通过为分析和机器学习应用程序构建现代数据堆栈来学习数据工程基础知识。
Intuition
到目前为止,已经可以方便地使用本地 CSV 文件作为数据源,但实际上,transformers数据可能来自许多不同的来源。此外,理想情况下,transformers数据转换和测试流程应该移至上游,以便许多不同的下游流程可以从中受益。transformers ML 用例只是众多潜在下游应用程序中的一个。为了解决这些缺点,将学习数据工程的基础知识,并构建一个可以扩展并为transformers应用程序提供高质量数据的现代数据堆栈。
在本课中,将学习如何通过用户界面 (UI) 设置和使用数据堆栈,但在编排课中,将学习如何以编程方式执行所有内容 (Python + bash)。查看 所有代码的数据工程存储库。
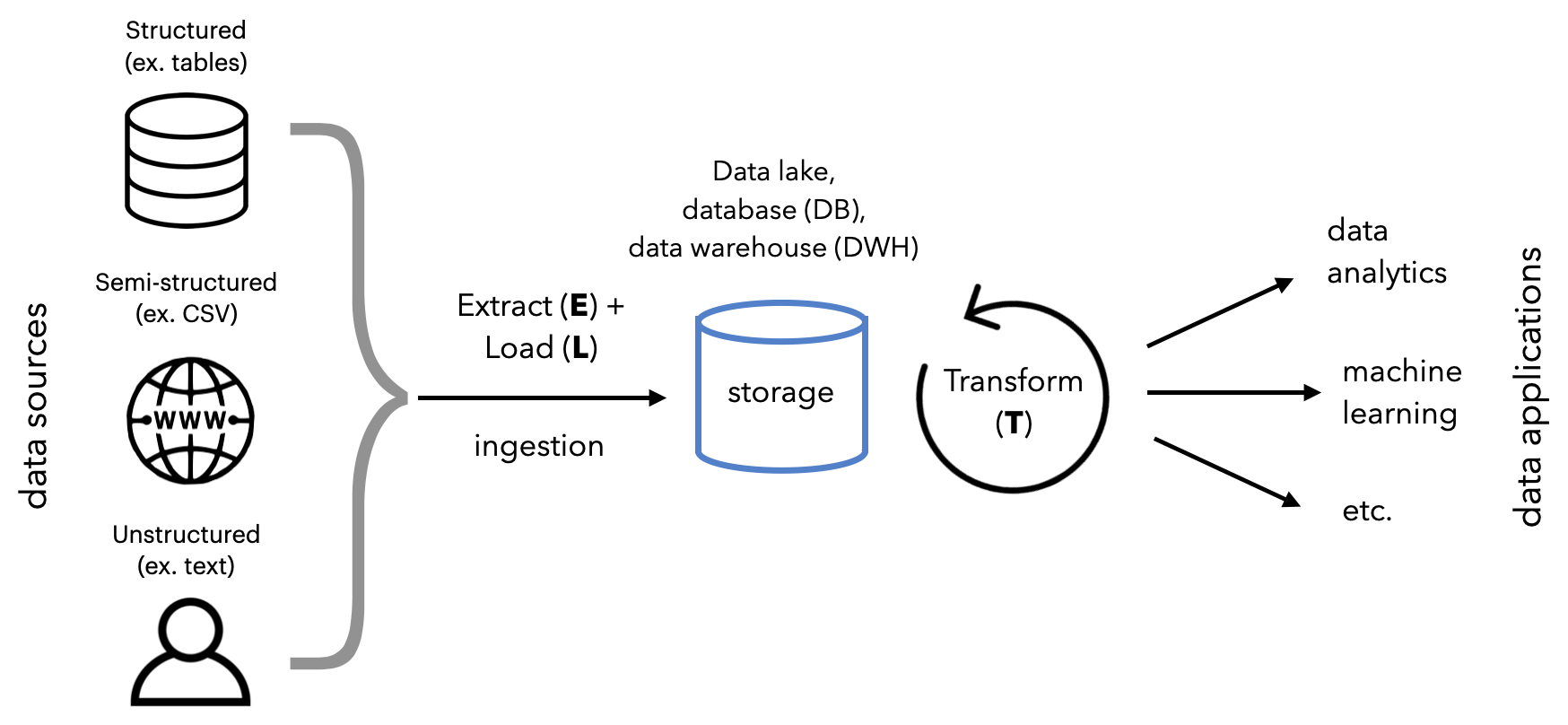
在高层次上,将:
这个过程通常被称为 ELT,但也有 ETL 和反向 ETL 等变体。它们本质上都是相同的底层工作流,但在数据流的顺序以及数据处理和存储的位置上略有不同。
实用性和简单性
在您的组织中建立现代数据堆栈可能很诱人,尤其是在大肆宣传的情况下。但激发效用并增加额外的复杂性非常重要:
- 从已有数据源并直接影响业务底线(例如用户流失)的用例开始。
- 从最简单的基础架构(源 → 数据库 → 报告)开始,然后根据需要增加复杂性(在基础架构、性能和团队方面)。
数据系统
在开始处理transformers数据之前,了解transformers数据可以存在的不同类型的系统是很重要的。到目前为止,在本课程中已经使用了文件、API等,但是有几种类型的数据系统是为不同的目的在工业中广泛采用。
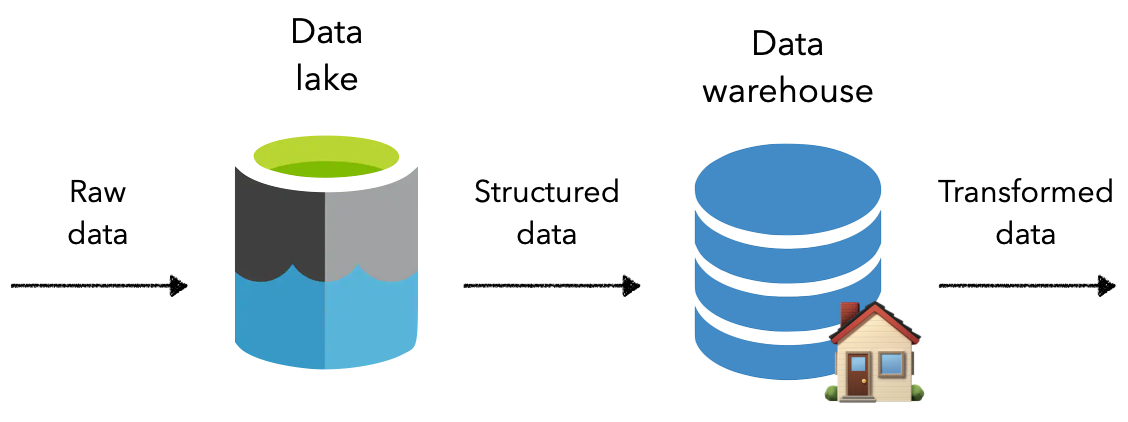
数据湖
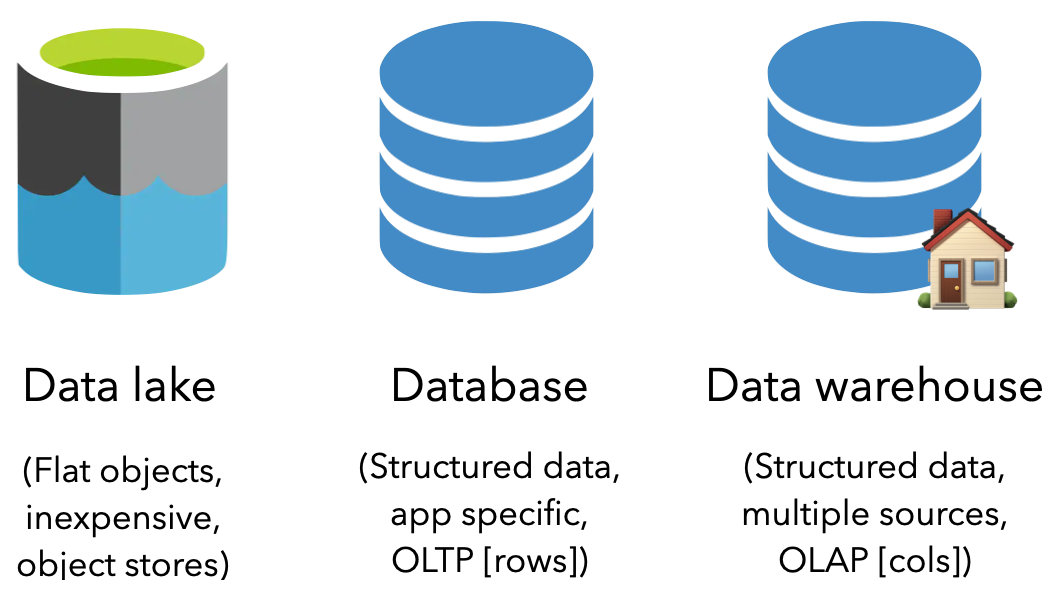
数据湖是存储原始对象的平面数据管理系统。它是廉价存储的绝佳选择,并且能够保存所有类型的数据(非结构化、半结构化和结构化)。对象存储正在成为数据湖的标准,在流行的云提供商中具有默认选项。不幸的是,由于数据是作为对象存储在数据湖中的,它并不是为对结构化数据进行操作而设计的。
回想一下,在版本控制课程中构建了一个本地对象存储来模拟transformers远程存储来保存和加载transformers版本化数据。
热门工具
流行的数据湖选项包括Amazon S3、Azure Blob Storage、Google Cloud Storage等。
数据库
另一个流行的存储选项是数据库 (DB),它是有组织的结构化数据集合,符合以下任一条件:
- 关系模式(包含行和列的表)通常称为关系数据库管理系统 (RDBMS) 或 SQL 数据库。
- 非关系型(键/值、图形等),通常称为非关系型数据库或NoSQL 数据库。
数据库是一种联机事务处理 (OLTP)系统,因为它通常用于日常的 CRUD(创建、读取、更新、删除)操作,其中通常按行访问信息。但是,它们通常用于存储来自一个应用程序的数据,而不是为了分析目的而设计来保存来自多个来源的数据。
热门工具
流行的数据库选项包括PostgreSQL、MySQL、MongoDB、Cassandra等。
数据仓库
数据仓库 (DWH) 是一种数据库,旨在存储来自许多不同来源的结构化数据,用于下游分析和数据科学。它是一个联机分析处理 (OLAP)系统,针对跨聚合列值而不是访问特定行执行操作进行了优化。
热门工具
流行的数据仓库选项包括SnowFlake、Google BigQuery、Amazon RedShift、Hive等。
Data lakehouse
不断引入新的数据系统,例如Data lakehouse,它们结合了以前系统的最佳方面。例如,lakehouse 允许使用数据仓库结构存储原始数据和转换后的数据。
提取和加载
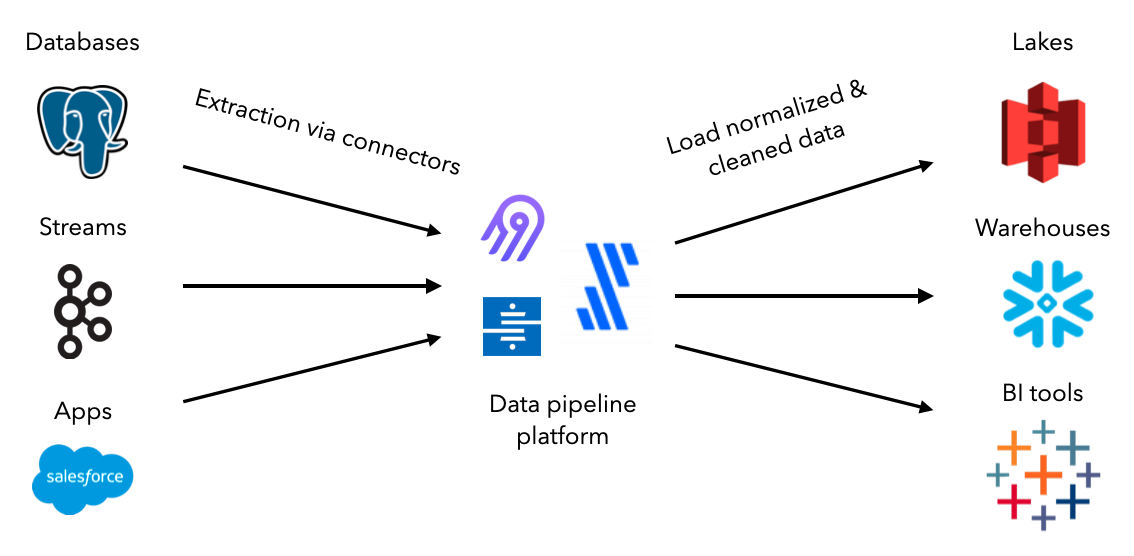
数据管道的第一步是从源中提取数据并将其加载到适当的目的地。虽然可以构建自定义脚本来手动或按计划执行此操作,但数据摄取工具的生态系统已经标准化了整个过程。它们都配备了连接器,允许在源和目的地之间进行提取、标准化、清洁和加载。这些管道可以扩展、监控等,所有这些都只需要很少的代码甚至不需要代码。
热门工具
将使用开源工具Airbyte在transformers数据源和目的地之间创建连接。让设置 Airbyte 并定义transformers数据源。随着在本课中的进步,将设置目的地并创建连接以提取和加载数据。
-
确保仍然安装了Docker 课程中的 Docker ,如果没有,请在此处下载。对于 Windows 用户,请务必启用这些配置。
-
在transformers MLOps 课程项目目录之外的父目录中,执行以下命令以在本地加载 Airbyte 存储库并启动服务。
git clone https://github.com/airbytehq/airbyte.git cd airbyte docker-compose up -
几分钟后,访问http://localhost:8000/查看启动的 Airbyte 服务。
来源
要从中提取的数据源可以来自任何地方。它们可能来自第三方应用程序、文件、用户点击流、物理设备、数据湖、数据库、数据仓库等。但无论transformers数据来源如何,它们的数据类型都应属于以下类别之一:
structured:以显式结构存储的有组织的数据(例如表格)semi-structured:具有某种结构但没有正式模式或数据类型(网页、CSV、JSON 等)的数据unstructured:没有正式结构的定性数据(文本、图像、音频等)
对于transformers应用程序,将定义两个数据源:
- projects.csv:包含项目及其 ID、创建日期、标题和描述的数据。
- tags.csv:projects.csv 中每个项目 ID 的标签
理想情况下,这些数据assert将从包含提取的项目的数据库中检索,也可能从另一个数据库中检索,该数据库存储标签团队工作流程中的标签。但是,为简单起见,将使用 CSV 文件来演示如何定义数据源。
在 Airbyte 中定义文件源
将通过在 Airbyte 中定义数据源来开始transformers ELT 过程:
-
在transformersAirbyte UI上,单击
Sources左侧菜单上的。然后点击右上角的+ New source按钮。 -
单击
Source type下拉菜单并选择File。这将打开一个视图来定义transformers文件数据源。Name: Projects URL: https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv File Format: csv Storage Provider: HTTPS: Public Web Dataset Name: projects -
单击该
Set up source按钮,transformers数据源将被测试并保存。 -
对transformers标签数据源也重复步骤 1-3:
Name: Tags URL: https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv File Format: csv Storage Provider: HTTPS: Public Web Dataset Name: tags

目的地
一旦知道了想要从中提取数据的源,就需要决定加载它的目的地。选择取决于transformers下游应用程序希望能够对数据做什么。将数据存储在一个位置(例如数据湖)并将其移动到其他地方(例如数据仓库)以进行特定处理也很常见。
设置谷歌 BigQuery
transformers目的地将是数据仓库,因为希望将数据用于下游分析和机器学习应用程序。将使用Google BigQuery,它在 Google Cloud 的免费套餐下是免费的,可提供高达 10 GB 的存储空间和 1TB 的查询(这比transformers目的所需的要多得多)。
-
登录到您的Google 帐户,然后转到Google CLoud。如果您还没有使用过 Google Cloud 的免费试用版,则必须注册。它是免费的,除非您手动升级您的帐户,否则不会自动向您收费。试用期结束后,仍将拥有免费套餐,这对来说绰绰有余。
-
转到Google BigQuery 页面并单击
Go to console按钮。 -
Project name: made-with-ml # Google will append a unique ID to the end of it Location: No organization -
创建项目后,刷新页面,应该会看到它(以及其他一些来自 Google 的默认项目)。
# Google BigQuery projects
├── made-with-ml-XXXXXX 👈 our project
├── bigquery-publicdata
├── imjasonh-storage
└── nyc-tlc
控制台或代码
大多数云提供商将允许通过控制台执行所有操作,但也允许通过 API、Python 等以编程方式执行所有操作。例如,手动创建一个项目,但也可以使用此处所示的代码来完成。
在 Airbyte 中定义 BigQuery 目的地
接下来,需要在 Airbyte 和 BigQuery 之间建立连接,以便可以将提取的数据加载到目的地。为了使用 Airbyte 验证对 BigQuery 的访问权限,需要创建一个服务帐户并生成一个密钥。这基本上是创建一个具有特定访问权限的身份,可以将其用于验证。按照这些说明创建服务并生成密钥文件 (JSON)。记下此文件的位置,因为将在整个课程中使用它。例如transformers是/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json。
-
在transformersAirbyte UI上,单击
Destinations左侧菜单上的。然后点击右上角的+ New destination按钮。 -
单击
Destination type下拉菜单并选择BigQuery。这将打开一个视图来定义transformers文件数据源。Name: BigQuery Default Dataset ID: mlops_course # where our data will go inside our BigQuery project Project ID: made-with-ml-XXXXXX # REPLACE this with your Google BiqQuery Project ID Credentials JSON: SERVICE-ACCOUNT-KEY.json # REPLACE this with your service account JSON location Dataset location: US # select US or EU, all other options will not be compatible with dbt later -
单击该
Set up destination按钮,transformers数据目的地将被测试并保存。

连接
因此,已经设置了数据源(公共 CSV 文件)和目标(Google BigQuery 数据仓库),但它们尚未连接。要创建连接,需要考虑几个方面。
频率
希望多久从源中提取数据并将其加载到目标中?
Micro-batch
随着不断减少批量摄取之间的时间(例如接近 0),是否有流摄取?不完全是。批处理是故意决定以给定的时间间隔从源中提取数据。由于该时间间隔小于 15 分钟,因此称为微批次(许多数据仓库允许每 5 分钟进行一次批处理)。但是,对于流摄取,提取过程会持续进行,事件将不断被摄取。
从简单开始
一般来说,对于大多数应用程序来说,从批量摄取开始,然后慢慢增加流式摄取(和额外的基础设施)的复杂性是个好主意。这是可以证明,下游应用程序正在从数据源中发现价值,并且后来发展到流式处理应该只会改善事情。
将在transformers系统设计课程中详细了解批处理与流的不同系统设计含义。
将文件源连接到 BigQuery 目标
现在准备好在transformers源和目的地之间创建连接:
-
在transformersAirbyte UI上,单击
Connections左侧菜单上的。然后点击右上角的+ New connection按钮。 -
在 下
Select a existing source,单击Source下拉菜单并选择Projects并单击Use existing source。 -
在 下
Select a existing destination,单击Destination下拉菜单并选择BigQuery并单击Use existing destination。Connection name: Projects <> BigQuery Replication frequency: Manual Destination Namespace: Mirror source structure Normalized tabular data: True # leave this selected -
单击该
Set up connection按钮,transformers连接将被测试并保存。 -
对具有相同目的地的
Tags源重复相同的操作。BigQuery
请注意,transformers同步模式
Full refresh | Overwrite意味着每次从源同步数据时,它都会覆盖目标中的现有数据。与Full refresh | Appendwhich 不同的是,它会将源中的条目添加到先前同步的底部。
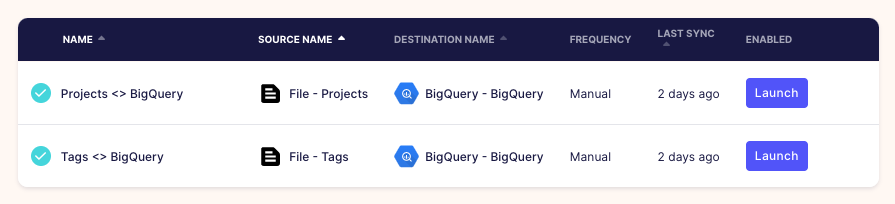
数据同步
transformers复制频率是Manual因为会自己触发数据同步:
- 在transformersAirbyte UI上,单击
Connections左侧菜单上的。然后点击Projects <> BigQuery之前设置的连接。 - 按下
🔄 Sync now按钮,一旦完成,将看到项目现在位于transformers BigQuery 数据仓库中。 Tags <> BigQuery对transformers连接重复相同的操作。
# Inside our data warehouse
made-with-ml-XXXXXX - Project
└── mlops_course - Dataset
│ ├── _airbyte_raw_projects - table
│ ├── _airbyte_raw_tags - table
│ ├── projects - table
│ └── tags - table
在transformers编排课程中,将使用 Airflow 以编程方式执行数据同步。
可以直接在transformers仓库中使用 SQL 轻松探索和查询这些数据:
-
在transformers BigQuery 项目页面上,单击
🔍 QUERY按钮并选择In new tab。 -
运行如下SQL语句,查看数据:
SELECT * FROM `made-with-ml-XXXXXX.mlops_course.projects` LIMIT 1000 -
0
| id | created_on | title | description | |
|---|---|---|---|---|
| 0 | 6 | 2020-02-20 06:43:18 | Comparison between YOLO and RCNN on real world… | Bringing theory to experiment is cool. We can … |
| 1 | 7 | 2020-02-20 06:47:21 | Show, Infer & Tell: Contextual Inference for C… | The beauty of the work lies in the way it arch… |
| 2 | 9 | 2020-02-24 16:24:45 | Awesome Graph Classification | A collection of important graph embedding, cla… |
| 3 | 15 | 2020-02-28 23:55:26 | Awesome Monte Carlo Tree Search | A curated list of Monte Carlo tree search papers… |
| 4 | 19 | 2020-03-03 13:54:31 | Diffusion to Vector | Reference implementation of Diffusion2Vec (Com… |
最佳实践
随着廉价存储和管理它们的云 SaaS 选项的出现,将原始数据存储到数据湖中已成为最佳实践。这允许存储原始的、可能是非结构化的数据,而无需为下游应用程序证明存储的合理性。当确实需要转换和处理数据时,可以将其移动到数据仓库中,以便高效地执行这些操作。
转换
提取并加载数据后,需要转换数据,以便为下游应用程序做好准备。这些转换不同于之前看到的预处理,而是反映了对下游应用程序不可知的业务逻辑。常见的转换包括定义模式、过滤、清理和跨表连接数据等。虽然可以在数据仓库中使用 SQL 完成所有这些事情(将查询保存为表或视图),但 dbt 提供围绕版本控制、测试、开箱即用的文档、包装等。这对于保持可观察性和高质量数据工作流程至关重要。
![]()
热门工具
除了数据转换,还可以使用大型分析引擎(如 Spark、Flink 等)来处理数据。将在transformers系统设计课程中了解有关批处理和流处理的更多信息。
dbt Cloud
现在已准备好使用dbt转换数据仓库中的数据。将在 dbt Cloud(免费)上使用开发人员帐户,它为提供了一个 IDE、无限运行等。
将在编排课程中学习如何使用dbt-core。与 dbt Cloud 不同,dbt core 是完全开源的,可以通过编程方式连接到transformers数据仓库并执行转换。
- 创建一个免费帐户并验证它。
- 转到https://cloud.getdbt.com/进行设置。
- 单击
continue并选择BigQuery作为数据库。 - 单击
Upload a Service Account JSON file并上传transformers文件以自动填充所有内容。 - 单击
Test>Continue。 - 单击
Managed存储库并为其命名dbt-transforms(或您想要的任何其他名称)。 - 点击
Create>Continue>Skip and complete。 - 这将打开项目页面并单击
>_ Start Developing按钮。 - 这将打开 IDE,可以在其中单击
🗂 initialize your project。
现在准备开始开发transformers模型:
- 单击左侧菜单中目录
···旁边的。models - 点击
New folder被叫models/labeled_projects。 - 创建一个
New file名为.models/labeled_projectslabeled_projects.sql - 对
models/labeled_projects名为schema.yml.
dbt-cloud-XXXXX-dbt-transforms
├── ...
├── models
│ ├── example
│ └── labeled_projects
│ │ ├── labeled_projects.sql
│ │ └── schema.yml
├── ...
└── README.md
加入
在transformersmodels/labeled_projects/labeled_projects.sql文件中,将创建一个视图,将transformers项目数据与适当的标签连接起来。这将创建下游应用程序(如机器学习模型)所需的标记数据。这里根据项目和标签之间的匹配 id 加入:
-- models/labeled_projects/labeled_projects.sql
SELECT p.id, created_on, title, description, tag
FROM `made-with-ml-XXXXXX.mlops_course.projects` p -- REPLACE
LEFT JOIN `made-with-ml-XXXXXX.mlops_course.tags` t -- REPLACE
ON p.id = t.id
可以通过点击Preview按钮查看查询结果,也可以查看数据沿袭。
Schemas
在transformersmodels/labeled_projects/schema.yml文件中,将为转换后的数据中的每个特征定义模式。还定义了每个功能应该通过的几个测试。查看dbt 测试的完整列表,但请注意,当在编排课程中编排所有这些数据工作流时,将使用Great Expectations进行更全面的测试。
# models/labeled_projects/schema.yml
version: 2
models:
- name: labeled_projects
description: "Tags for all projects"
columns:
- name: id
description: "Unique ID of the project."
tests:
- unique
- not_null
- name: title
description: "Title of the project."
tests:
- not_null
- name: description
description: "Description of the project."
tests:
- not_null
- name: tag
description: "Labeled tag for the project."
tests:
- not_null
Runs
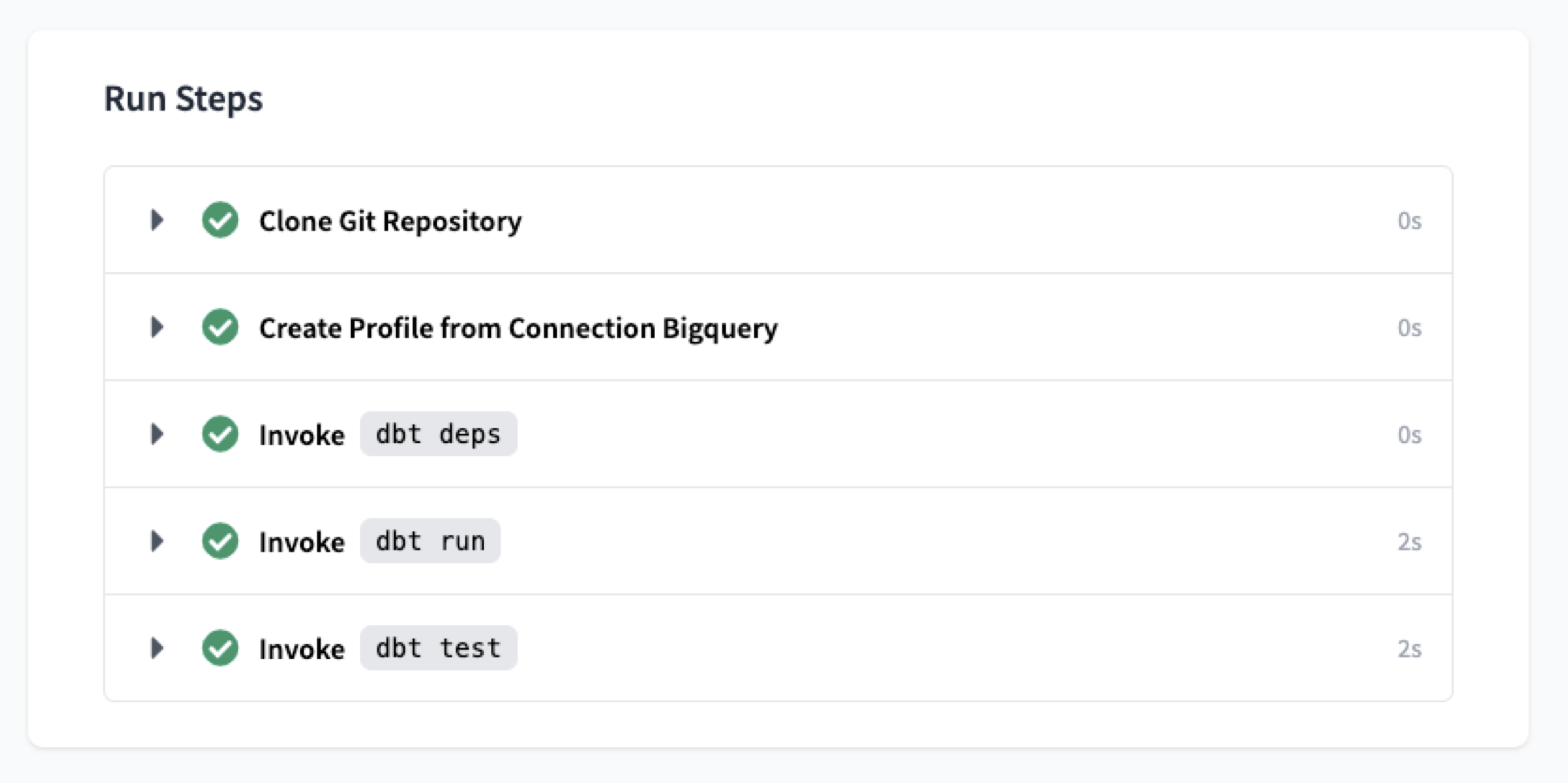
在 IDE 的底部,可以根据定义的转换执行运行。将运行以下每个命令,一旦它们完成,就可以在transformers数据仓库中看到转换后的数据。
dbt run dbt test
一旦这些命令成功运行,就可以将transformers转换转移到生产环境中,可以在其中将此视图插入transformers数据仓库中。
工作
为了将这些转换应用于数据仓库中的数据,最好的做法是创建一个环境然后定义作业:
-
单击
Environments左侧菜单 >New Environment按钮(右上角)并填写详细信息:Name: Production Type: Deployment ... Dataset: mlops_course -
单击
New Job以下详细信息,然后单击Save(右上角)。Name: Transform Environment: Production Commands: dbt run dbt test Schedule: uncheck "RUN ON SCHEDULE" -
在名为 的视图下单击
Run Now并查看数据仓库中转换后的数据labeled_projects。
# Inside our data warehouse
made-with-ml-XXXXXX - Project
└── mlops_course - Dataset
│ ├── _airbyte_raw_projects - table
│ ├── _airbyte_raw_tags - table
│ ├── labeled_projects - view
│ ├── projects - table
│ └── tags - table
dbt 还有很多内容,因此请务必查看他们的官方文档以真正自定义任何工作流程。请务必查看transformers编排课程,将在其中以编程方式创建和执行transformers dbt 转换。
应用
希望创建数据堆栈是为了获得有关transformers业务、用户等的一些可操作的洞察力。因为正是这些用例决定了从哪些数据源中提取数据、数据存储和转换的频率和方式。数据的下游应用通常属于以下类别之一:
-
data analytics:用例侧重于通过图表、仪表板等报告趋势、聚合视图等,目的是为业务利益相关者提供运营洞察力。 -
machine learning:以使用转换后的数据构建预测模型(预测、个性化等)为中心的用例。
虽然从transformers数据仓库中提取数据非常容易:
pip install google-cloud-bigquery==1.21.0
from google.cloud import bigquery
from google.oauth2 import service_account
# Replace these with your own values
project_id = "made-with-ml-XXXXXX" # REPLACE
SERVICE_ACCOUNT_KEY_JSON = "/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json" # REPLACE
# Establish connection
credentials = service_account.Credentials.from_service_account_file(SERVICE_ACCOUNT_KEY_JSON)
client = bigquery.Client(credentials= credentials, project=project_id)
# Query data
query_job = client.query("""
SELECT *
FROM mlops_course.labeled_projects""")
results = query_job.result()
results.to_dataframe().head()
| id | created_on | title | description | tag | |
|---|---|---|---|---|---|
| 0 | 1994.0 | 2020-07-29 04:51:30 | Understanding the Effectivity of Ensembles in … | The report explores the ideas presented in Dee… | computer-vision |
| 1 | 1506.0 | 2020-06-19 06:26:17 | Using GitHub Actions for MLOps & Data Science | A collection of resources on how to facilitate… | mlops |
| 2 | 807.0 | 2020-05-11 02:25:51 | Introduction to Machine Learning Problem Framing | This course helps you frame machine learning (… | mlops |
| 3 | 1204.0 | 2020-06-05 22:56:38 | Snaked: Classifying Snake Species using Images | Proof of concept that it is possible to identi… | computer-vision |
| 4 | 1706.0 | 2020-07-04 11:05:28 | PokeZoo | A deep learning based web-app developed using … | computer-vision |
警告
查看transformersnote,在其中从数据仓库中提取转换后的数据。在单独的note中执行此操作,因为它需要
google-cloud-bigquery包,并且在 dbt放松它的 Jinja 版本控制限制之前……它必须在单独的环境中完成。但是,下游应用程序通常是分析或 ML 应用程序,它们无论如何都有自己的环境,因此这些冲突不会受到抑制。
许多分析(例如仪表板)和机器学习解决方案(例如功能存储)允许轻松连接到transformers数据仓库,以便在事件发生时或按计划触发工作流。将在下一课中更进一步,将使用中央编排平台来控制所有这些工作流。
先分析,再机器学习
最好让前几个应用程序基于分析和报告,以便建立强大的数据堆栈。这些用例通常只涉及显示数据聚合和趋势,而不是涉及额外复杂基础设施和工作流的机器学习系统。
可观察性
当创建这样复杂的数据工作流时,可观察性成为重中之重。数据可观察性是了解系统中数据状况的一般概念,它涉及:
data quality:在每一步(模式、完整性、新近度等)之后测试和监控transformers数据质量。data lineage:映射数据的来源以及数据在transformers管道中移动时的转换方式。discoverability:能够发现下游应用程序的不同数据源和功能。privacy + security:是否在应用程序中适当地处理和限制了不同的数据assert?
热门工具
流行的可观察性工具包括Monte Carlo、Bigeye等。
注意事项
创建强大数据工作流的数据堆栈生态系统正在发展和成熟。然而,在选择最佳工具选项时可能会让人不知所措,尤其是当需求随时间变化时。在这个领域做出工具决策时,需要考虑以下几个重要因素:
- 每个员工每次的成本是多少?一些工具选项可能会花很多钱!
- 该工具是否有适当的连接器来与transformers数据源和堆栈的其余部分集成?
- 该工具是否适合团队的技术能力(SQL、Spark、Python 等)?
- 该工具提供什么样的支持(企业、社区等)?
更多干货,第一时间更新在以下微信公众号:

您的一点点支持,是我后续更多的创造和贡献

转载到请包括本文地址 更详细的转载事宜请参考文章如何转载/引用
本文主体源自以下链接:
@article{madewithml,
author = {Goku Mohandas},
title = { Made With ML },
howpublished = {\url{https://madewithml.com/}},
year = {2022}
}