使用特征存储连接 DataOps 和 MLOps 工作流,使协作团队能够高效开发。
什么是feature store
让通过按时间顺序查看开发人员在当前工作流程中面临的挑战来激发对特征存储的需求。假设有一项任务需要使用实体(例如用户)的特征来预测某些东西。
- 重复:孤立地开发特征(针对每个独特的 ML 应用程序)可能会导致重复工作(设置摄取管道、特征工程等)。
Solution:创建一个中央功能存储库,整个团队在其中贡献任何人都可以用于任何应用程序的维护功能。
- 偏斜:可能有不同的管道来生成训练和服务的特征,这会通过细微的差异引入偏斜。
Solution:使用统一管道创建特征并将它们存储在训练和服务管道从中提取的中心位置。
- 值:一旦设置了数据管道,需要确保transformers输入特征值是最新的,这样就不会使用陈旧的数据,同时保持时间点的正确性,这样就不会引入数据泄漏。
Solution:通过在进行预测时提取可用的内容来检索相应结果的输入特征。
时间点正确性是指将适当的最新输入特征值映射到观察到的结果. 这涉及知道时间()需要进行预测,以便可以收集特征值() 当时。
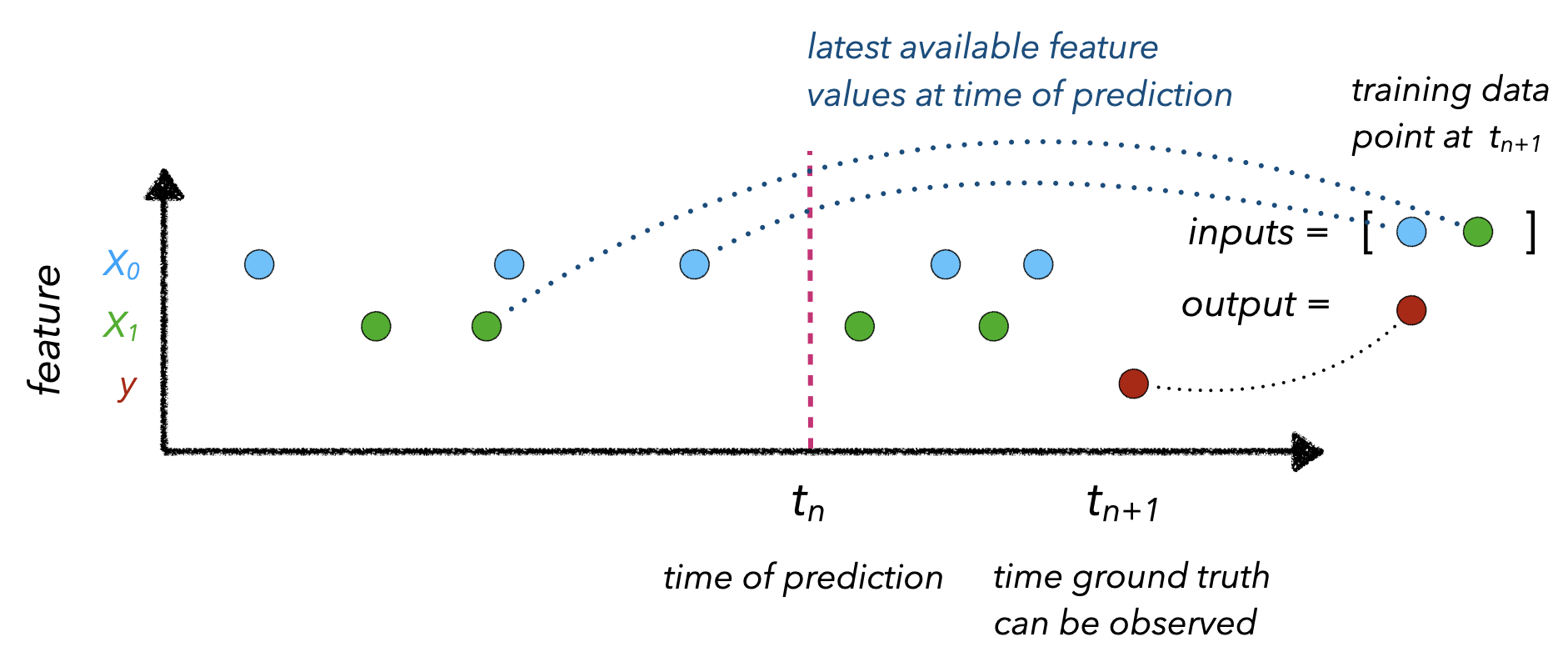
在实际构建transformers特征存储时,需要几个核心组件来应对这些挑战:
- 数据摄取:从各种来源(数据库、数据仓库等)摄取数据并保持更新的能力。
- 特征定义:定义实体和相应特征的能力
- 历史特征:检索历史特征以用于训练的能力。
- 在线功能:能够从低延迟源检索功能以进行推理。
这些组件中的每一个都相当容易设置,但将它们连接在一起需要托管服务、用于交互的 SDK 层等。与其从头开始构建,不如利用其中一个生产就绪的功能存储选项,例如Feast , Hopsworks , Tecton , Rasgo等。当然,大型云提供商也有自己的特征商店选项(亚马逊的SageMaker 特征商店,谷歌的Vertex AI等)
Tip
强烈建议您在完成前面的课程后探索本课程,因为主题(和代码)是迭代开发的。然而,确实创造了 使用交互式note快速概览的功能存储库。
过度工程化
并非所有机器学习平台都需要特征存储。事实上,transformers用例是一个无法从特征存储中获益的任务的完美示例。所有的数据点都是独立的、无状态的、来自客户端,并且没有随时间变化的实体。当需要为不断生成预测的实体提供最新功能时,功能存储的真正用途就会大放异彩。例如,用户在电商平台上的行为(点击、购买等)或最近一小时外卖跑者的外卖情况等。
我什么时候需要功能商店?
为了回答这个问题,让重新审视特征存储解决的主要挑战:
- 重复:如果没有太多的 ML 应用程序/模型,真的不需要添加特征存储的额外复杂性来管理转换。所有特征转换都可以直接在模型处理内部完成,也可以作为一个单独的函数完成。甚至可以在一个单独的中央存储库中组织这些转换,供其他团队成员使用。但这很快就变得难以使用,因为开发人员仍然需要知道要调用哪些转换以及哪些与他们的特定模型兼容等。
note
此外,如果转换是计算密集型的,那么它们将通过在不同应用程序的重复数据集上运行而产生大量成本(而不是拥有一个具有最新转换功能的中心位置)。
-
Skew:类似于重复工作,如果transformers转换可以绑定到模型或作为一个独立的函数,那么可以重用相同的管道来生成用于训练和服务的特征值。但随着应用程序、功能和转换数量的增长,这变得复杂且计算密集。
-
价值:如果不使用需要在服务器端计算的特性(批处理或流式处理),那么不必担心时间点等概念。但是,如果是,特征存储可以让在所有数据源中检索适当的特征值,而开发人员不必担心为不同的数据源(批处理、流式等)使用不同的工具。
Feast
将利用Feast作为应用程序的特征存储,因为它易于本地设置、用于训练/服务的 SDK 等。
# Install Feast and dependencies
pip install feast==0.10.5 PyYAML==5.3.1 -q
👉跟随交互式note在 特征存储库,因为实现了以下概念。
设置
将在项目的根目录下创建一个功能存储库。Feast将为创建一个配置文件,将添加一个额外的features.py文件来定义transformers功能。
传统上,功能存储库将是它自己的隔离存储库,其他服务将使用它来读取/写入功能。
mkdir -p stores/feature
mkdir -p data
feast init --minimal --template local features
cd features
touch features.py
在 /content/features 中创建一个新的feast存储库。
初始化的功能存储库(带有添加的附加文件)将包括:
features/
├── feature_store.yaml - configuration
└── features.py - feature definitions
将在transformersfeature_store.yaml文件中配置注册表和在线商店 (SQLite) 的位置。
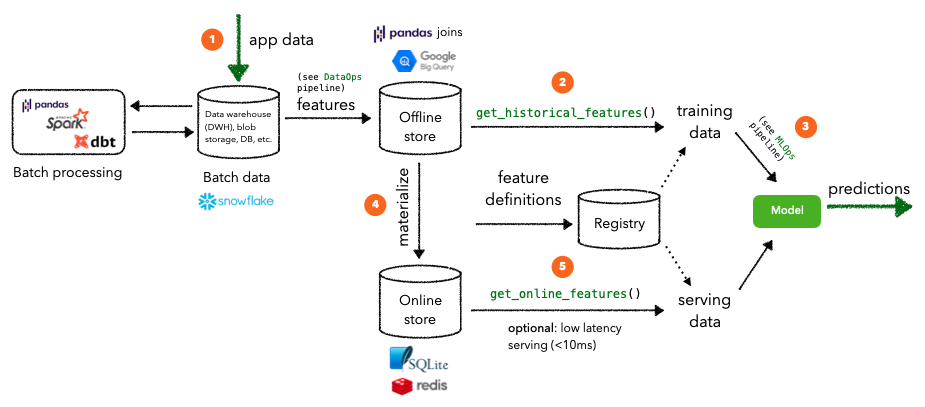
- registry:包含有关transformers功能存储库的信息,例如数据源、功能视图等。由于它位于数据库中,而不是 Python 文件中,因此可以在生产中快速访问它。
- 在线商店:数据库(本地 SQLite)存储用于在线推理的已定义实体的(最新)功能。
如果所有的功能定义看起来都有效,Feast 会将有关 Feast 对象的元数据同步到注册表。注册表是一个微型数据库,存储了与功能库中相同的大部分信息。此步骤是必要的,因为生产功能服务基础设施将无法在运行时访问功能存储库中的 Python 文件,但它将能够高效、安全地从注册表中读取功能定义。
当在本地运行 Feast 时,离线商店通过 Pandas 时间点连接有效地表示。而在生产中,离线商店可以是更强大的东西,如Google BigQuery、Amazon RedShift等。
将继续并将其粘贴到transformersfeatures/feature_store.yaml文件中(note单元会自动执行此操作):
project: features
registry: ../stores/feature/registry.db
provider: local
online_store:
path: ../stores/feature/online_store.db
数据摄取
第一步是与transformers数据源(数据库、数据仓库等)建立连接。Feast 要求其数据源来自文件 ( Parquet )、数据仓库 ( BigQuery ) 或数据流 ( Kafka / Kinesis )。会将生成的特征文件从 DataOps 管道 ( features.json) 转换为 Parquet 文件,这是一种列优先数据格式,可实现快速特征检索和缓存优势(与行优先数据格式相反,例如 CSV,必须遍历每一行以收集特征值)。
import os
import pandas as pd
# Load labeled projects
projects = pd.read_csv("https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv")
tags = pd.read_csv("https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv")
df = pd.merge(projects, tags, on="id")
df["text"] = df.title + " " + df.description
df.drop(["title", "description"], axis=1, inplace=True)
df.head(5)
| id | created_on | tag | text | |
|---|---|---|---|---|
| 0 | 6 | 2020-02-20 06:43:18 | computer-vision | Comparison between YOLO and RCNN on real world… |
| 1 | 7 | 2020-02-20 06:47:21 | computer-vision | Show, Infer & Tell: Contextual Inference for C… |
| 2 | 9 | 2020-02-24 16:24:45 | graph-learning | Awesome Graph Classification A collection of i… |
| 3 | 15 | 2020-02-28 23:55:26 | reinforcement-learning | Awesome Monte Carlo Tree Search A curated list… |
| 4 | 19 | 2020-03-03 13:54:31 | graph-learning | Diffusion to Vector Reference implementation o… |
# Format timestamp
df.created_on = pd.to_datetime(df.created_on)
# Convert to parquet
DATA_DIR = Path(os.getcwd(), "data")
df.to_parquet(
Path(DATA_DIR, "features.parquet"),
compression=None,
allow_truncated_timestamps=True,
)
特征定义
现在已经准备好数据源,可以为特征存储定义特征。
from datetime import datetime
from pathlib import Path
from feast import Entity, Feature, FeatureView, ValueType
from feast.data_source import FileSource
from google.protobuf.duration_pb2 import Duration
第一步是定义特征的位置(在transformers例子中是 FileSource)和每个数据点的时间戳列。
# Read data
START_TIME = "2020-02-17"
project_details = FileSource(
path=str(Path(DATA_DIR, "features.parquet")),
event_timestamp_column="created_on",
)
接下来,需要定义每个数据点所属的主要实体。在transformers例子中,每个项目都有一个唯一的 ID,具有文本和标签等特征。
# Define an entity
project = Entity(
name="id",
value_type=ValueType.INT64,
description="project id",
)
Finally, we’re ready to create a FeatureView that loads specific features (features), of various value types, from a data source (input) for a specific period of time (ttl).
# Define a Feature View for each project
project_details_view = FeatureView(
name="project_details",
entities=["id"],
ttl=Duration(
seconds=(datetime.today() - datetime.strptime(START_TIME, "%Y-%m-%d")).days * 24 * 60 * 60
),
features=[
Feature(name="text", dtype=ValueType.STRING),
Feature(name="tag", dtype=ValueType.STRING),
],
online=True,
input=project_details,
tags={},
)
因此,让继续通过将此代码移动到transformersfeatures/features.py脚本中来定义transformers功能视图(note单元会自动执行此操作):
显示代码
from datetime import datetime from pathlib import Path from feast import Entity, Feature, FeatureView, ValueType from feast.data_source import FileSource from google.protobuf.duration_pb2 import Duration # Read data START_TIME = "2020-02-17" project_details = FileSource( path="/content/data/features.parquet", event_timestamp_column="created_on", ) # Define an entity for the project project = Entity( name="id", value_type=ValueType.INT64, description="project id", ) # Define a Feature View for each project # Can be used for fetching historical data and online serving project_details_view = FeatureView( name="project_details", entities=["id"], ttl=Duration( seconds=(datetime.today() - datetime.strptime(START_TIME, "%Y-%m-%d")).days * 24 * 60 * 60 ), features=[ Feature(name="text", dtype=ValueType.STRING), Feature(name="tag", dtype=ValueType.STRING), ], online=True, input=project_details, tags={}, )
一旦定义了transformers功能视图,就可以apply将transformers功能的版本控制定义推送到注册表以便快速访问。它还将配置在feature_store.yaml.
cd features
feast apply
Registered entity id
Registered feature view project_details
Deploying infrastructure for project_details
历史特征
一旦注册了特征定义以及数据源、实体定义等,就可以使用它来获取历史特征。这是通过使用提供的时间戳连接完成的,使用 pandas 进行本地设置或将 BigQuery、Hive 等用作生产的离线数据库。
import pandas as pd
from feast import FeatureStore
# Identify entities
project_ids = df.id[0:3].to_list()
now = datetime.now()
timestamps = [datetime(now.year, now.month, now.day)]*len(project_ids)
entity_df = pd.DataFrame.from_dict({"id": project_ids, "event_timestamp": timestamps})
entity_df.head()
| id | event_timestamp | |
|---|---|---|
| 0 | 6 | 2022-06-23 |
| 1 | 7 | 2022-06-23 |
| 2 | 9 | 2022-06-23 |
# Get historical features
store = FeatureStore(repo_path="features")
training_df = store.get_historical_features(
entity_df=entity_df,
feature_refs=["project_details:text", "project_details:tag"],
).to_df()
training_df.head()
| event_timestamp | id | project_details__text | project_details__tag | |
|---|---|---|---|---|
| 0 | 2022-06-23 00:00:00+00:00 | 6 | Comparison between YOLO and RCNN on real world… | computer-vision |
| 1 | 2022-06-23 00:00:00+00:00 | 7 | Show, Infer & Tell: Contextual Inference for C… | computer-vision |
| 2 | 2022-06-23 00:00:00+00:00 | 9 | Awesome Graph Classification A collection of i… | graph-learning |
Materialize
对于在线推理,希望通过transformers在线商店非常快速地检索特征,而不是从缓慢的连接中获取它们。然而,这些功能还没有出现在transformers在线商店中,所以需要先实现它们。
cd features
CURRENT_TIME=$(date -u +"%Y-%m-%dT%H:%M:%S")
feast materialize-incremental $CURRENT_TIME
Materializing 1 feature views to 2022-06-23 19:16:05+00:00 into the sqlite online store.
project_details from 2020-02-17 19:16:06+00:00 to 2022-06-23 19:16:05+00:00:
100%|██████████████████████████████████████████████████████████| 955/955 [00:00<00:00, 10596.97it/s]
这已将所有项目的功能转移到在线商店,因为这是第一次实现在线商店。当随后运行该materialize-incremental命令时,Feast 会跟踪以前的具体化,因此只会具体化自上次尝试以来的新数据。
在线功能
一旦具体化了特征(或在流场景中直接发送到在线商店),就可以使用在线商店来检索特征。
# Get online features
store = FeatureStore(repo_path="features")
feature_vector = store.get_online_features(
feature_refs=["project_details:text", "project_details:tag"],
entity_rows=[{"id": 6}],
).to_dict()
feature_vector
{'id': [6],
'project_details__tag': ['computer-vision'],
'project_details__text': ['Comparison between YOLO and RCNN on real world videos Bringing theory to experiment is cool. We can easily train models in colab and find the results in minutes.']}
Architecture
批量处理
上面实现的特征存储假设transformers任务需要批处理。这意味着对特定实体实例的推理请求可以使用从离线存储中具体化的特征。请注意,它们可能不是该实体的最新特征值。
- 应用程序数据存储在数据库和/或数据仓库等中。它通过必要的管道为下游应用程序(分析、机器学习等)做准备。
- 这些功能被写入离线存储,然后可用于检索历史训练数据来训练模型。在transformers本地设置中,这是通过 Pandas DataFrame 加入给定的时间戳和实体 ID,但在生产环境中,Google BigQuery 或 Hive 之类的东西会收到功能请求。
- 一旦有了训练数据,就可以启动工作流来优化、训练和验证模型。
- 可以逐步将特征具体化到在线商店,以便可以以低延迟检索实体的特征值。在transformers本地设置中,这是通过 SQLite 连接给定的一组实体,但在生产环境中,将使用 Redis 或 DynamoDB 之类的东西。
- 这些在线功能被传递到部署的模型以生成将在下游使用的预测。
警告
如果transformers实体(项目)具有随时间变化的特性,将逐步将它们具体化到在线商店。但由于他们不这样做,这将被视为过度工程,但重要的是要知道如何为随时间变化的特性的实体利用特性存储。
流处理
一些应用程序可能需要流处理,需要近乎实时的特征值来以低延迟提供最新的预测。虽然仍将使用离线商店来检索历史数据,但应用程序的实时事件数据将直接通过transformers数据流传输到在线商店进行服务。需要流处理的一个示例是,当想要在电子商务平台中检索实时用户会话行为(点击、购买),以便可以从transformers目录中推荐合适的商品时。
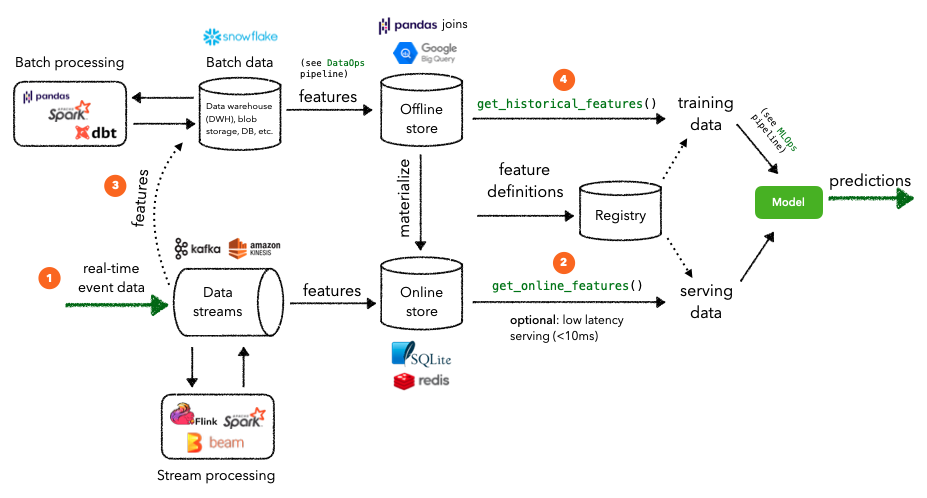
- 实时事件数据进入transformers运行数据流(Kafka / Kinesis等),在那里它们可以被处理以生成特征。
- 这些功能被写入在线商店,然后可用于检索在线功能以低延迟提供服务。在transformers本地设置中,这是通过 SQLite 连接给定的一组实体,但在生产环境中,将使用 Redis 或 DynamoDB 之类的东西。
- Streaming features也是从data stream写入到batch data source(data warehouse, db, etc.)进行处理,用于后面生成训练数据。
- 历史数据将被验证并用于生成用于训练模型的特征。这种情况发生频率的节奏取决于是否存在数据注释滞后、计算约束等。
还有一些在这里没有可视化的组件,例如统一摄取层 (Spark),它将来自不同数据源(仓库、数据库等)的数据连接到离线/在线商店,或低延迟服务( <10 毫秒)。可以在官方Feast 文档中阅读更多关于所有这些的信息,该文档还提供了使用 Feast 与 AWS、GCP 等设置特征存储的指南。
附加功能
许多特征存储提供商当前(或最近)尝试在特征存储平台中集成的其他功能包括:
- transform:能够在从数据源中提取的原始数据上直接应用全局预处理或特征工程。
Current solution:在写入特征存储之前,将转换作为单独的 Spark、Python 等工作流任务应用。
- 验证:断言期望并识别特征值数据漂移的能力。
Current solution:在将数据测试和监控写入特征存储之前,将其作为上游工作流任务应用。
- 发现:团队中的任何人都能够轻松发现他们可以在其应用程序中利用的功能。
Current solution:在transformers特征存储之上添加一个数据发现引擎,例如Amundsen ,使其他人能够搜索特征。
再现性
尽管可以在发布模型版本时继续使用DVC对训练数据进行版本化,但这可能没有必要。当从源中提取数据或计算特征时,它们应该保存数据本身还是只保存操作?
- 数据版本
- 如果 (1) 数据是可管理的,(2) 如果transformers团队是小型/早期 ML 或 (3) 如果数据更改不频繁,这是可以的。
- 但是当数据变得越来越大并且不断地复制它时会发生什么。
- 对操作进行版本化
- 可以保留数据快照(与transformers项目分开)并提供操作和时间戳,可以对这些数据快照执行操作以重新创建用于训练的精确数据工件。许多数据系统使用时间旅行来有效地实现这一点。
- 但最终这也会导致数据存储量过大。需要的是一个仅附加数据源,其中所有更改都保存在日志中,而不是直接更改数据本身。因此,可以使用带有日志的数据系统来生成数据的原始版本,而无需存储数据本身的单独快照。
无论上面的选择如何,特征存储在这里都非常有用。可以将这两个过程分开,而不是将数据拉取和特征计算与建模时间耦合,以便在需要时特征是最新的。仍然可以通过高效的时间点正确性、低延迟快照等实现可重复性。这实质上创造了在任何时间点使用任何版本的数据集的能力。
更多干货,第一时间更新在以下微信公众号:

您的一点点支持,是我后续更多的创造和贡献

转载到请包括本文地址 更详细的转载事宜请参考文章如何转载/引用
本文主体源自以下链接:
@article{madewithml,
author = {Goku Mohandas},
title = { Made With ML },
howpublished = {\url{https://madewithml.com/}},
year = {2022}
}