一、整体要求
对医药期刊和专利文本图片,OCR字符标注,字符集为ascii码和latex码
二、标注对象
| 元素 | 定义 |
|---|---|
| ascii码 | 常见的数字和英文字母 |
| latex码 | 除常见的数字和英文字母外,非中文字符 |
| 中文 | 汉字,包括简体和繁体 |
典型样例
| 样例 | 标注规则 |
|---|---|
 |
抛弃冗余的边界被截断字符,标注为”7” |
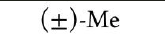 |
(\pm)-Me |
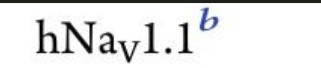 |
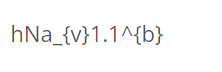 |
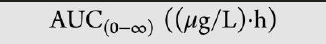 |
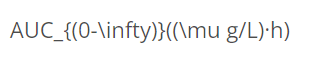 |
三、标注原则(按照阅读顺序横向文本-从左至右、竖向文本-也从左至右)
-
需分清楚大小写情况,比如Equal 不能标注成equal,除特殊难分辨大小写字母如C,O,W,U,S,Z,X,V
转写时,数字0、1、2需要和字母O、I(大写i)、Z、l(小写L)进行严格区分,不能相互替换 -
正负号标注为\pm ,
 连续三个点标注为 …
连续三个点标注为 … -
上标标注例如
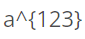 ,上标范围内的需要括号括住
,上标范围内的需要括号括住 -
下标标注例如
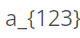 ,下标范围内的需要括号括住
,下标范围内的需要括号括住 -
有换行,标注为 \n
-
背景里的水印,忽略它的影响 ,字符下面有线的情况不考虑线的影响,如
 标注为A
标注为A -
空格文字转写规则
空格:只在分隔拼音/英文单词和表示替代时使用(中文、英文、数字、符号这四种类别相互之间即使图片上有空格,转写也均不能有空格)。
(1)中文与中文、英文、数字、符号之间均无空格(转写时需将图片中的空格忽略掉)
(2)数字与数字、符号之间均无空格
(3)英文与英文之间,图片上有空格,则转写需空格,图片上无空格,则转写无需空格
(4)同一英文单词内部字母间由字间距造成的空格,转写时无需空格(5)多个空格相连一起都标注为一个空格
-
标点符号
1). 标点符号分为通用标点符号和特殊标点符号
(1)①通用标点符号:键盘上能看到的所有标点符号(同时包含中/英状态下的标点符号)
(2)②特殊标点符号:键盘上能看到的以外的所有符号,例如✔↖↑↗←→↙↓↘▽◇☆等2). 如何标注 (1)中英文状态下形态一样符号,不必区分中英文符号:如:!?:,;-()” ‘ 等 应英文符号标注 (2) 中英文状态下形态不同的符号,中文符号:如【】[]「」 。. 《》<>等,找到对应英文符号标注
(3)破折号”–“和下划线”___“必须严格区分,不能互相替代
-
舍弃情况
1)小语种:非中、英文字母、非数字的其他语言(如:日、韩、阿拉伯语等其他语言),丢弃
-
注:特殊无法标注的,在备注栏标上,如内容不规则、图片清晰度等、背景干扰等 。只单独一个字符无法标注的用@字符标注,以做区分
-
除ascii码外非中文字符,其他字符以latex码为标准
#
五、附录
ASCII码
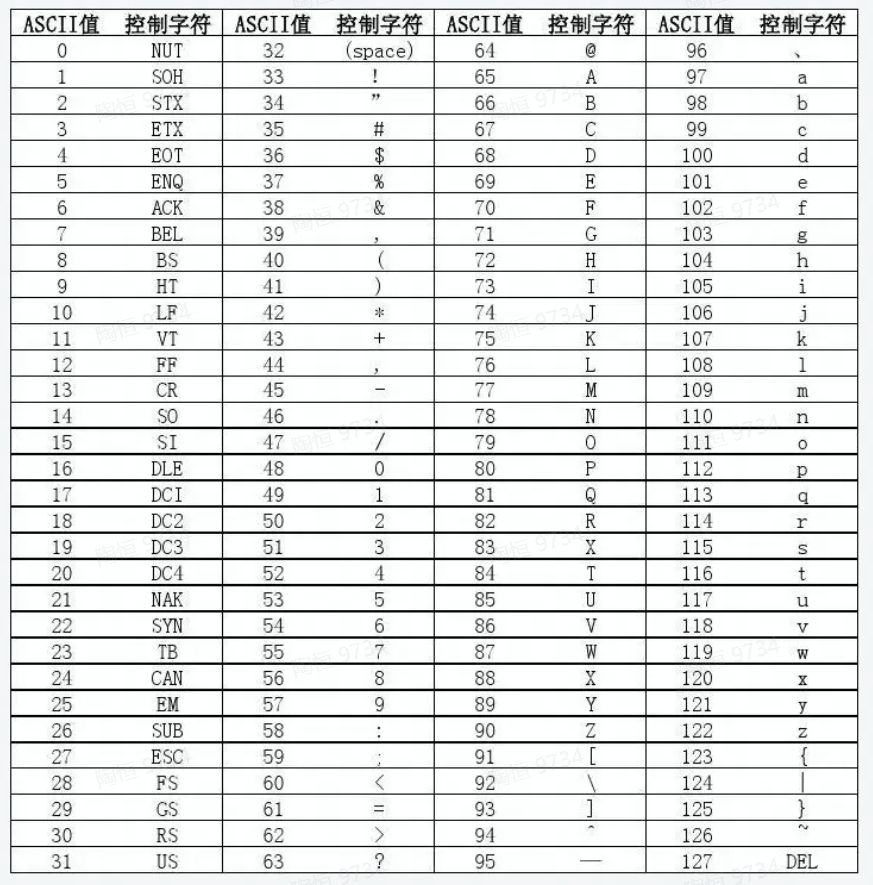
常用latex码
| 符号 | 标注 |
|---|---|
| 罗马数字 Ⅳ,IIII,Ⅴ |
\Roman{数字顺序} \Roman{4},\Roman{4},\Roman{5} |
 与a是不同,请注意 与a是不同,请注意 |
\alpha |
 |
\beta |
 |
\gamma |
 |
\delta |
 |
\theta |
  |
\lambda |
 |
\mu |
 |
\le |
 |
\ge |
 |
\equiv |
 |
\ne |
 |
\pm |
 |
\gets |
 |
\to |
 |
\infty |
 |
\AA |
| 非ASCII码,非以上latex码,非中文的 | \? |
| 化学分子式 | \ocsr |
5.交付标注文件夹格式和文件格式
文件夹格式
数据集1
|-- images
| |-- pdf文件名_物理页码_form表格序号.jpg
| |-- PMC6589332_12_form1.jpg
| |-- XXX.jpg
|-- voc_labels
| |-- pdf文件名_物理页码_form表格序号.xml
| |-- PMC6589332_12_form1.xml
| |-- XXX.xml
|-- coco.json
|-- voc_labels_withtablelabel
| |-- pdf文件名_物理页码_form表格序号.xml
| |-- PMC6589332_12_form1.xml
| |-- XXX.xml
|-- coco_withtablelabel.json
|-- block
| |-- pdf文件名_物理页码_form表格序号_从第几行_从第几列_到第几行_第几列.jpg
| |-- PMC6589332_12_form1_0_0_1_1.jpg
|-- label
| |-- pdf文件名_物理页码_form表格序号_从第几行_从第几列_到第几行_第几列.txt
| |-- PMC6589332_12_form1_0_0_1_1.txt
pdf文件名_物理页码_form表格序号_从第几行_从第几列_到第几行_第几列.txt(就只有一行)
0a8cef41e4b403a588af9f80a8563bb2_7_form1_0_0_1_1.jpg\1(注意是\1符号,后面的text也要注意换行符,会导致换行)compound
XXX.xml文件 voc数据格式
<?xml version="1.0" ?>
<annotation>
<folder/>
<filename>PMC6589332_11.jpg</filename>
<size>
<width>773</width>
<height>1000</height>
<depth>3</depth>
</size>
<object>
<supercategory>block</supercategory>
<name>block</name>
<bndbox>
<xmin>243.93609898386438</xmin>
<ymin>133.85618575895674</ymin>
<xmax>721.0680585873672</xmax>
<ymax>351.1486631451231</ymax>
</bndbox>
<bndbox_utf8_string>
<xmin>243.93609898386438</xmin>
<ymin>133.85618575895674</ymin>
<xmax>721.0680585873672</xmax>
<ymax>351.1486631451231</ymax>
</bndbox_utf8_string>
<utf8_string>table_header</utf8_string>
<bndbox_loc>
<xmin>0</xmin>
<ymin>0</ymin>
<xmax>1</xmax>
<ymax>1</ymax>
</bndbox_loc>
</object>
</annotation>
没有标注的文件那就是没有object
coco.json 文件 coco数据格式

{
"images": [
{
"id": 0,
"width": 1984,
"height": 2806,
"file_name": "0064177888b53c6667f6ce67f2efe82f01c40_0_form1.png",(文件名称!!)
}
],
"annotations": [
{
"id": 20703,
"image_id": 918,
"category_id": 2,
"area": 14640,
"bbox": [(线切出来的格子坐标)
x1,
y1,
w,
h
],
"bbox_utf8_string": [(线切出来的格子里面包含的文本框格子坐标,bx1>x1;by1>y1;bx1+bw<x1+w;by1+bh<y1+h)
bx1,
by1,
bw,
bh
],
"utf8_string":"ocr标注结果,如果是化学分子式都标注为\ocr",
"loc":[index_x1,index_y1,index_x2,index_y2](线切出来的格子,是由哪个线切出来,线的序号从0开始)
},
{
"id": 20704,
"image_id": 918,
"category_id": 2,
"area": 13224,
"bbox": [
431,
55,
456,
29
],
"bbox_utf8_string": [
461,
60,
406,
20
],
"utf8_string":"compound",
"loc":[0,0,1,1],
},
{
"id": 20705,
"image_id": 918,
"category_id": 2,
"area": 20792,
"bbox": [
4,
3,
184,
113
],
"bbox_utf8_string": [
461,
60,
406,
20
],
"utf8_string":"Antiproferative acitivity IC_{50}\pm SEM(\um M)",
"loc":[0,1,1,6],
}],
"categories": [
{
"supercategory": "block",
"id": 1,
"name": "block"
}]
}