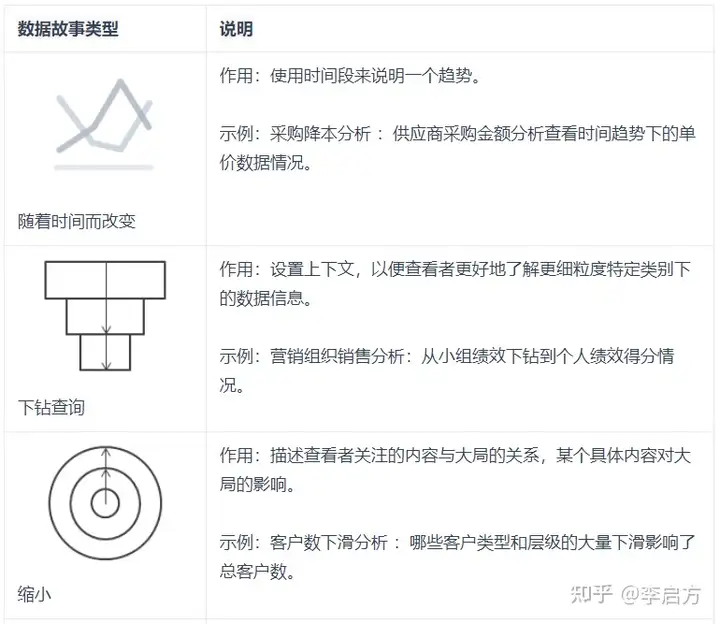
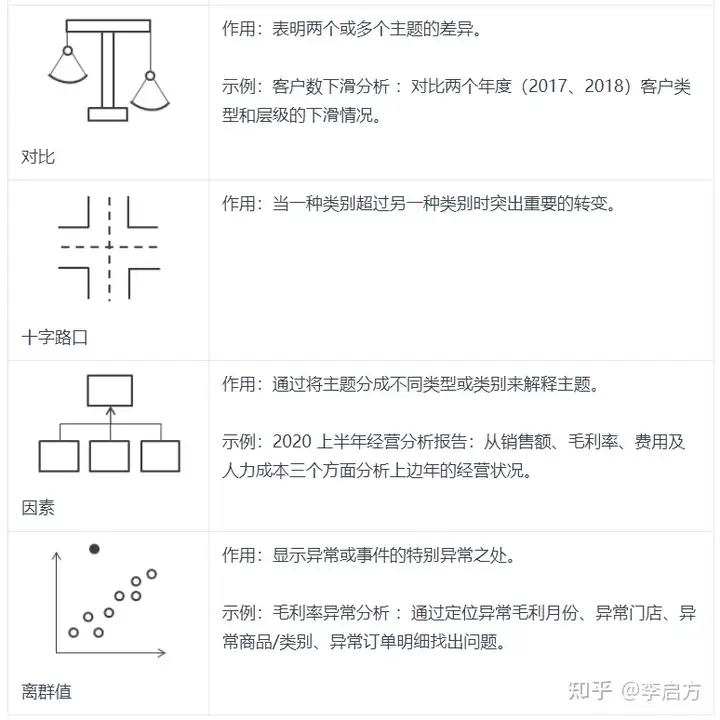
数据分析时的七种思路
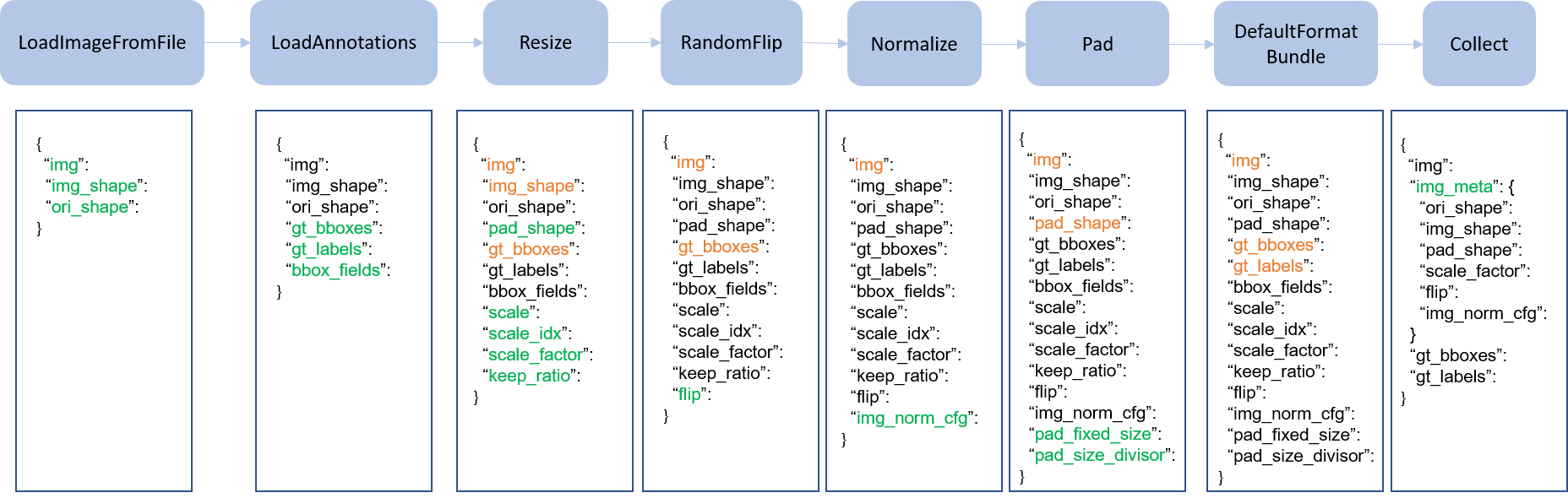
版面分析 ü 二级版面标签(语义标签) ü 业内数量最多的版面标签 • 跨页合并 ü 跨页段落合并 ü 跨页表格合并 ü 跨页表格单元格合并 • 文档逻辑结构 ü 父子层级树 ü 指代等关系


内置属性:样本级别难例原因ID列表。。难例原因ID可选值如下:
-
0:未识别出任何目标物体。
-
1:置信度偏低。
-
2:基于训练数据集的聚类结果和预测结果不一致。
-
3:预测结果和训练集同类别数据差异较大。
-
4:连续多张相似图片的预测结果不一致。
-
5:图像的分辨率与训练数据集的特征分布存在较大偏移。
-
6:图像的高宽比与训练数据集的特征分布存在较大偏移。
-
7:图像的亮度与训练数据集的特征分布存在较大偏移。
-
8:图像的饱和度与训练数据集的特征分布存在较大偏移。
-
9:图像的色彩丰富程度与训练数据集的特征分布存在较大偏移。
-
10:图像的清晰度与训练数据集的特征分布存在较大偏移。
-
11:图像的目标框数量与训练数据集的特征分布存在较大偏移。
-
12:图像中目标框的面积标准差与训练数据集的特征分布存在较大偏移。
-
13:图像中目标框的高宽比与训练数据集的特征分布存在较大偏移。
-
14:图像中目标框的面积占比与训练数据集的特征分布存在较大偏移。
-
15:图像中目标框的边缘化程度与训练数据集的特征分布存在较大偏移。
-
16:图像中目标框的亮度与训练数据集的特征分布存在较大偏移。
-
17:图像中目标框的清晰度与训练数据集的特征分布存在较大偏移。
-
18:图像中目标框的堆叠程度与训练数据集的特征分布存在较大偏移。
-
19:基于gaussianblur的数据增强与原图预测结果不一致。
-
20:基于fliplr的数据增强与原图预测结果不一致。
-
21:基于crop的数据增强与原图预测结果不一致。
-
22:基于flipud的数据增强与原图预测结果不一致。
-
23:基于scale的数据增强与原图预测结果不一致。
-
24:基于translate的数据增强与原图预测结果不一致。
-
25:基于shear的数据增强与原图预测结果不一致。
-
26:基于superpixels的数据增强与原图预测结果不一致。
-
27:基于sharpen的数据增强与原图预测结果不一致。
-
28:基于add的数据增强与原图预测结果不一致。
-
29:基于invert的数据增强与原图预测结果不一致。
-
30:数据被预测为异常点。
| alg | dataset | function | test | script | |
|---|---|---|---|---|---|
| structure | voc_pubtables1m | browse_dataset.py | visual | test_browse_dataset_voc_pubtables1m_dataset_structure | ok |
| structure | voc_pubtables1m_to_tablemaster | browse_table_dataset.py | visual | test_browse_table_dataset_voc_pubtables1m_to_tablemaster_dataset_structure | ok |
| detection | voc_pubtables1m | browse_dataset.py | visual | test_browse_dataset_voc_pubtables1m_dataset_detection | ok |
| detection | coco | browse_dataset.py | visual | test_browse_dataset_coco_dataset | ok |
| structure | voc_pubtables1m_to_tablemaster | test.py | infer,metric | test_mmdet_testpy_voc_pub1m_tablemaster_dataset | |
| structure | coco | test.py | infer | test_mmocr_testpy_coco_selflabel_dataset test_mmdet_testpy_coco_selflabel_dataset test_mmdet_testpy_coco_selflabel_dataset_linux |
ok |
| structure | voc_pubtables1m | dataset_analysis.py | analysis | test_dataset_analysis_voc_pubtables1m_dataset | ok |
| structure | voc_pubtables1m_to_tablemaster | train.py | train | test_trainpy_voc_pubtables1m_tablemaster_dataset_structure |
| format | |||
|---|---|---|---|
| voc_pub1m_html | voc | ||
| pubtabnet | pubtabnet | ||
| syntabnet | Fintabnet | pubtabnet | |
| marketing | |||
| pubtabnet | |||
| sparse | |||
| selflabel | coco | ||
| selfprelabel | pubtabnet | ||
| load | ||
| noload | ||
| wind | ||
|---|---|---|
| linux |
{model}_[model setting]_{backbone}_{neck}_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset}
tablemaster_tableL1Loss_8x2_1x_voc_pub1m_html_load_wind
We follow the below style to name config files. Contributors are advised to follow the same style.
{model}_[model setting]_{backbone}_{neck}_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset}
`{xxx}` is required field and `[yyy]` is optional.
- `{model}`: model type like `faster_rcnn`, `mask_rcnn`, etc.
- `[model setting]`: specific setting for some model, like `without_semantic` for `htc`, `moment` for `reppoints`, etc.
- `{backbone}`: backbone type like `r50` (ResNet-50), `x101` (ResNeXt-101).
- `{neck}`: neck type like `fpn`, `pafpn`, `nasfpn`, `c4`.
- `[norm_setting]`: `bn` (Batch Normalization) is used unless specified, other norm layer type could be `gn` (Group Normalization), `syncbn` (Synchronized Batch Normalization). `gn-head`/`gn-neck` indicates GN is applied in head/neck only, while `gn-all` means GN is applied in the entire model, e.g. backbone, neck, head.
- `[misc]`: miscellaneous setting/plugins of model, e.g. `dconv`, `gcb`, `attention`, `albu`, `mstrain`.
- `[gpu x batch_per_gpu]`: GPUs and samples per GPU, `8x2` is used by default.
- `{schedule}`: training schedule, options are `1x`, `2x`, `20e`, etc. `1x` and `2x` means 12 epochs and 24 epochs respectively. `20e` is adopted in cascade models, which denotes 20 epochs. For `1x`/`2x`, initial learning rate decays by a factor of 10 at the 8/16th and 11/22th epochs. For `20e`, initial learning rate decays by a factor of 10 at the 16th and 19th epochs.
- `{dataset}`: dataset like `coco`, `cityscapes`, `voc_0712`, `wider_face`.
| DOD/TD | self_study v2.0 | self_study v2.0 | self_study v1.0 | self_study v1.0 |
|---|---|---|---|---|
| hmean-iou | hmean-ic13 | hmean-iou | hmean-ic13 | |
| 专利 | 0.8804 | 0.8893 | 0.8502 | 0.8526 |
| 期刊 | 0.9053 | 0.9081 | 0.8323 | 0.8323 |
| TSR | teds | precisions@0.10 | recalls@0.10 |
|---|---|---|---|
| 期刊 | 0.8945 | 0.8521 | 0.3914 |
| teds | AP50 | p@0.10 | r@0.10 | p@0.20 | r@0.20 | |
|---|---|---|---|---|---|---|
| 自研1.0+20221214数据finetune | 0.9542 | 0.2648 | 0.9678 | 0.4633 | 0.8964 | 0.4274 |
| 原模型+20221214数据finetune | 0.9508 | 0.2536 | 0.9649 | 0.4622 | 0.8928 | 0.4258 |
| 自研1.0 | 0.8945 | 0.0350 | 0.8522 | 0.3914 | 0.5809 | 0.2645 |
| 原模型 | 0.8924 | 0.0302 | 0.8206 | 0.3764 | 0.5361 | 0.2443 |
微调
新数据集和原始数据集合类似,那么直接可以微调一个最后的FC 层 或者重新指定一个新的分类器
- 新数据集比较小和原始数据集合差异性比较大,那么可以使用从模型
的中部开始训练,只对最后几层进行fine-tuning
- 新数据集比较小和原始数据集合差异性比较大,如果上面方法还是不 行的化那么最好是重新训练,只将预训练的模型作为一个新模型初始 化的数据
- 新数据集的大小一定要与原始数据集相同,比如CNN中输入的图片 大小一定要相同,才不会报错
- 如果数据集大小不同的话,可以在最后的fc层之前添加卷积或者 pool 层,使得最后的输出与fc层一致,但这样会导致准确度大幅下 降,所以不建议这样做
- 对于不同的层可以设置不同的学习率,一般情况下建议,对于使用的 原始数据做初始化的层设置的学习率要小于(一般可设置小于10 倍)初始化的学习率,这样保证对于已经初始化的数据不会扭曲的过 快,而使用初始化学习率的新层可以快速的收敛。
测试深度学习模型
深度学习模型是机器学习子集,与传统的机器学习模型相比,它们通常具有更复杂的架构并且需要更多的数据来训练。
与测试传统机器学习模型相比,测试深度学习模型可能有一些额外的考虑因素:
-
过拟合:深度学习模型更容易过度拟合,这意味着它们在训练数据上表现良好,但在看不见的测试数据上表现不佳。
-
计算复杂性:深度学习模型是计算密集型的,这意味着测试可能需要更长的时间才能运行并且需要更多的计算资源。
-
模型可解释性:深度学习模型比传统机器学习模型更难解释。
除了上述注意事项之外,测试机器学习模型的整个过程也适用于深度学习模型。
测试实施清单
-
为所有代码单元编写单元测试
-
编写集成测试以检查单元之间的集成
-
写一些系统测试。
-
进行良好语法检查
-
记录测试文档
-
验证运行测试所需的资源
-
选择并使用测试框架
-
定期运行测试
-
自动化运行测试的过程
-
不断改善代码覆盖率
