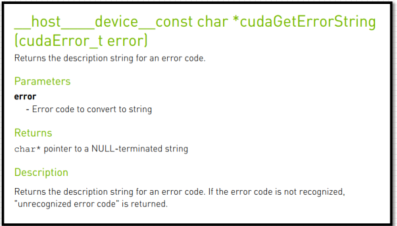
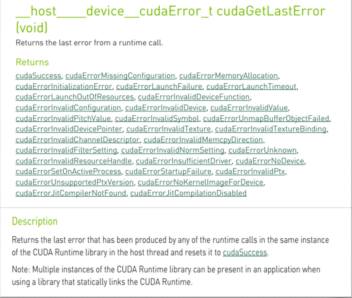
1、 获取错误代码对应名称: cudaGetErrorName

2、 获取错误代码描述信息: cudaGetErrorString
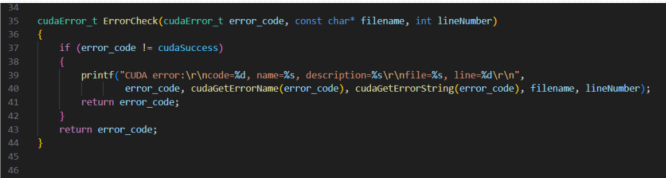
1、 在调用CUDA运行时API时, 调用ErrorCheck函数进行包装
2、 参数filename一般使用__FILE__; 参数lineNumber一般使用__LINE__
3、 错误函数返回运行时API调用的错误代码
检查核函数
错误检测函数问题:不能捕捉调用核函数的相关错误
捕捉调用核函数可能发生错误的方法:ErrorCheck(cudaGetLastError(), FILE, LINE); ErrorCheck(cudaDeviceSynchronize(), FILE, LINE);
核函数定义:global void kernel_function(argument arg);
CUDA记时
事件记时
1、 程序执行时间记时:是CUDA程序执行性能的重要表现2、 使用CUDA 事件(event) 记时方式3、 CUDA 事件记时可为主机代码、 设备代码记时
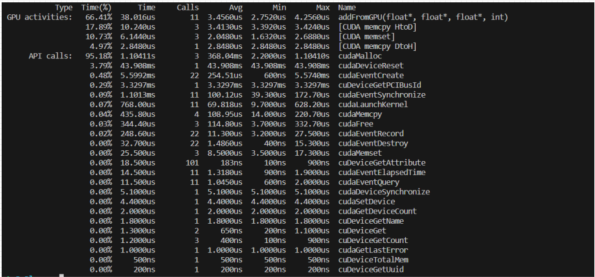
nvprof性能刨析
1、 nvprof是一个可执行文件2、 执行命令: nvprof ./exe_name
运行时GPU信息查询
运行时API查询GPU信息
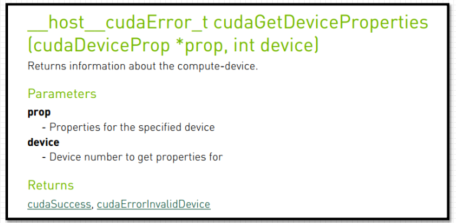
涉及的运行时API函数
调用: cudaDeviceProp prop;ErrorCheck(cudaGetDeviceProperties(&prop, device_id), FILE, LINE);
查询GPU计算核心数量
1、 CUDA运行时API函数是无法查询GPU核心数量的(起码我不知道应该用哪一个运行时API函数进行查询)2、 根据GPU的计算能力进行查询
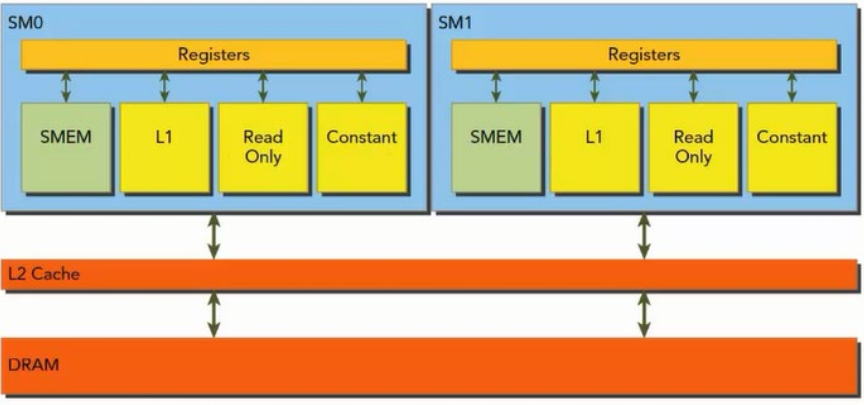
GPU硬件资源
流多处理器–SM
GPU并行性依靠流多处理器SM(streaming multiprocessor)来完成
一个GPU是由多个SM构成的, Fermi架构SM关键资源如下:
1、 CUDA核心(CUDA core)
2、 共享内存/L1缓存(shared memory/L1 cache)
3、 寄存器文件(RegisterFile)
4、 加载和存储单元(Load/Store Units)
5、 特殊函数单元(Special Function Unit)
6、 Warps调度(Warps Scheduler)

GPU中每个SM都可以支持数百个线程并发执行
以线程块block为单位, 向SM分配线程块, 多个线程块可被同时分配到一个可用的SM上
当一个线程块被分配好SM后, 就不可以在分配到其他SM上了
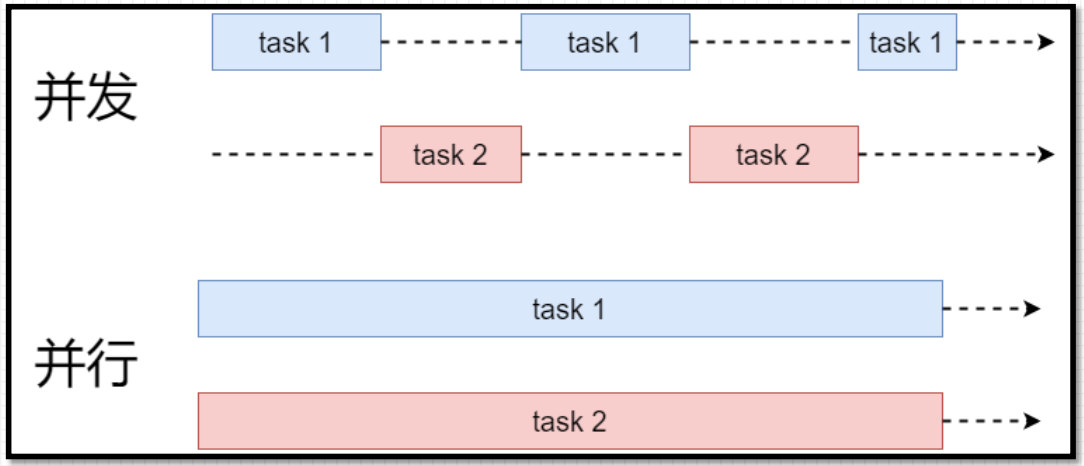
线程模型与物理结构
左图线程模型, 是在逻辑角度进行分析
右图物理结构, 是在硬件角度进行分析, 因为硬件资源是有限的, 所以活跃的线程束的数量会受到SM资源限制。
线程模型可以定义成千上万个线程
网格中的所有线程块需要分配到SM上进行执行
线程块内的所有线程分配到同一个SM中执行,但是每个SM上可以被分配多个线程块
线程块分配到SM中后, 会以32个线程为一组进行分割, 每个组成为一个wrap
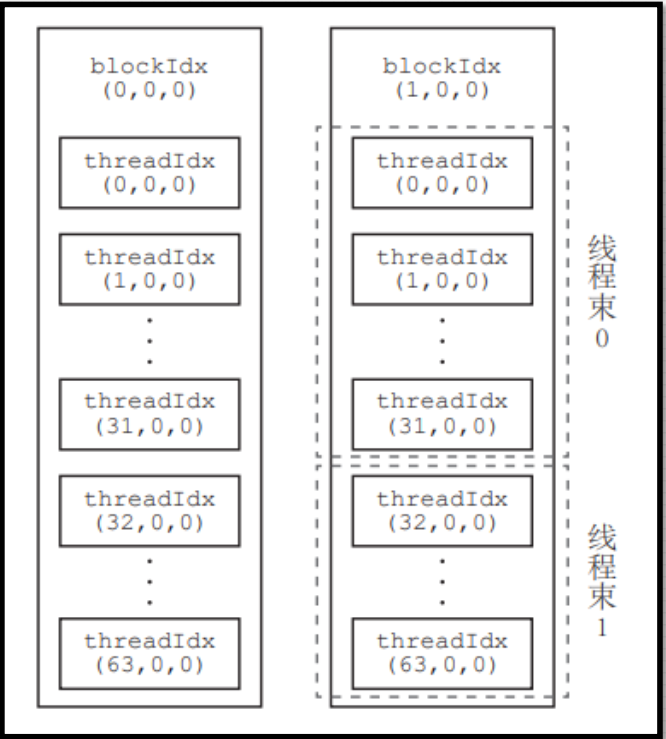
线程束
什么是线程束?
CUDA 采用单指令多线程SIMT架构管理执行线程,每32个为一组,构成一个线程束。同一个线程块中相邻的 32个线程构成一个线程束具体地说,一个线程块中第 0 到第 31 个线程属于第 0 个线程束,第 32 到第 63 个线程 属于第 1 个线程束,依此类推。
每个线程束中只能包含同一线程块中的线程
每个线程束包含32个线程
线程束是GPU硬件上真正的做到了并行
线程束数量 = ceil(线程块中的线程数/32)
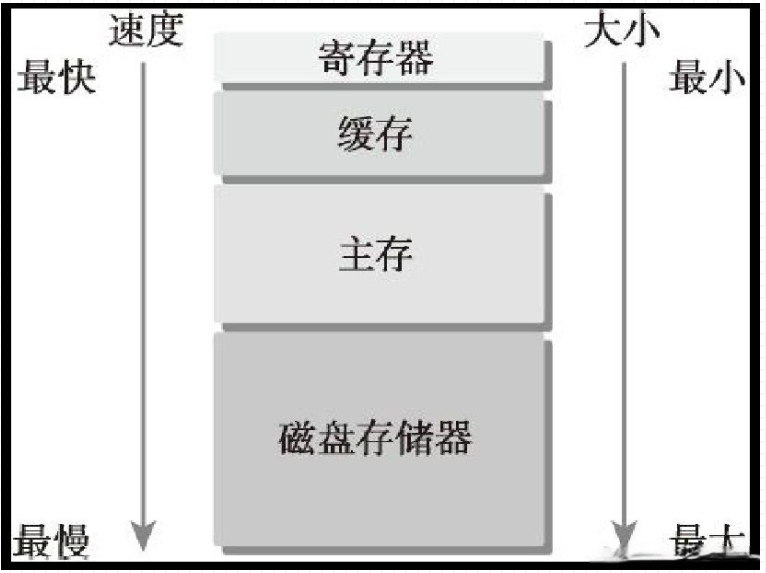
CUDA内存模型
内存结构层次特点
局部性原则:时间局部性空间局部性
如图, 底部存储器特点:
1、 更低的每比特位平均成本
2、 更高的容量
3、 更高的延迟
4、 更低的处理器访问频率
CPU和GPU主存采用DRAM(动态随机存取存储器)低延迟的内存采用SRAM(静态随机存取存储器)
CUDA内存模型
寄存器(register)共享内存(shared memory)本地内存(local memory )常量内存(constant memory )纹理内存(texture memory)全局内存(global memory)
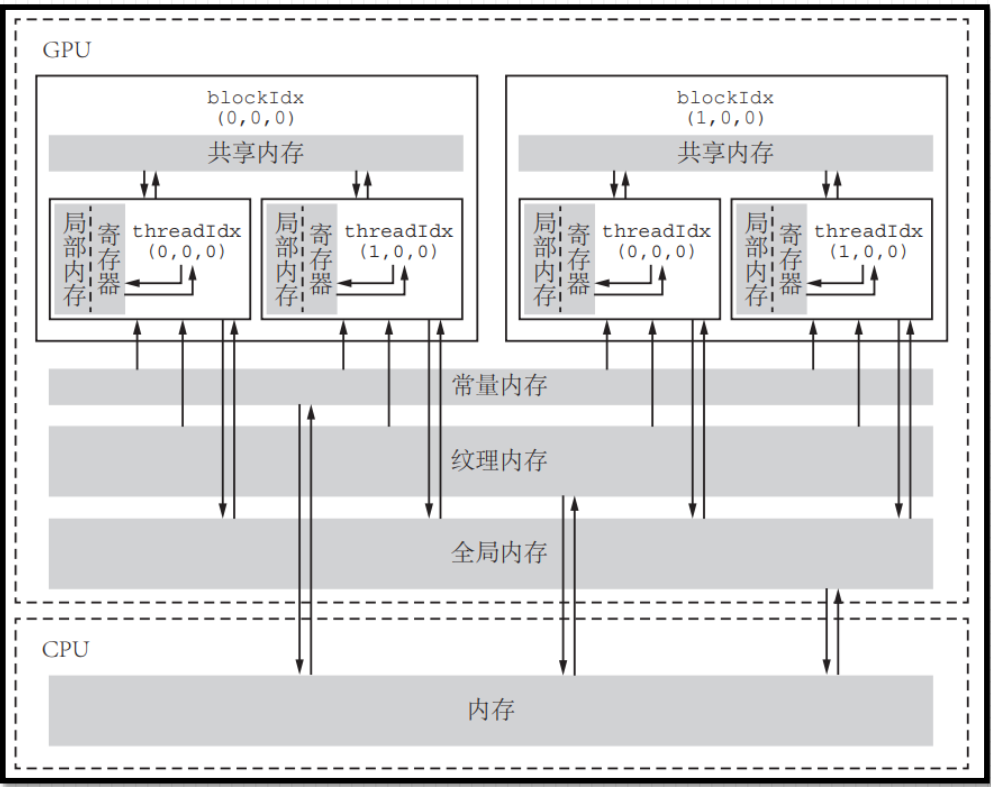
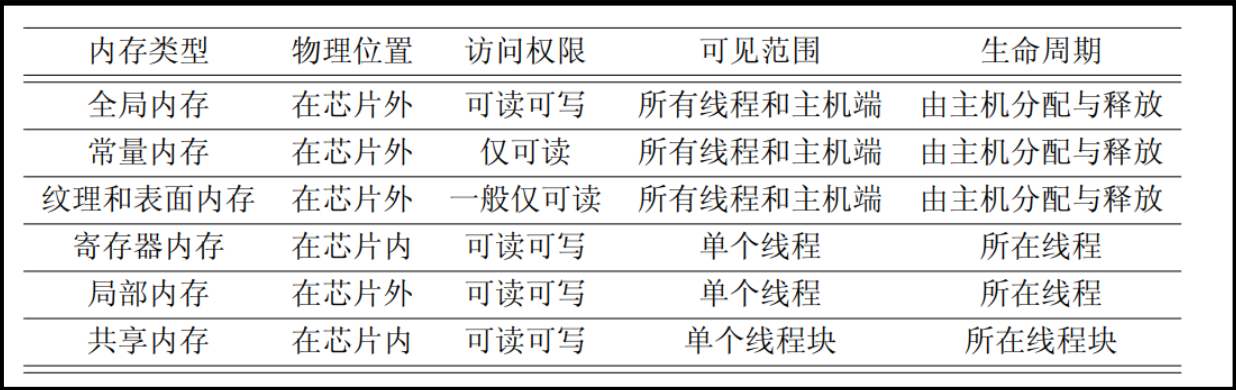
寄存器
寄存器内存在片上(on-chip) , 具有GPU上最快的访问速度, 但是数量有限, 属于GPU的稀缺资源;
核函数中定义的不加任何限定符的变量一般存放在寄存器中;
内 建 变 量 存 放 于 寄 存 器 中 , 如 gridDim 、blockDim、 blockIdx等;
寄存器仅可在线程内可见, 生命周期也与所属线程一致;
核函数中定义的不加任何限定符的数组有可能存在于寄存器中, 但也有可能存在于本地内存中;
寄存器都是32位的, 保存1个double类型的数据需要两个寄存器, 寄存器保存在SM的寄存器文件;
计算能力5.0~9.0的GPU, 每个SM中都是64K的寄存器数量, Fermi架构只有32K;
每个线程块使用的最大数量不同架构是不同的,计算能力6.1是64K;
每个线程的最大寄存器数量是255个, Fermi架构是63个;
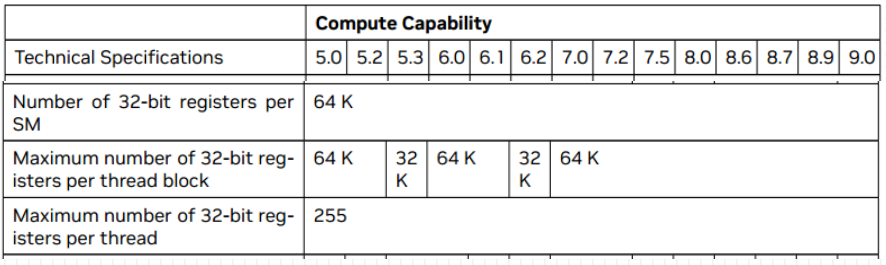
本地内存
寄存器放不下的内存会存放在本地内存:
1、 索引值不能在编译时确定的数组存放于本地内存:
2、 可能占用大量寄存器空间的较大本地结构体和数组;
3、 任何不满足核函数寄存器限定条件的变量。
每个线程最多高达可使用512KB的本地内存
本地内存从硬件角度看只是全局内存的一部分, 延迟也很高, 本地内存的过多使用, 会减低程序的性能。
对于计算能力2.0以上的设备, 本地内存的数据存储在每个SM的一级缓存和设备的二级缓存中

寄存器溢出
核函数所需的寄存器数量超出硬件设备支持, 数据则会保存到本地内存(local memory) 中:
1、 一个SM运行并行运行多个线程块/线程束, 总的需求寄存器容量大于64KB;
2、 单个线程运行所需寄存器数量个255个;
寄存器溢出会降低程序运行性能:
1、 本地内存只是全局内存的一部分, 延迟较高;
2、 寄存器溢出的部分也可进入GPU的缓存中;
共享内存
共享内存作用
共享内存在片上(on-chip) , 与本地内存和全局内存相比具有更高的带宽和更低的延迟;
使用__shared__修饰的变量存放于共享内存中,共享内存可定义动态与静态两种;
每个SM的共享内存数量是一定的, 也就是说,如果在单个线程块中分配过度的共享内存, 将会限制活跃线程束的数量;
共享内存中的数据在线程块内所有线程可见,可用线程间通信, 共享内存的生命周期也与所属线程块一致;
访问共享内存必须加入同步机制:线程块内同步 void __syncthreads();
不同计算能力的架构, 每个SM中拥有的共享内存大小是不同的;
每个线程块使用的最大数量不同架构是不同的, 计算能力8.9是100K;
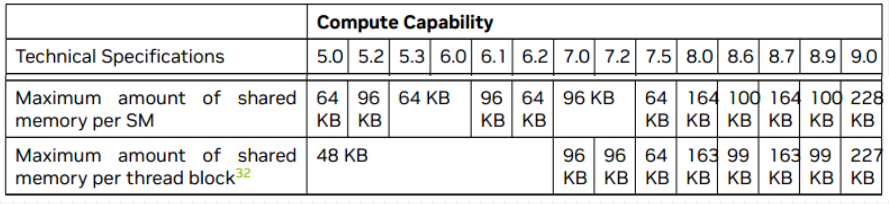
经常访问的数据由全局内存(global memory) 搬移到共享内存(shared memory) , 提高访问效率;
改变全局内存访问内存的内存事务方式, 提高数据访问的带宽。
共享内存变量修饰符: shared
静态共享内存声明: shared float tile[size, size];
静态共享内存作用域:1、 核函数中声明, 静态共享内存作用域局限在这个核函数中;2、 文件核函数外声明, 静态共享内存作用域对所有核函数有效。
静态共享内存在编译时就要确定内存大小
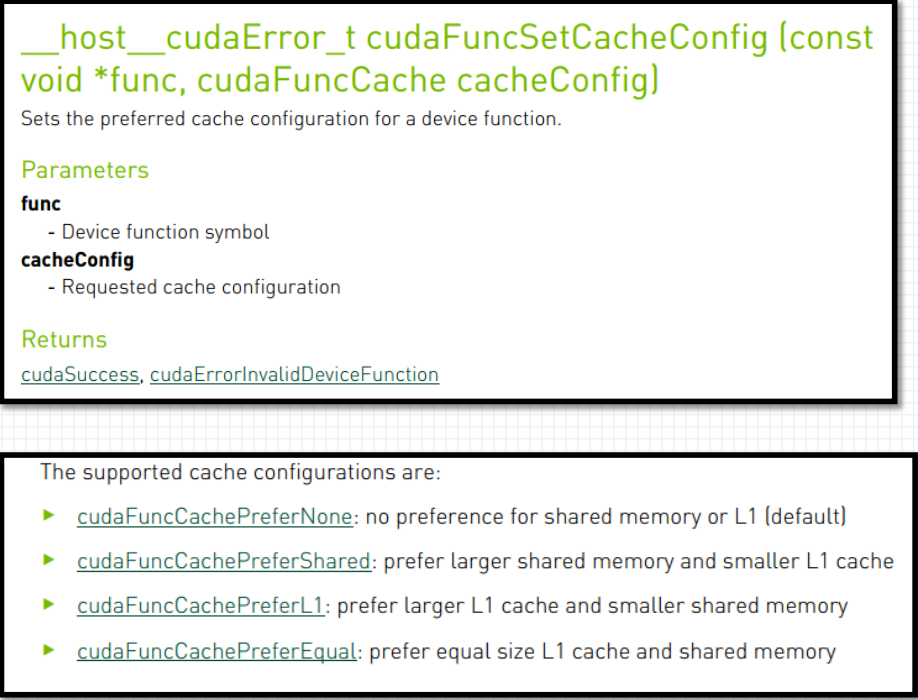
共享内存和一级缓存划分
在L1缓存和共享内存使用相同硬件资源的设备上, 可通过cudaFuncSetCacheConfig运行时API指定设置首选缓存配置;
func必须是声明为__global__的函数;
在L1缓存和共享内存大小固定的设备上, 此设置不起任何作用;
全局内存
全局内存在片外。特点:容量最大, 延迟最大, 使用最多;
全局内存中的数据所有线程可见, Host端可见,且具有与程序相同的生命周期;
全局内存初始化
动态全局内存:
主机代码中使用CUDA运行时API cudaMalloc动态声明内存空间, 由cudaFree释放全局内存。
静态全局内存:
使用__device__关键字静态声明全局内存。


常量内存作用
常量内存是有常量缓存的全局内存, 数量有限,大小仅为64KB, 由于有缓存, 线程束在读取相同的常量内存数据时, 访问速度比全局内存快;
使用__constant__修饰的变量存放于常量内存中, 不能定义在核函数中, 且常量内存是静态定义的;
常量内存仅可读, 不可写;
常量内存中的数据对同一编译单元内所有线程可见;
给核函数传递数值参数时, 这个变量就存放于常量内存
静态共享内存
常量内存必须在主机端使用cudaMemcpyToSymbol进行初始化;
线程束中所有线程从相同内存地址中读取数据时, 常量内存表现最好, 例如数学公式中的系数, 因为线程束中所有的线程都需要读取同一个地址空间的系数数据, 因此只需要读取一次, 广播给线程束中的所有线程。


GPU缓存
GPU缓存种类
一级缓存(L1) ;二级缓存(L2) ;只读常量缓存;只读纹理缓存;
GPU缓存是不可编程的内存;
L1缓存和L2缓存用来存储本地内存( local memory) 和全局内存(global memory) 的数据, 也包括寄存器溢出的部分;
在GPU上只有内存加载可以被缓存, 内存存储操作不能被缓存;
每个SM都有一个一级缓存, 所有SM共享一个二级缓存;
每个SM有一个只读常量缓存和只读纹理缓存,它们用于在设备内存中提高来自各自内存空间内的读取性能。
L1缓存查询与设置
GPU全局内存是否支持L1缓存查询指令: cudaDeviceProp::globalL1CacheSupported
默认情况下, 数据不会缓存在统一的L1/纹理缓存中, 但可以通过编译指令启用缓存:
开启: -Xptxas -dlcm=ca除了带有禁用缓存修饰符的内联汇编修饰的数据外, 所有读取都将被缓存;
开启: -Xptxas -fscm=ca所有数据读取都将被缓存。
L1缓存与共享内存
计算能力为8.9的显卡为例:
1) 统一数据缓存大小为128KB, 统一数据缓存包括共享内存、 纹理内存和L1缓存;
2) 共享内存从统一的数据缓存中分区出来, 并且可以配置为各种大小, 共享内存容量可设置为0, 8, 16, 32, 64和100KB, 剩下的数据缓存用作L1缓存, 也可由纹理单元使用;
3) L1缓存与共享内存大小是可以进行配置的, 但不一定生效, GPU会自动选择最优的配置。
L1缓存与共享内存
伏特架构(计算能力7.0) :统一数据缓存大小为128KB, 共享内存容量可以设置为0、 8、 16、32、 64或96KB;
图灵架构(计算能力7.5) :统一数据缓存大小为96KB, 共享内存容量可以设置为32KB或64KB;
安培架构(计算能力8.0) :统一数据缓存大小为192KB, 共享内存容量可以设置为0、 8、 16、32、 64、 100、 132或164KB.
计算资源分配
线程执行资源分配
线程束本地执行上下文主要资源组成: 1) 程序计数器;2) 寄存器; 3) 共享内存;
SM处理的每个线程束计算所需的计算资源属于片上(on-chip) 资源, 因此从一个执行上下文切换到另一个执行上下文是没有时间损耗的。
对于一个给定的内核, 同时存在于同一个SM中的线程块和线程束数量取决于在SM中可用的内核所需寄存器和共享内存数量。
寄存器对线程数目的影响
每个线程消耗的寄存器越多, 则可以放在一个SM中的线程束就越少;
如果减少内核消耗寄存器的数量, SM便可以同时处理更多的线程束;
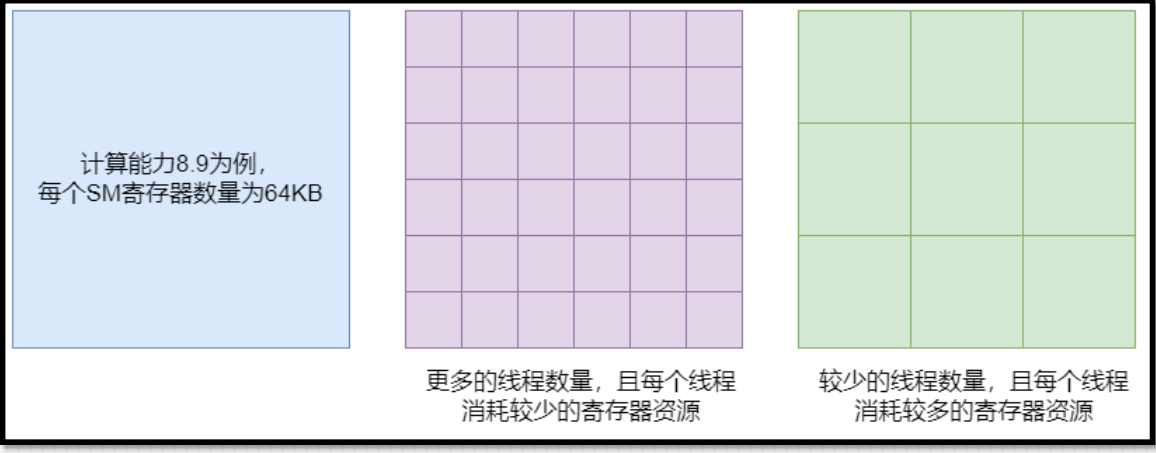
共享内存对线程块数量的影响
一个线程块消耗的共享内存越多, 则在一个SM中可以同时处理的线程块就会变少;
如果每个线程块使用的共享内存数量变少, 那么可以同时处理更多的线程块。

SM占有率
当计算资源(如寄存器和共享内存) 已分配给线程块时, 线程块被称为活跃的块, 线程块所包含的线程束被称为活跃的线程束, 活跃线程束可分为以下3种类型:1) 选定的线程束; 2) 阻塞的线程束; 3) 符合条件的线程束。
占用率是每个SM中活跃的线程束占最大线程束的比值:占用率=活跃线程束数量/最大线程束数量
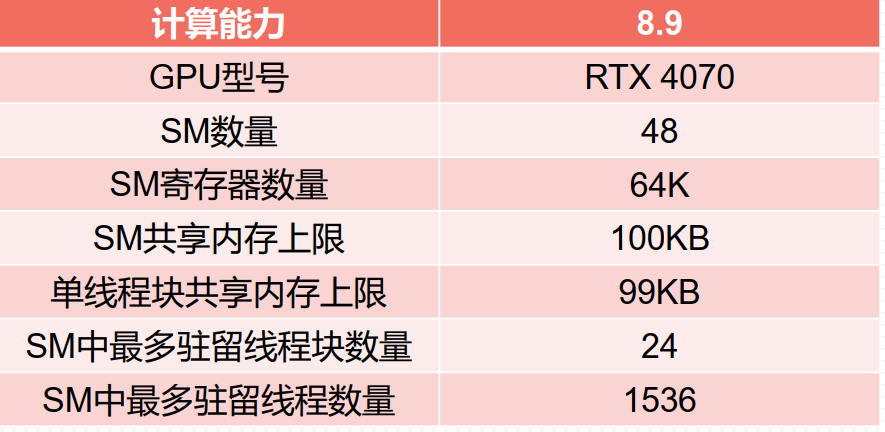
计算能力8.9为例:
1)一个SM最多拥有的线程块个数为Nb=24; 2)一个SM最多拥有的线程个数为Nt=1536;
并行性规模足够大(即核函数执行配置中定义的总线程足够多)的前提下分析SM占有率: 1)寄存器和共享内存使用很少的情况,线程块不小于64(Nt/Nb)时,可以获得100%的占有率;2)有限寄存器对占有率的影响,当在SM上驻留最多的线程1536个,核函数中每个线程最多使用42个寄存器;3)有限共享内存对占有率的影响,若线程块大小定义为64,每个SM需要激活24个线程块才能拥有1536个线程,达到100%的利用率每个线程块可分配4.16KB的共享内存。
注意:如果一个线程块需要使用的共享内存超过了99KB,会导致核函数无法启动。
网格和线程块大小的准则: 1)保持每个线程块中线程数量是线程束大小的倍数; 2)线程块不要设计的太小; 3)根据内核资源调整线程块的大小; 4)线程块的数量要远远大于SM的数量,保证设备有足够的并行;
延迟隐藏
指令延迟:在指令发出和完成之间的时钟周期被定义为指令延迟;
当每个时钟周期中所有线程束调度器都有一个符合条件的线程束时, 可以达到计算资源的完全利用;
GPU的指令延迟被其他线程束的计算隐藏称为延迟隐藏;
指令可以被分为两种基本类型: 1) 算数指令; 2) 内存指令。
算术指令隐藏
算数运算指令延迟是从开始运算到得到计算结果的时钟周期, 通常为4个时钟周期;
满足延迟隐藏所需的线程束数量, 利用利特尔法则可以合理提供一个估计值:所需线程束数量 = 延迟 × 吞吐量
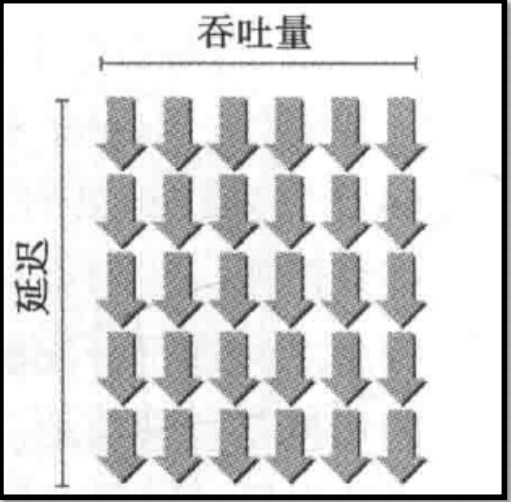
算术指令隐藏
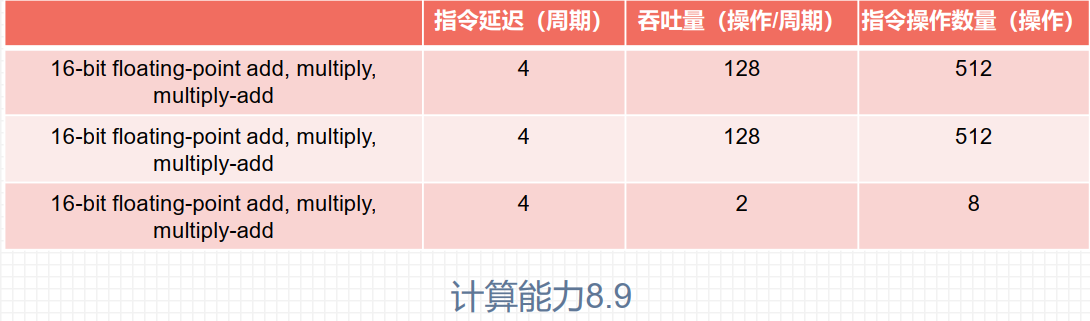
算数运算指令延迟是从开始运算到得到计算结果的时钟周期, 通常为4个时钟周期;
吞吐量是SM中每个时钟周期的操作数量确定的,
16-bit 所需线程束数量 = 512 / 32 = 16
32-bit 所需线程束数量 = 512 / 32 = 16
16-bit 所需线程束数量 = 8 / 32 = 1 (8个操作也需要1个线程束)
提升算数指令并行性方法: 1) 线程中更多独立指令; 2) 更多并发线程
内存指令隐藏
内存访问指令延迟是从命令发出到数据到达目的地的时钟周期, 通常为400~800个时钟周期;
对内存操作来说, 其所需的并行可以表示为在每个时钟周期内隐藏内存延迟所需的字节数;
假设每个线程都把一个浮点数(4字节) 从全局内存移动到SM中进行计算, 则至少需要10000线程或者313个线程束来隐藏所有内存延迟;
39KB ÷4/线程 ≈ 10000个线程
10000个线程 ÷ 32个线程/线程束 ≈ 313个线程束

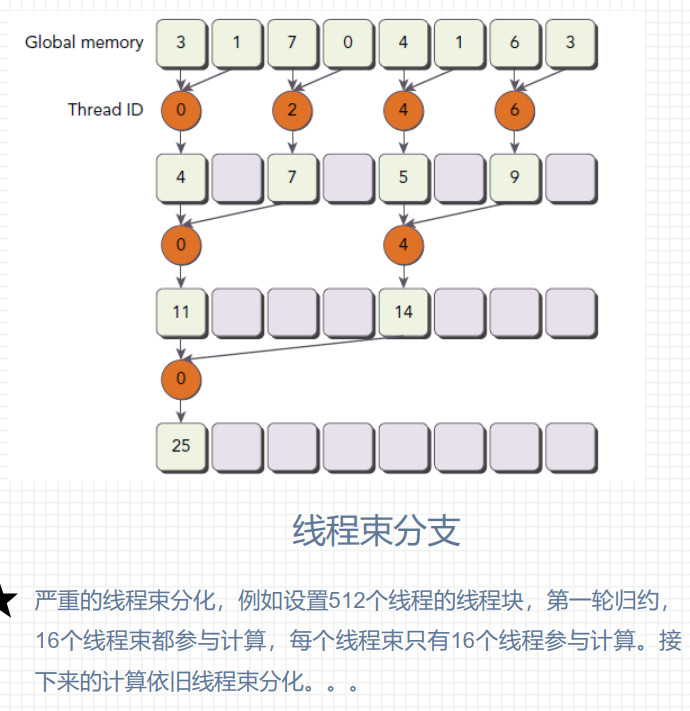
避免线程束分化
线程束分支
GPU支持传统的、 C/C++风格的显式控制流结构, 如if…then…else for和while;
GPU是相对简单的设备, 没有复杂的分支预测机制;
一个线程束中的所有线程在同一个周期中必须执行相同的指令;
如果同一个线程束中的线程执行不同分支的指令, 则会造成线程束分支;
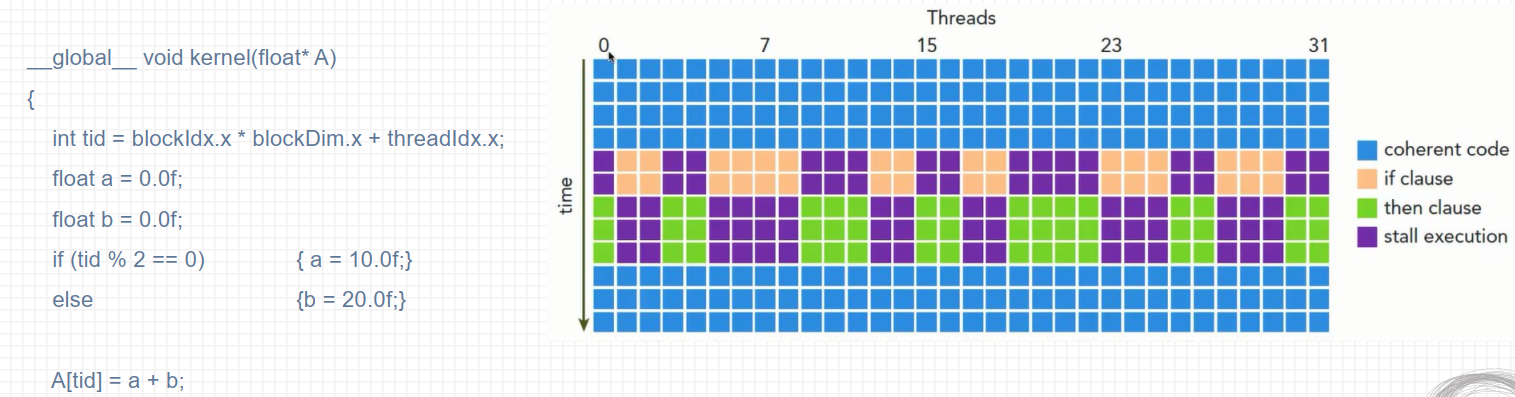
线程束分支会降低GPU的并行计算能力, 条件分支越多, 并行性削弱越严重;
线程束分支只发生在同一个线程束中, 不同线程束不会发生线程束分化;
为获取最佳性能, 应避免在同一个线程束中有不同的执行路径;
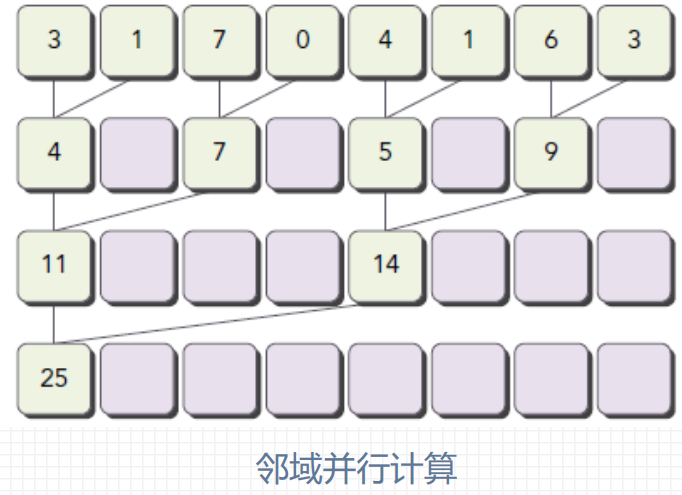
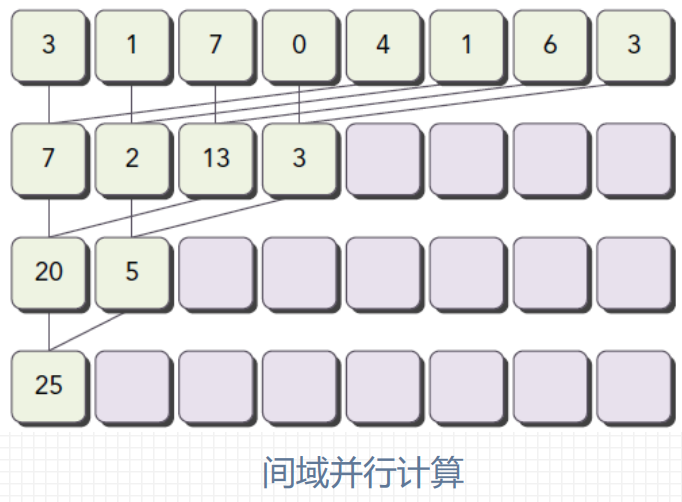
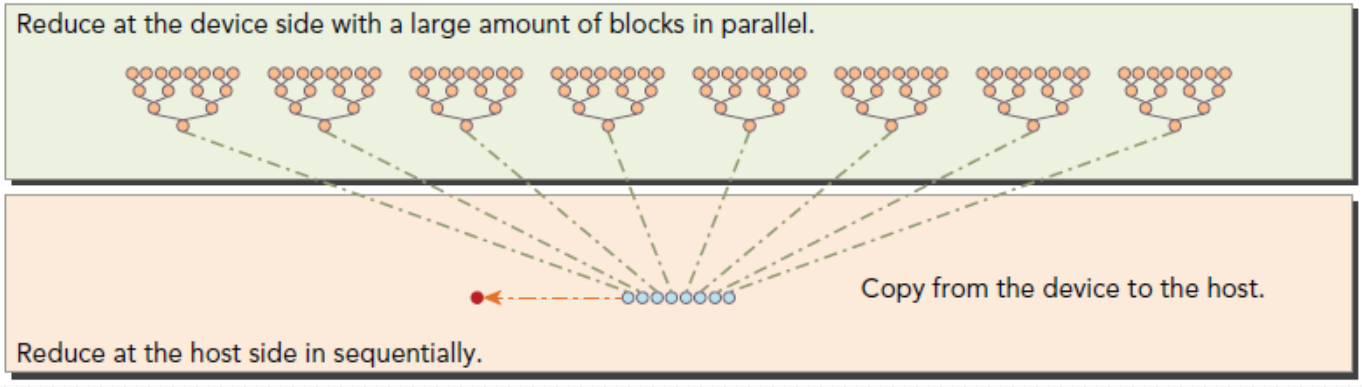
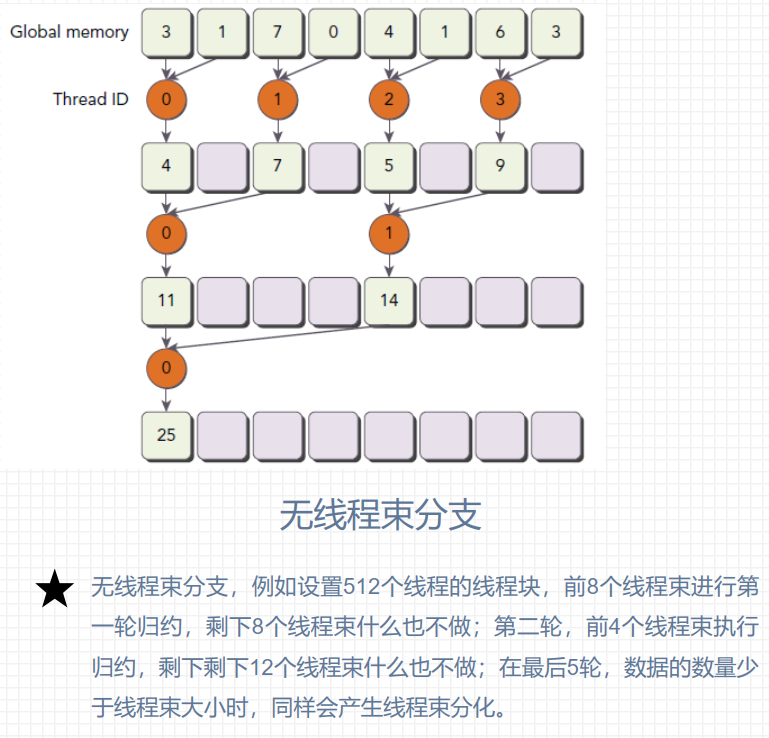
并行规约计算
在向量中满足交换律和结合律的运算, 称为规约问题, 并行执行的规约计算称为并行规约计算;
假设要计算4096个元素求和, 设计线程块大小为512, 每个线程负责一个数据元素, 共需8个线程块 。