利用版本控制管理代码、数据和模型
对代码、数据和模型进行版本控制,以确保 ML 系统中的可重现性。
intuition
学习了如何对代码进行版本控制,但还需要跟踪和版本化其它几类非常重要的工件:配置、数据和模型。重要的是对所有内容进行版本控制,以便可以随时重现完全相同的应用程序。将通过使用 Git 提交作为用于生成特定模型的代码、配置和数据的快照来做到这一点。以下是需要合并的关键元素,以使应用程序完全可重现:
- 存储库应该存储指向大数据的指针和存在于 Blob 存储中的模型工件。
- 使用提交来存储代码、配置、数据和模型的快照,并能够更新和回滚版本。
- 公开配置,以便可以查看和比较参数。
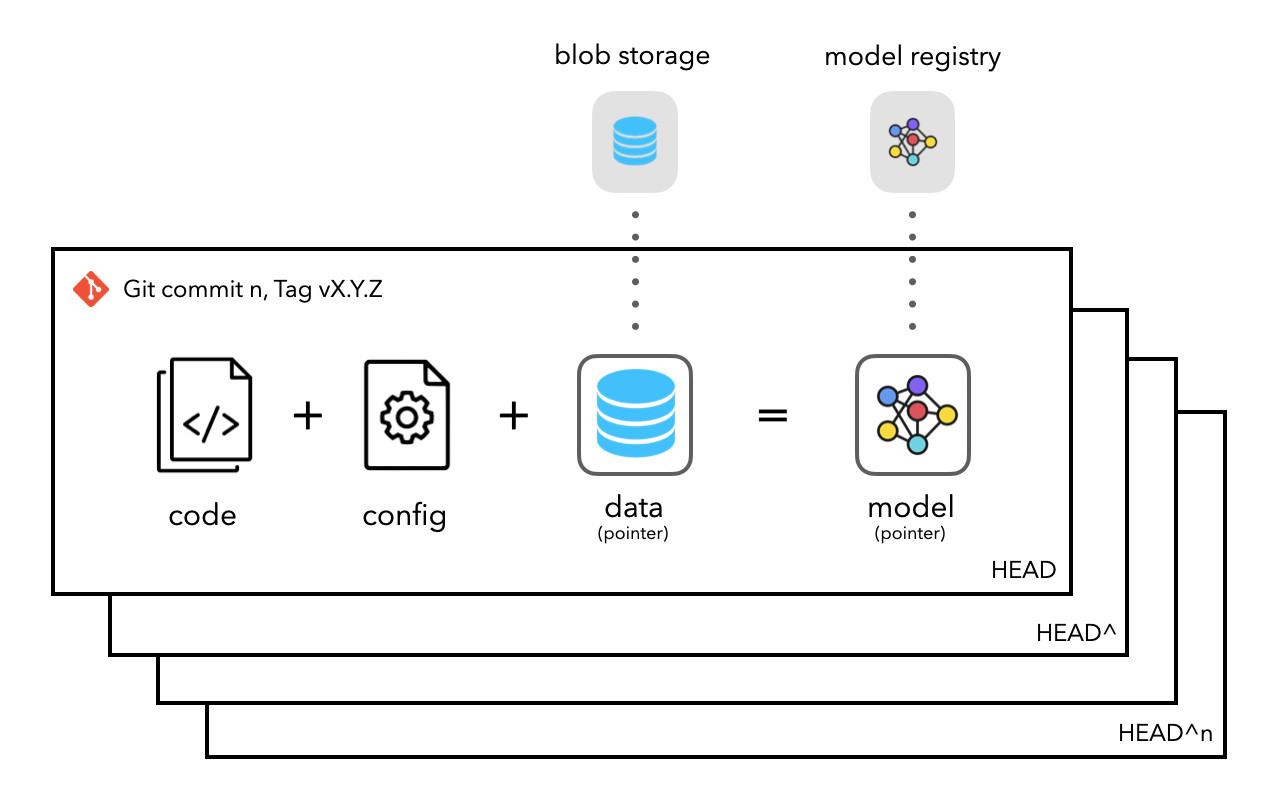
应用
有许多工具可用于对工件进行版本控制(GitLFS、Dolt、Pachyderm等),但将使用数据版本控制 (DVC)库,因为它简单、功能丰富且最重要的是模块化。DVC 有许多其他有用的功能(指标、实验等),所以一定要探索这些。
将使用 DVC 对数据集和模型权重进行版本控制,并将它们存储在本地目录中,该目录将充当 blob 存储。可以使用远程 blob 存储选项,例如 S3、GCP、Google Drive、DAGsHub等,但将在本地复制相同的操作,以便查看数据的存储方式。
将使用本地目录作为 blob 存储,以便可以在本地开发和分析所有内容。将继续为其他存储组件以及功能存储等执行此操作,就像对本地模型注册表所做的那样。
设置
让首先安装 DVC 并对其进行初始化以创建一个.dvc目录。
# Initialization
pip install dvc==2.10.2
dvc init
请务必将此包和版本添加到
requirements.txt文件中。
远程存储
初始化 DVC 后,可以确定远程存储的位置。将创建并使用该stores/blob目录作为远程存储,但在生产环境中,这将类似于 S3。将在文件中定义 blob 存储config/config.py:
# Inside config/config.py
BLOB_STORE = Path(STORES_DIR, "blob")
BLOB_STORE.mkdir(parents=True, exist_ok=True)
将快速运行配置脚本,以便创建此存储:
应该看到 blob 存储:
stores/
├── blob
└── model
需要通知 DVC 这个存储位置,以便它知道将数据assert保存在哪里:
dvc remote add -d storage stores/blob
Setting 'storage' as a default remote.
note
如果与其他开发人员合作,还可以使用远程 blob 存储选项,例如 S3、GCP、Google Drive、DAGsHub等。例如,以下是如何设置 S3 存储桶来保存版本化数据:
# Create bucket: https://docs.aws.amazon.com/AmazonS3/latest/userguide/creating-bucket.html
# Add credentials: https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-files.html
dvc remote modify storage access_key_id ${AWS_ACCESS_KEY_ID}
dvc remote modify storage secret_access_key ${AWS_SECRET_ACCESS_KEY}
dvc remote add -d storage s3://<BUCKET_NAME>
添加数据
现在已准备好将数据添加到远程存储中。这将自动将相应的数据assert添加到.gitignore文件中(将在目录中创建一个新文件data)并创建指向数据assert实际存储位置的指针文件(远程存储)。但首先,需要data从文件中删除目录.gitignore(否则 DVC 会抛出_git-ignored_错误)。
# Inside our .gitignore
logs/
stores/
# data/ # remove or comment this line
现在准备添加数据assert:
# Add artifacts
dvc add data/projects.csv
dvc add data/tags.csv
dvc add data/labeled_projects.csv
现在应该看到自动创建的data/.gitignore文件:
# data/.gitignore
/projects.csv
/tags.csv
/labeled_projects.csv
以及为添加的每个数据工件创建的所有指针文件:
data
├── .gitignore
├── labeled_projects.csv
├── labeled_projects.csv.dvc
├── projects.csv
├── projects.csv.dvc
├── tags.csv
└── tags.csv.dvc
每个指针文件将包含 md5 哈希、大小和位置(相对于data目录),将检查到 git 存储库中。
|
note
对模型组件进行版本控制方面,不会将任何内容推送到 blob 存储中,因为模型注册表已经处理了所有这些。相反,在
config目录中公开运行 ID、参数和性能,以便可以轻松查看结果并将它们与其他本地运行进行比较。对于非常大的应用程序或在生产中有多个模型的情况下,这些组件将存储在元数据或评估存储中,其中它们将由模型运行 ID 进行索引。
push
现在准备好将工件推送到 blob 存储:
3 files pushed
如果检查存储(stores/blob),会看到数据被有效地存储:
# Remote storage
stores
└── blob
├── 3e
│ └── 173e183b81085ff2d2dc3f137020ba
├── 72
│ └── 2d428f0e7add4b359d287ec15d54ec
...
note
如果忘记添加或推送组件,可以将其添加为预提交hook,以便在尝试提交时自动发生。如果版本化文件没有更改,则不会发生任何事情。
# Makefile .PHONY: dvc dvc: dvc add data/projects.csv dvc add data/tags.csv dvc add data/labeled_projects.csv dvc push # .pre-commit-config.yaml - repo: local hooks: - id: dvc name: dvc entry: make args: ["dvc"] language: system pass_filenames: falsepush
pull
当其他人想要拉取数据assert时,可以使用该pull命令从远程存储中获取到本地目录。需要的只是首先确保拥有最新的指针文件(通过git pull),然后从远程存储中提取。
可以通过删除数据文件(
.json不是.dvc指针的文件)来快速测试这一点,然后运行dvc pull以从 blob 存储中加载文件。
运营
当从源或计算特征中提取数据时,它们应该保存数据本身还是只保存操作?
- 版本化数据
- 如果 (1) 数据是可管理的,(2) 如果团队是小型/早期 ML 或 (3) 如果对数据的更改不频繁,则这没关系。
- 但是随着数据变得越来越大并且不断复制它会发生什么。
- 版本化操作
- 可以保留数据的快照(与项目分开)并提供操作和时间戳,可以对这些数据快照执行操作,以重新创建用于训练的精确数据工件。许多数据系统使用time-travel来有效地实现这一目标。
- 但最终这也会导致数据存储量大。需要的是一个 仅追加的数据源,其中所有更改都保存在日志中,而不是直接更改数据本身。因此,可以使用带有日志的数据系统来生成数据的版本,而不必存储数据本身的单独快照。
更多干货,第一时间更新在以下微信公众号:

您的一点点支持,是我后续更多的创造和贡献

转载到请包括本文地址 更详细的转载事宜请参考文章如何转载/引用
本文主体源自以下链接:
@article{madewithml,
author = {Goku Mohandas},
title = { Made With ML },
howpublished = {\url{https://madewithml.com/}},
year = {2022}
}