评估机器学习模型
通过整体、每类和slice性能来评估 ML 模型。
intuition
评估是建模的一个组成部分,它经常被忽略。经常会发现评估只涉及计算准确性或其它全局指标,但对于许多实际工作应用程序,需要更细致的评估过程。然而,在评估模型之前,总是希望:
- 清楚优先考虑的指标
- 注意不要过度优化任何一个指标,因为这可能意味着你正在妥协其他指标
# Metrics
metrics = {"overall": {}, "class": {}}
# Data to evaluate
other_index = label_encoder.class_to_index["other"]
y_prob = model.predict_proba(X_test)
y_pred = custom_predict(y_prob=y_prob, threshold=threshold, index=other_index)
粗粒度
在迭代开发基线时,评估过程涉及计算粗粒度指标,例如整体精度、召回率和 f1 指标。
from sklearn.metrics import precision_recall_fscore_support
# Overall metrics
overall_metrics = precision_recall_fscore_support(y_test, y_pred, average="weighted")
metrics["overall"]["precision"] = overall_metrics[0]
metrics["overall"]["recall"] = overall_metrics[1]
metrics["overall"]["f1"] = overall_metrics[2]
metrics["overall"]["num_samples"] = np.float64(len(y_test))
print (json.dumps(metrics["overall"], indent=4))
{
“precision”:0.8990934378802025,
“recall”:0.8194444444444444,
“f1”:0.838280325954406,
“num_samples”:144.0
}
note
来自 scikit-learn的precision_recall_fscore_support()函数有一个名为的输入参数
average,它具有以下选项。将对不同的度量粒度使用不同的平均方法。
None:针对每个唯一类计算指标。binary:用于pos_label指定 的二进制分类任务。micro: 使用全局 TP、FP 和 FN 计算指标。macro:在不考虑类不平衡的情况下平均每类指标。weighted:通过考虑类不平衡来平均的每类指标。samples:指标是在每个样本级别计算的。
细粒度
检查这些粗粒度的整体指标是一个开始,但可以更深入分析通过在分类特征级别评估相同的细粒度指标。
from collections import OrderedDict
# Per-class metrics
class_metrics = precision_recall_fscore_support(y_test, y_pred, average=None)
for i, _class in enumerate(label_encoder.classes):
metrics["class"][_class] = {
"precision": class_metrics[0][i],
"recall": class_metrics[1][i],
"f1": class_metrics[2][i],
"num_samples": np.float64(class_metrics[3][i]),
}
# Metrics for a specific class
tag = "natural-language-processing"
print (json.dumps(metrics["class"][tag], indent=2))
{
"precision": 0.9803921568627451,
"recall": 0.8620689655172413,
"f1": 0.9174311926605505,
"num_samples": 58.0
}
# Sorted tags
sorted_tags_by_f1 = OrderedDict(sorted(
metrics["class"].items(), key=lambda tag: tag[1]["f1"], reverse=True))
for item in sorted_tags_by_f1.items():
print (json.dumps(item, indent=2))
[
"natural-language-processing",
{
"precision": 0.9803921568627451,
"recall": 0.8620689655172413,
"f1": 0.9174311926605505,
"num_samples": 58.0
}
]
[
"mlops",
{
"precision": 0.9090909090909091,
"recall": 0.8333333333333334,
"f1": 0.8695652173913043,
"num_samples": 12.0
}
]
[
"computer-vision",
{
"precision": 0.975,
"recall": 0.7222222222222222,
"f1": 0.8297872340425532,
"num_samples": 54.0
}
]
[
"other",
{
"precision": 0.4523809523809524,
"recall": 0.95,
"f1": 0.6129032258064516,
"num_samples": 20.0
}
]
由于自定义预测功能,能够对除
other外根据产品设计,决定更重要的是准确了解显式 ML 类别(nlp、cv 和 mlops),并且将有一个手动标记工作流程来召回该类别中的任何错误other分类。随着时间的推移,模型在这个类别中也会变得更好。
混淆矩阵
除了检查每个类的指标外,还可以识别真阳性、假阳性和假阴性。这些中的每一个都将让深入了解模型,超出指标所能提供的范围。
- 真阳性(TP):了解模型在哪些方面表现良好。
- 误报(FP):潜在地识别可能需要重新标记的样本。
- 假阴性 (FN):识别模型性能较差的区域,以便稍后进行过采样。
如果想要修复它们的标签并让这些更改在任何地方反映出来,将 FP/FN 样本反馈到 annotation pipelines中是一件好事。
# TP, FP, FN samples
tag = "mlops"
index = label_encoder.class_to_index[tag]
tp, fp, fn = [], [], []
for i, true in enumerate(y_test):
pred = y_pred[i]
if index==true==pred:
tp.append(i)
elif index!=true and index==pred:
fp.append(i)
elif index==true and index!=pred:
fn.append(i)
print (tp)
print (fp)
print (fn)
[1, 3, 4, 41, 47, 77, 94, 127, 138]
[14, 88]
[30, 71, 106]
index = tp[0]
print (X_test_raw[index])
print (f"true: {label_encoder.decode([y_test[index]])[0]}")
print (f"pred: {label_encoder.decode([y_pred[index]])[0]}")
pytest pytest framework makes easy write small tests yet scales support complex functional testing
true: mlops
pred: mlops
# Samples
num_samples = 3
cm = [(tp, "True positives"), (fp, "False positives"), (fn, "False negatives")]
for item in cm:
if len(item[0]):
print (f"\n=== {item[1]} ===")
for index in item[0][:num_samples]:
print (f" {X_test_raw[index]}")
print (f" true: {label_encoder.decode([y_test[index]])[0]}")
print (f" pred: {label_encoder.decode([y_pred[index]])[0]}\n")
=== True positives ===
pytest pytest framework makes easy write small tests yet scales support complex functional testing
true: mlops
pred: mlops
test machine learning code systems minimal examples testing machine learning correct implementation expected learned behavior model performance
true: mlops
pred: mlops
continuous machine learning cml cml helps organize mlops infrastructure top traditional software engineering stack instead creating separate ai platforms
true: mlops
pred: mlops
=== False positives ===
paint machine learning web app allows create landscape painting style bob ross using deep learning model served using spell model server
true: computer-vision
pred: mlops
=== False negatives ===
hidden technical debt machine learning systems using software engineering framework technical debt find common incur massive ongoing maintenance costs real world ml systems
true: mlops
pred: other
neptune ai lightweight experiment management tool fits workflow
true: mlops
pred: other
TIP
使用基于规则的方法进行此类分析以捕捉非常明显的标签错误是一个非常好的主意。
Confident learning
虽然混淆矩阵样本分析是一个粗粒度的过程,但也可以使用基于置信度的细粒度方法来识别可能被错误标记的样本。在这里,将关注特定的标签质量,而不是最终的模型预测。
简单的基于置信度的技术包括识别具有以下特征的样本:
-
分类的
- 预测不正确(也表示TN、FP、FN)
- 正确类别的置信度分数低于阈值
- 错误类别的置信度分数高于阈值
- 前 N 个样本的置信度得分的标准差较低
- 使用不同参数的同一模型的不同预测
-
连续的
- 预测值和真实值之间的差异高于某个百分比
# y
y_prob = model.predict_proba(X_test)
print (np.shape(y_test))
print (np.shape(y_prob))
# Used to show raw text
test_df = pd.DataFrame({"text": X_test_raw, "tag": label_encoder.decode(y_test)})
# Tag to inspect
tag = "mlops"
index = label_encoder.class_to_index[tag]
indices = np.where(y_test==index)[0]
# Confidence score for the correct class is below a threshold
low_confidence = []
min_threshold = 0.5
for i in indices:
prob = y_prob[i][index]
if prob <= 0.5:
low_confidence.append({"text": test_df.text[i],
"true": label_encoder.index_to_class[y_test[i]],
"pred": label_encoder.index_to_class[y_pred[i]],
"prob": prob})
[{'pred': '其他',
“prob”:0.41281721056332804,
'text': 'neptune ai lightweight experiment management tool fits workflow',
'true':'mlops'}]
但这些都是相当粗糙的技术,因为神经网络很容易过度自信,因此如果不校准它们就无法使用它们的置信度。
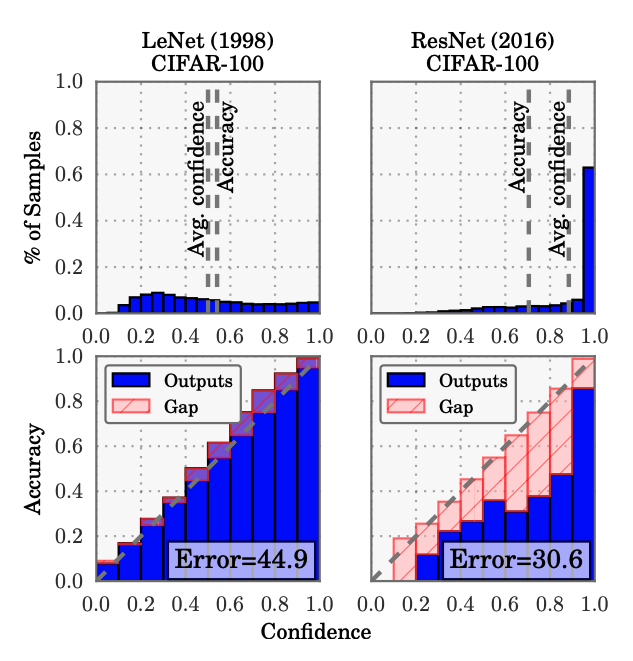
- 假设:“与预测的类标签相关的概率应该反映其真实正确性的可能性。”
- 现实:“现代(大型)神经网络不再经过良好校准”
- 解决方案:在模型输出上应用temperature scaling(普拉特缩放的扩展)
最近关于自信学习( cleanlab ) 的工作侧重于识别嘈杂的标签(通过校准),然后可以正确地重新标记并用于训练。
pip install cleanlab==1.0.1 -q
import cleanlab
from cleanlab.pruning import get_noise_indices
# Determine potential labeling errors
label_error_indices = get_noise_indices(
s=y_test,
psx=y_prob,
sorted_index_method="self_confidence",
verbose=0)
并非所有这些都必然是标签错误,而是预测概率不那么自信的情况。因此,将预测结果与附带结果相结合将是有用的。这样,可以知道是否需要重新标记、上采样等作为缓解策略来提高性能。
num_samples = 5
for index in label_error_indices[:num_samples]:
print ("text:", test_df.iloc[index].text)
print ("true:", test_df.iloc[index].tag)
print ("pred:", label_encoder.decode([y_pred[index]])[0])
print ()
text: module 2 convolutional neural networks cs231n lecture 5 move fully connected neural networks convolutional neural networks
true: computer-vision
pred: other
本节中的操作可以应用于整个标记数据集,以通过置信度学习发现标记错误。
Manual slices手动切片
仅检查整体和类指标不足以将新版本部署到生产中。数据集可能有一些关键部分需要做得很好:
- 目标/预测类别(+ 组合)
- 特征(显式和隐式)
- 元数据(时间戳、来源等)
- Priority slices/experience(少数群体、大客户等)
创建和评估切片的一种简单方法是定义切片函数。
pip install snorkel==0.9.8 -q
from snorkel.slicing import PandasSFApplier
from snorkel.slicing import slice_dataframe
from snorkel.slicing import slicing_function
@slicing_function()
def nlp_cnn(x):
"""NLP Projects that use convolution."""
nlp_projects = "natural-language-processing" in x.tag
convolution_projects = "CNN" in x.text or "convolution" in x.text
return (nlp_projects and convolution_projects)
在这里,使用 Snorkelslicing_function来创建不同的切片。可以通过将此切片函数应用到相关的 DataFrame 来可视化切片slice_dataframe。
nlp_cnn_df = slice_dataframe(test_df, nlp_cnn)
nlp_cnn_df[["text", "tag"]].head()
text tags
126 understanding convolutional neural networks nl... natural-language-processing
short_text_df = slice_dataframe(test_df, short_text)
short_text_df[["text", "tag"]].head()
text tags
44 flashtext extract keywords sentence replace ke... natural-language-processing
62 tudatasets collection benchmark datasets graph... other
70 tsfresh automatic extraction relevant features... other
88 axcell automatic extraction results machine le... computer-vision
可以定义更多的切片函数并使用PandasSFApplier. slices 数组有 N(# 个数据点)项目,每个项目都有 S(# of slicing functions)项目,指示该数据点是否是该切片的一部分。将此记录数组视为数据上每个切片函数的屏蔽层。
# Slices
slicing_functions = [nlp_cnn, short_text]
applier = PandasSFApplier(slicing_functions)
slices = applier.apply(test_df)
slices
rec.array([(0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0),
(1, 0) (0, 0) (0, 1) (0, 0) (0, 0) (1, 0) (0, 0) (0, 0) (0, 1) (0, 0)
...
(0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 1),
(0, 0), (0, 0)],
dtype=[('nlp_cnn', '<i8'), ('short_text', '<i8')])
要计算切片的指标,可以使用snorkel.analysis.Scorer,但已经实现了一个适用于多类或多标签场景的版本。
# Score slices
metrics["slices"] = {}
for slice_name in slices.dtype.names:
mask = slices[slice_name].astype(bool)
if sum(mask):
slice_metrics = precision_recall_fscore_support(
y_test[mask], y_pred[mask], average="micro"
)
metrics["slices"][slice_name] = {}
metrics["slices"][slice_name]["precision"] = slice_metrics[0]
metrics["slices"][slice_name]["recall"] = slice_metrics[1]
metrics["slices"][slice_name]["f1"] = slice_metrics[2]
metrics["slices"][slice_name]["num_samples"] = len(y_test[mask])
print(json.dumps(metrics["slices"], indent=2))
{
"nlp_cnn": {
"precision": 1.0,
"recall": 1.0,
"f1": 1.0,
"num_samples": 1
},
"short_text": {
"precision": 0.8,
"recall": 0.8,
"f1": 0.8000000000000002,
"num_samples": 5
}
}
切片可以帮助识别数据中的 偏差 来源。例如,模型很可能已经学会了将算法与某些应用程序相关联,例如用于计算机视觉的 CNN 或用于 NLP 项目的转换器。然而,这些算法并没有被应用到它们最初的用例之外。需要确保模型学会专注于应用而不是算法。这可以通过以下方式学习:
- 足够的数据(新的或过采样的不正确预测)
- 屏蔽算法(使用文本匹配启发式)
Generated slices生成的切片
与粗粒度评估相比,手动创建切片是识别数据集中问题子集的巨大改进,但如果未能识别数据集中有问题的切片怎么办?SliceLine是最近的一项工作,它使用线性代数和基于剪枝的技术来识别大切片(指定最小切片大小),这些切片会导致前向传递产生有意义的错误。如果不进行剪枝,自动切片识别将变得计算密集,因为它涉及枚举数据点的许多组合以识别切片。但是使用这种技术,可以在数据集中发现没有明确寻找的隐藏的表现不佳的子集!
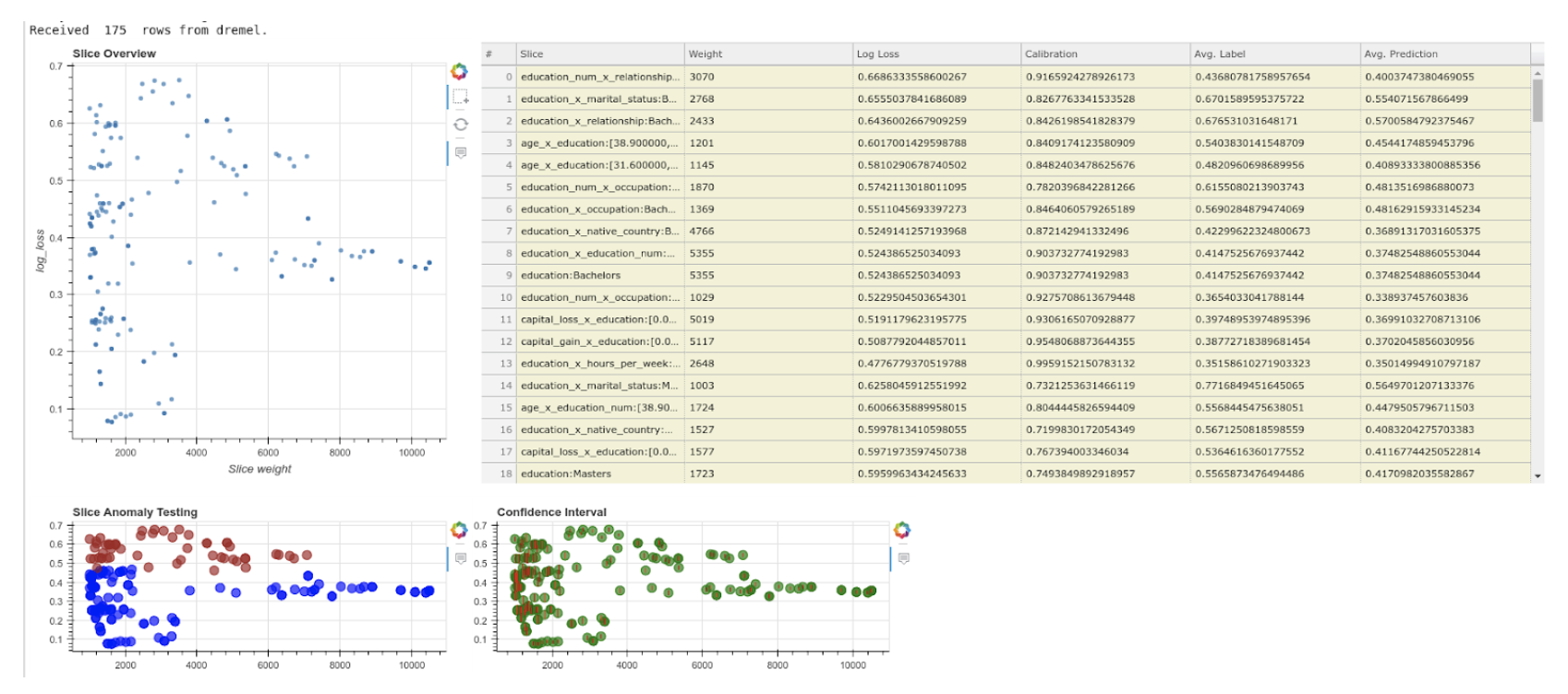
隐藏分层
如果生成切片的特征是隐式/隐藏的怎么办?

为了解决这个问题,最近出现了基于聚类的技术来识别这些隐藏切片并改进系统。
- 通过无监督聚类估计隐式子类标签
- 使用这些集群训练新的更强大的模型

模型修补
最近关于模型修补的另一项工作通过学习如何在子组之间进行转换,使更进一步,以便可以在增强数据上训练模型:
- 学习小组
- 学习在同一超类(标签)下从一个子组到另一个子组所需的转换(例如CycleGAN)
- 使用人为引入的子组特征来增强数据
- 在增强数据上训练新的稳健模型
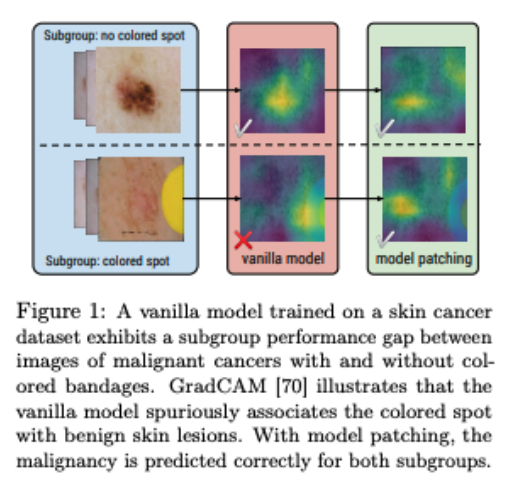
可解释性
除了将预测输出与真实值进行比较之外,还可以检查模型的输入。输入的哪些方面对预测的影响更大?如果重点不是输入的相关特征,那么需要探索是否存在遗漏的隐藏模式,或者模型是否已经学会过拟合不正确的特征。可以使用诸如SHAP (SHapley Additive exPlanations) 或LIME (Local Interpretable Model-agnostic Explanations) 等技术来检查特征重要性。在较高的层次上,这些技术通过评估它们不存在时的性能来了解哪些特征具有最大的信号。这些检查可以在全局级别(例如每类)或本地级别(例如单个预测)执行。
pip install lime==0.2.0.1 -q
from lime.lime_text import LimeTextExplainer
from sklearn.pipeline import make_pipeline
将 LIME 与 scikit-learn管道一起使用更容易,因此将矢量化器和模型组合到一个结构中。
# Create pipeline
pipe = make_pipeline(vectorizer, model)
# Explain instance
text = "Using pretrained convolutional neural networks for object detection."
explainer = LimeTextExplainer(class_names=label_encoder.classes)
explainer.explain_instance(text, classifier_fn=pipe.predict_proba, top_labels=1).show_in_notebook(text=True)
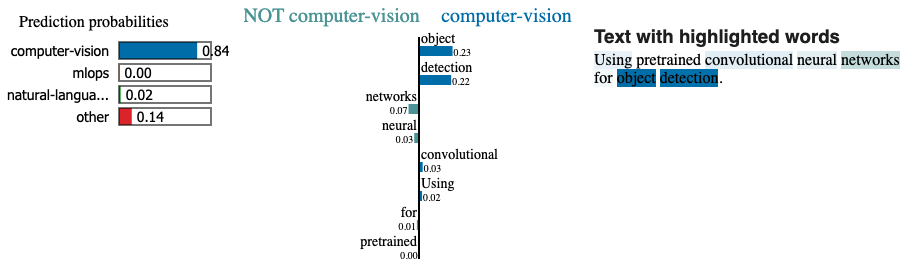
还可以使用在embeddings lesson中所做的特定于模型的可解释性方法来识别文本中最有影响力的 n-gram。
反事实
评估系统的另一种方法是识别反事实——具有相似特征的数据属于另一类(分类)或高于某个差异(回归)。这些点使能够评估模型对某些可能是过度拟合迹象的特征和特征值的敏感性。What-if 工具是识别和探测反事实的好工具(也适用于切片和公平指标)。
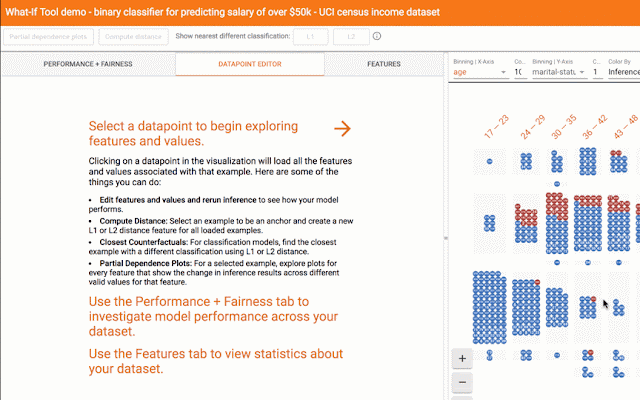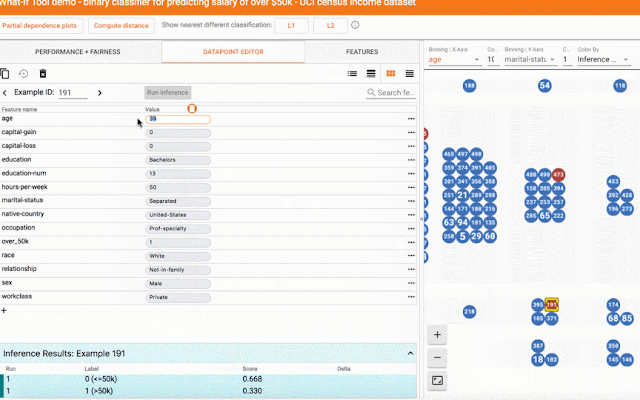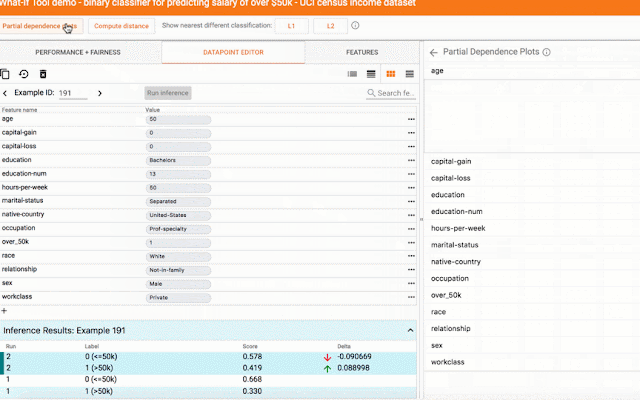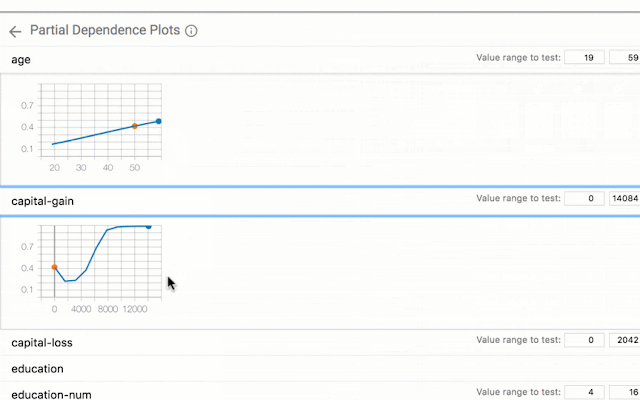
对于任务,这可能涉及使用算法的项目通常保留给某个应用领域(例如用于计算机视觉的 CNN 或用于 NLP 的转换器)。
行为测试
除了只看指标,还想进行一些行为健全性测试。行为测试是在将模型视为黑盒的同时测试输入数据和预期输出的过程。它们不一定在本质上是对抗性的,但更多的是在部署模型后将在现实世界中看到的扰动类型。关于这个主题的具有里程碑意义的论文是Beyond Accuracy: Behavioral Testing of NLP Models with CheckList,它将行为测试分为三种类型的测试:
invariance:更改不应影响输出。
# INVariance via verb injection (changes should not affect outputs)
tokens = ["revolutionized", "disrupted"]
texts = [f"Transformers applied to NLP have {token} the ML field." for token in tokens]
predict_tag(texts=texts)
['natural-language-processing', 'natural-language-processing']
directional:变化应该会影响产出。
# DIRectional expectations (changes with known outputs)
tokens = ["text classification", "image classification"]
texts = [f"ML applied to {token}." for token in tokens]
predict_tag(texts=texts)
['natural-language-processing', 'computer-vision']
minimum functionality:输入和预期输出的简单组合。
# Minimum Functionality Tests (simple input/output pairs)
tokens = ["natural language processing", "mlops"]
texts = [f"{token} is the next big wave in machine learning." for token in tokens]
predict_tag(texts=texts)
['natural-language-processing','mlops']
将在testing lesson中学习如何系统地创建测试。
Evaluating evaluations
如何知道模型和系统是否随着时间的推移表现得更好?不幸的是,根据重新训练的频率或数据集增长的速度,所有指标/切片的性能都优于以前的版本并不总是一个简单的决定。在这些情况下,重要的是要知道主要优先事项是什么以及可以在哪里有一些余地:
- 什么标准最重要?
- 哪些标准可以/不能回归?
- 可以容忍多少回归?
随着随着时间的推移制定这些标准,可以通过CI/CD 工作流系统地执行它们,以减少系统更新之间的手动时间。
看起来很简单,不是吗?
使用所有这些不同的评估方法,如果某些版本对某些评估标准更好,如何选择模型的“最佳”版本?
显示答案
团队需要就哪些评估标准最重要以及每个评估标准所需的最低绩效达成一致。这将允许通过删除不满足所有最低要求的解决方案并在其余解决方案中对最高优先级标准执行最佳的解决方案进行排名,从而在所有不同的解决方案中进行过滤。
在线评估
一旦评估了模型在静态数据集上执行的能力,就可以运行多种类型的在线评估技术来确定实际生产数据的性能。它可以使用标签来执行,或者在没有标签的情况下,proxy signals。
- 手动标记传入数据的子集以定期评估。
- 询问查看新分类内容的初始用户组是否正确分类。
- 允许用户通过模型报告错误分类的内容。
在承诺替换现有的系统版本之前,可以使用许多不同的实验策略来测量实时性能。
AB 测试
AB 测试涉及将生产流量发送到当前的系统(控制组)和新版本(处理组),并测量两个指标的值之间是否存在统计差异。AB 测试有几个常见问题,例如考虑不同的偏差来源,例如向某些用户展示新系统的新颖性效果。还需要确保相同的用户继续与相同的系统进行交互,以便可以比较结果而不会造成污染。
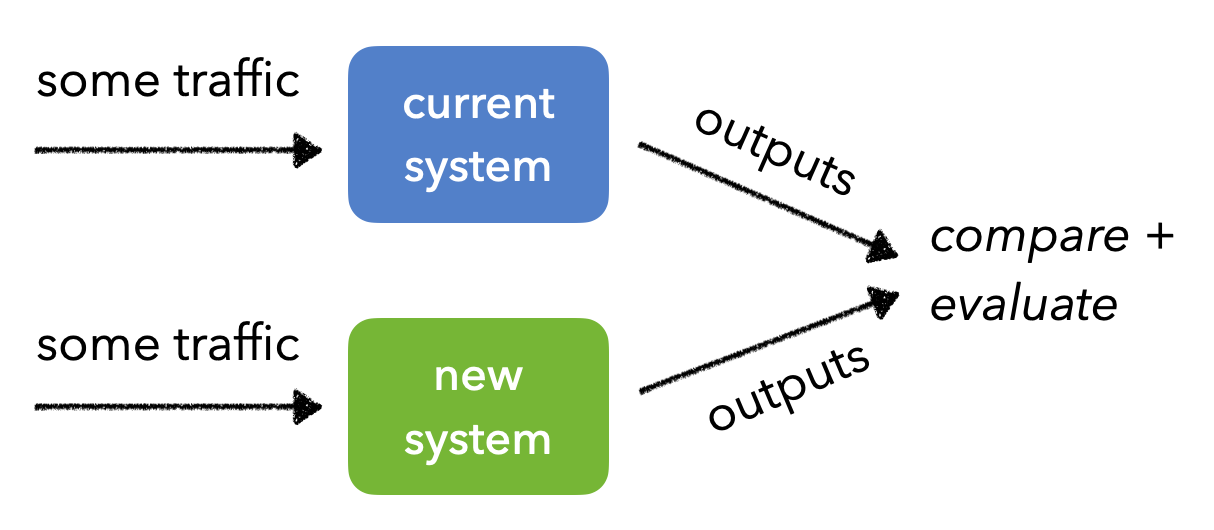
在许多情况下,如果只是尝试比较某个指标的不同版本,AB 测试可能需要一段时间才能达到静态显着性,因为流量在不同组之间平均分配。在这种情况下,multi-armed bandits将是一种更好的方法,因为它们会不断地将流量分配给性能更好的版本。
canary测试
Canary 测试涉及将大部分生产流量发送到当前部署的系统,但将一小部分用户的流量发送到正在尝试评估的新系统。同样,随着逐步推出新系统,需要确保相同的用户继续与相同的系统进行交互。
shadow测试
影子测试涉及将相同的生产流量发送到不同的系统。不必担心系统污染,并且与以前的方法相比非常安全,因为新系统的结果不可用。但是,确实需要确保尽可能多地复制生产系统,以便能够及早发现生产特有的问题。但总的来说,影子测试很容易监控、验证操作一致性等。
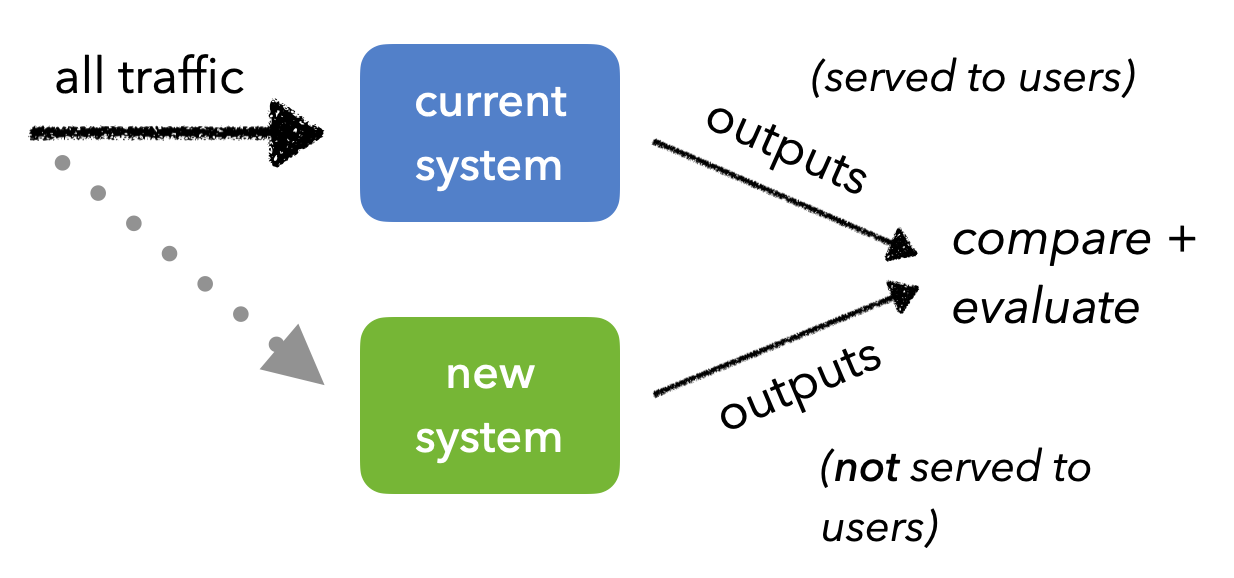
会出什么问题?
如果影子测试允许测试更新后的系统而无需实际提供新结果,为什么不是每个人都采用它?
显示答案
通过影子部署,将错过来自用户的任何实时反馈信号(显式/隐式),因为用户没有使用新版本直接与产品进行交互。
还需要确保尽可能多地复制生产系统,以便能够及早发现生产特有的问题。这是不可能的,因为虽然您的 ML 系统可能是一个独立的微服务,但它最终会与具有许多依赖项的复杂生产环境进行交互。
模型 CI
评估系统的一种有效方法是将它们封装为一个集合(suite)并将它们用于持续集成。将继续添加到评估suite中,并且在尝试对系统进行更改(新模型、数据等)时执行它们。通常,在监控期间识别出的有问题的数据切片通常会添加到评估测试suite中,以避免将来重复相同的回归。
Resources
- 机器学习中的模型评估、模型选择和算法选择
- 现代神经网络的标定
- 自信学习:估计数据集标签中的不确定性
- 用于模型验证的自动数据切片
- SliceLine:用于 ML 模型调试的快速、基于线性代数的切片查找
- 用于组转移的分布鲁棒神经网络
- 不遗漏任何子类:粗粒度分类问题中的细粒度鲁棒性
- 模型修补:通过数据增强缩小子组性能差距
更多干货,第一时间更新在以下微信公众号:

您的一点点支持,是我后续更多的创造和贡献

转载到请包括本文地址 更详细的转载事宜请参考文章如何转载/引用
本文主体源自以下链接:
@article{madewithml,
author = {Goku Mohandas},
title = { Made With ML },
howpublished = {\url{https://madewithml.com/}},
year = {2022}
}