一、整体要求
标注回答几个问题
- 表格检测:页面中是否有表格
- 表格分类:是什么类型的表格,分子性质表/Markush表/其它表
- 表格整体粗粒度结构:
- 常规表格:标注 标题 + 表体 + 脚注 区域
- Markush表格:标注 母核 + 标题 + 表体 + 脚注 区域
1、所有pdf图片表格元素都需要被框准确和划分到正确的类型,不能出现漏标注或类型标注错误的情况
2、最终交付的标注成果数据为 JSON 格式文件。
典型示例
二、 文档元素分类(标注对象)
| 元素 | 定义 | 备注 |
|---|---|---|
| Text | 作者,作者单位; 纸质资料; 版权信息;简介; 正文、脚注和附录中的段落; | x |
| Text_caption | 插图或者表格 标题 | 属于text的子类,是更细分的分类 |
| Text_footnote | 插图或者表格 注解 | 属于text的子类,是更细分的分类 |
| Title | 文章标题 | x |
| List | 列表 | x |
| Table | 表格 | x |
| Table_OCSR | 表格上的分子图 | 属于Figure的子类,是更细分的分类。逻辑上是属于表格的分子图 |
| Figure | 插图 | x |
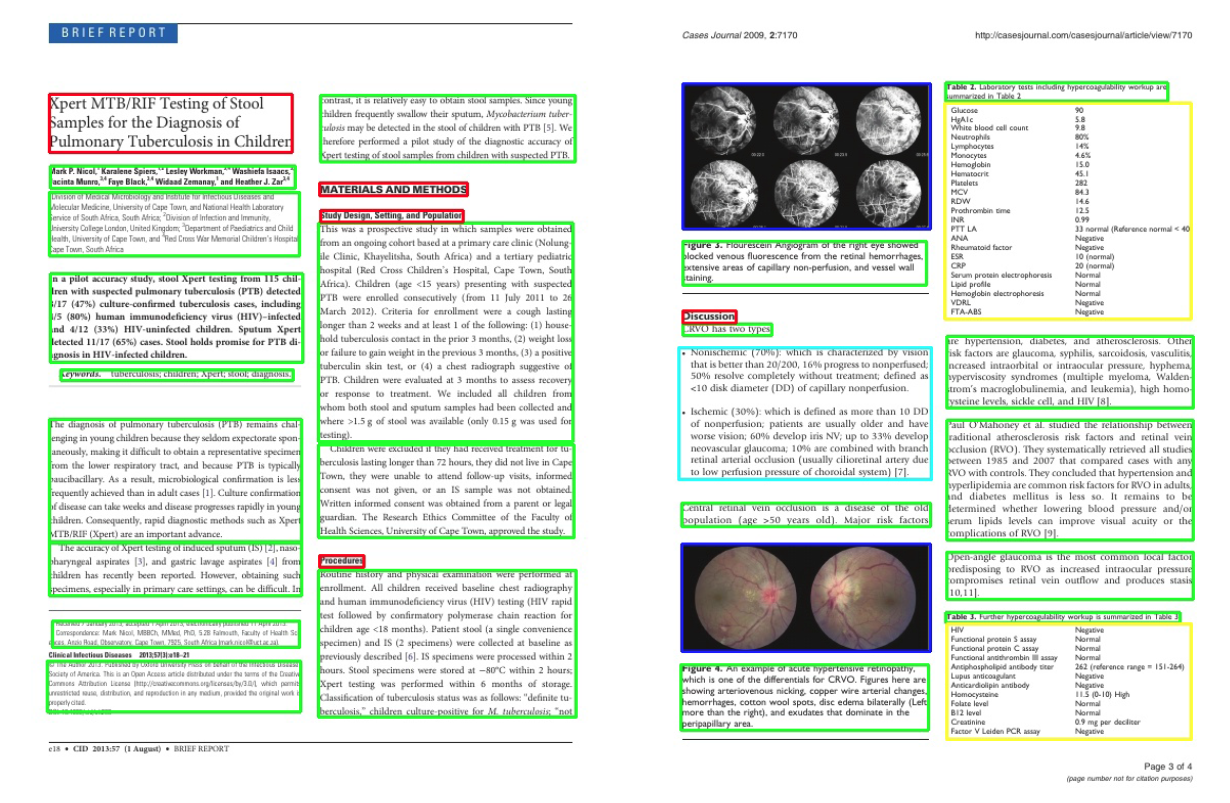
具体标注样例展示如下图:


二、标注数据前统计
-
pdf数量
-
Plain pages,页数数量,每pdf页数平均数,每pdf有表的页数平均数
-
每pdf表格平均数
-
每有表页的表格数平均数
-
pages with Title
-
Pages with lists
-
Pages with tables
-
Pages with figures
三、标注原则:
(1)贴边规则:标注框需紧贴目标的边缘进行画框标注,不可框小或框大。要求边框尽量贴合,像素偏差小于5px,特别注意边框的高度。
(2)重叠规则:当两个目标物体有重叠的时候,比如图嵌入在大图中,表嵌入在大表中,则只框住大表,大图。也就是就框最大的框。
(3)独立规则: 每一个目标均需要单独拉框,不能出现图上有颜色的部分没有被框住
(4)边界检查: 确保框坐标不在图像边界上,防止载入数据或者数据扩展过程中存在越界报错。
(5)小目标规则:不同算法对小目标的检测效果不同,对于小目标只要人眼能分清,都应该标出来。
(6) 框唯一标签规则:每个框只有一个正确标签
小目标规则,独立规则,在当只重点标注一个类(表格时)可以不用遵守
四、常见标注错误(持续补充):
| 错误类型 | 违反规则 | 错误分析 | 样例 |
|---|---|---|---|
| Correct | x | x | x |
| Partial | 重叠规则 | 表注框包含在表框内 | 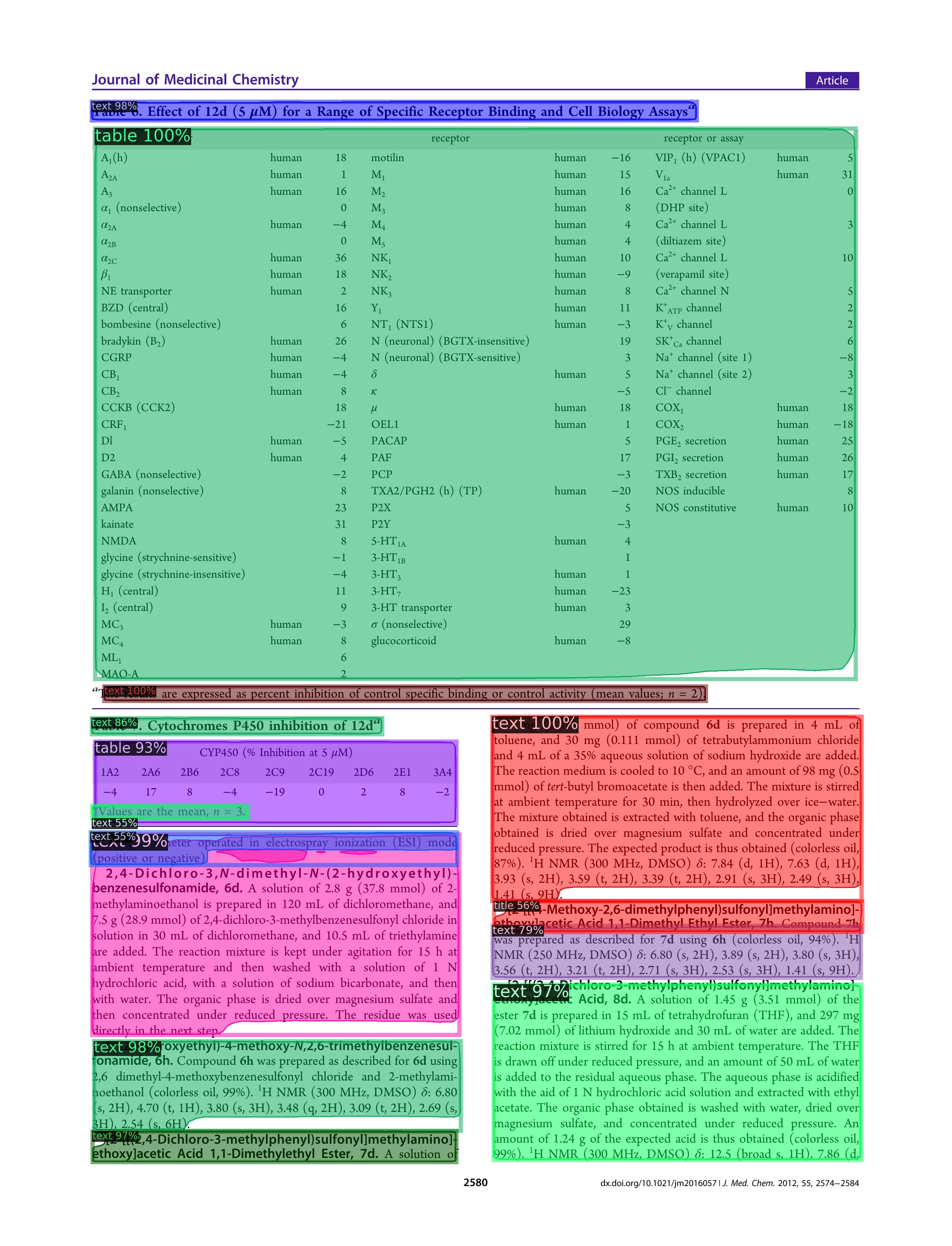 |
| x | x | 表和插图框混合在一起 | 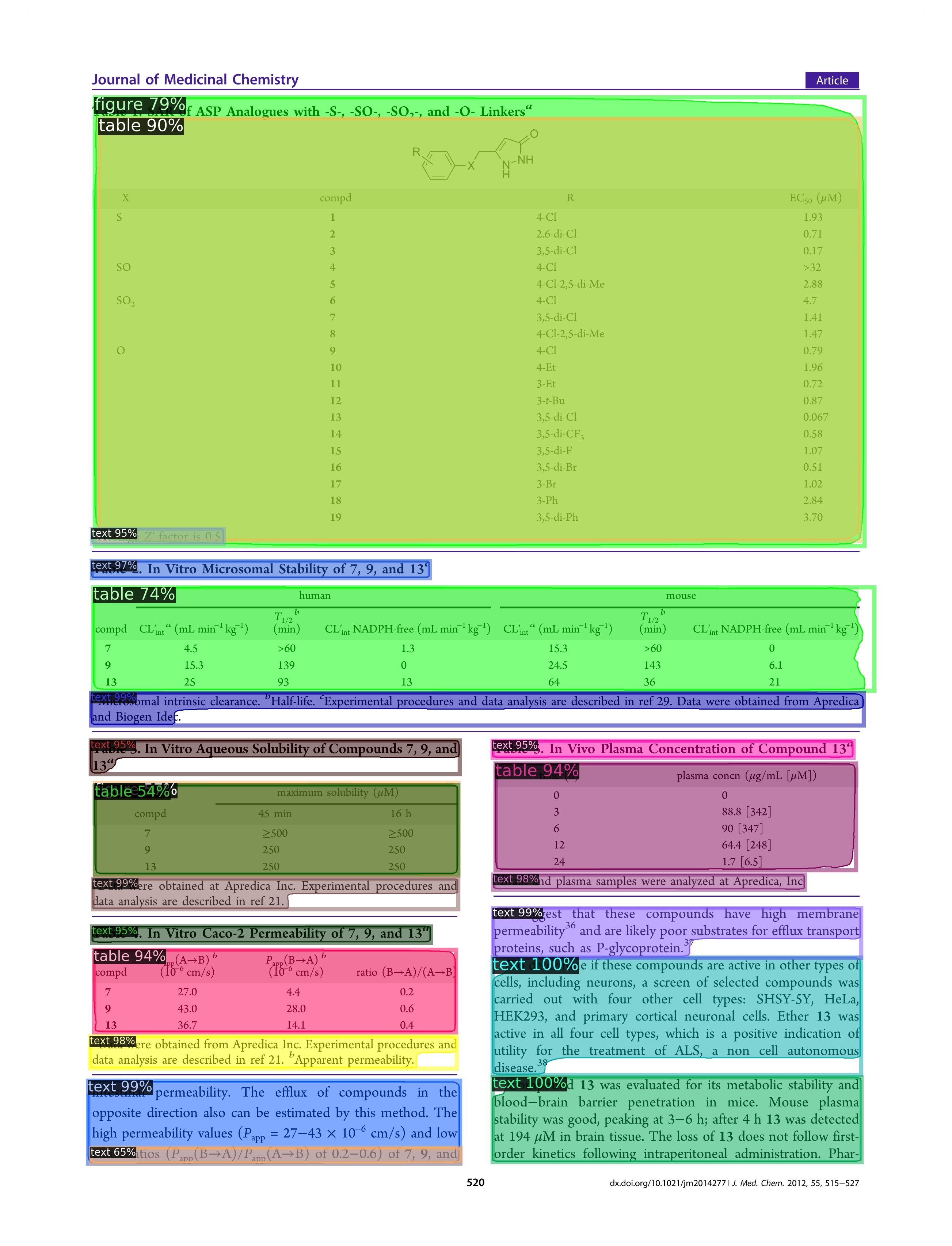 |
| Over-Segmented | 贴边规则 | 表格top多框住其他内容 |  |
| label incorrect | 框唯一标签规则,贴边规则 | 表格类型打标错误,及表格左边区域预测少了 |  |
| Under-Segmented | 贴边规则 | 表格2的左边界少框住范围 | 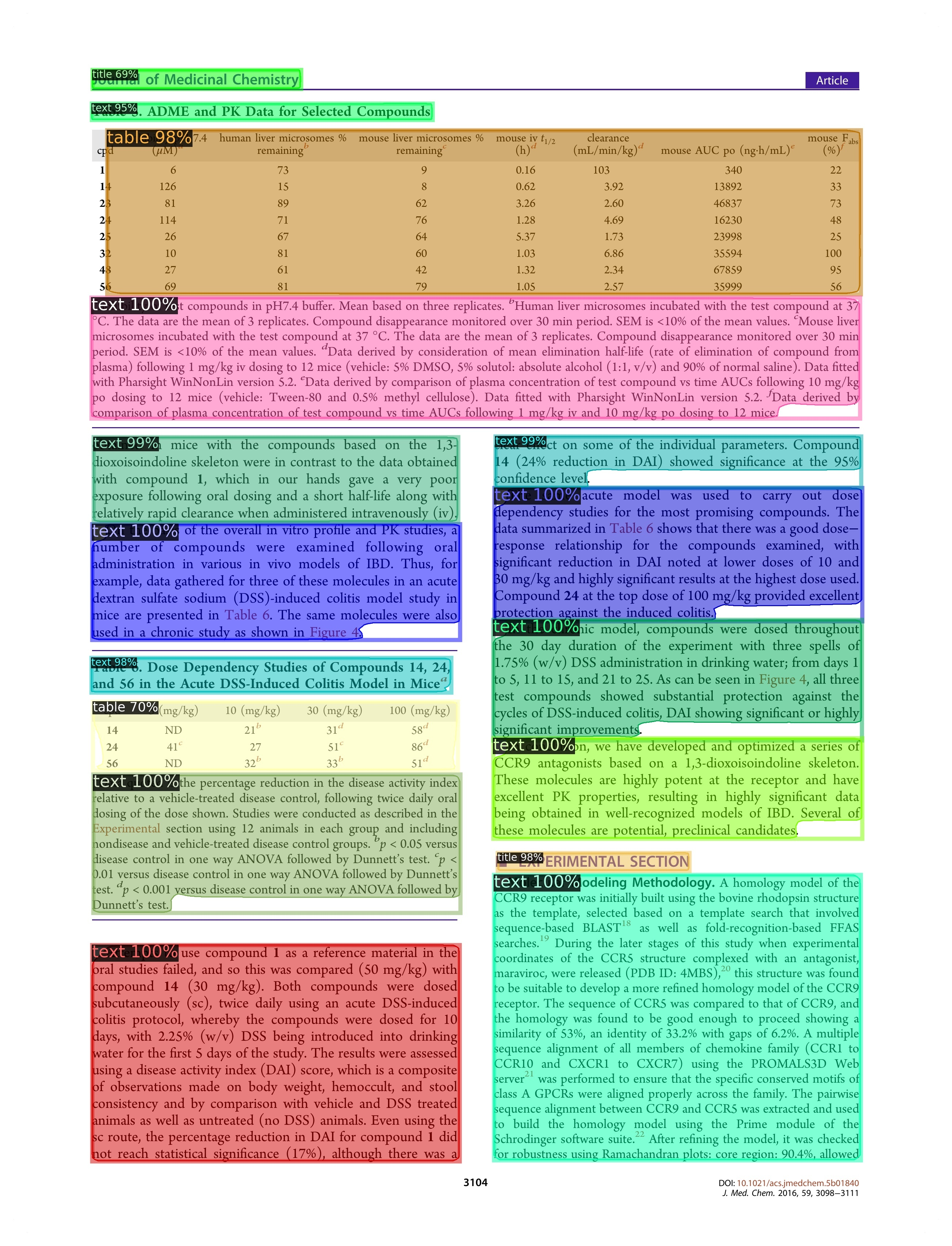 |
| False Positive | x | 漏标 | x |
五、标注检查规范:
(1)标注正确率:检查被标注的目标(框)的标签类别是否正确。 (2)标注精确度:检查标注框是否完整贴合目标,是否存在标注框过大或者过小情况。 (3)标注完备性:检查重叠或者部分被遮挡的目标是否存在漏标,或者重复标注情况。
六、标注质量指标(交付数据的质控标准)
1、错标数:框标签类型错误、属性(页数,文件名)错误、精度不符合要求的标注成果数量。
精度不符合要求
标注的框之间重叠
标注的框,框住冗余白色区域不超过真实框面积的5%,绝对不能框住不属于表格的区域
2、漏标数:符合标注规范要求,但被遗漏的标注元素数量。
3、多标数:
①不符合标注规范要求或真实图片不存在的要求,但被标注的元素数量;
②单一标注元素被多次重复标注的数量。
4、已验收总数:验收交付成果元素总数量。
5、正确率计算公式如下: 正确率=(已验收总数-多标数-错标数)/(已验收总数+漏标数)。
七、数据标注流程
-
数据采集,算法提供预标注的pdf图片,pdf图片来自数据团队提供的医药pdf文件
-
数据预处理,去掉没有表格和插图的pdf图片,每页pdf图片会经过掩盖ocsr分子处理
-
数据管理,元数据信息字段(参考下图数据视角和数据采集采样构造)
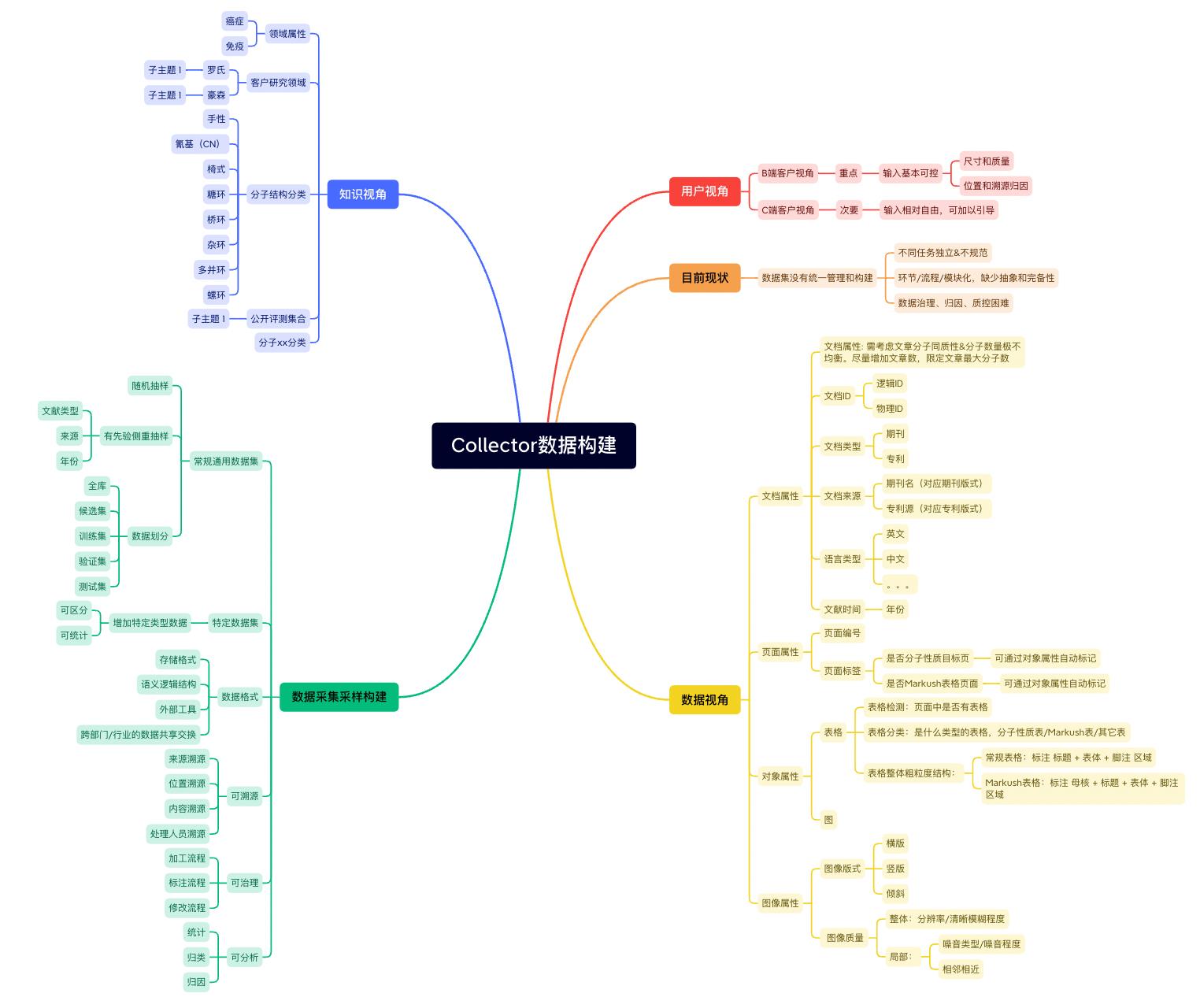
4.模型预标注,在通过模型预标注之后,需要检查预标注结果以此来挖掘试标注的不足之处,随后根据不足之处进行补充标注。
6.错误标注反馈机制(待补充)
八、标注数据范围和计划
本次标注范围
| 元素 | 是否算法预标注 | 是否需要标注和基于预标注修正 |
|---|---|---|
| Text | 是 | 否 |
| Text_caption | 否 | 是,会出现标注为Text,需要基于预标注修正 |
| Text_footnote | 否 | 是,会出现标注为Text,需要基于预标注修正 |
| Table | 是 | 是 |
| Table_OCSR | 是 | 是 |
| Title | 是 | 否 |
| List | 是 | 否 |
| Figure | 是 | 否 |
5.交付标注文件夹格式和文件格式
文件夹格式
数据集1 pdfs
|-- images
| |-- pdf文件名_物理页码.jpg
| |-- PMC6589332_12.jpg
| |-- XXX.jpg
|-- voc_labels
| |-- pdf文件名_物理页码.xml
| |-- PMC6589332_12.xml
| |-- XXX.xml
|-- coco.json
XXX.xml文件 voc数据格式
<?xml version="1.0" ?>
<annotation>
<folder/>
<filename>PMC6589332_11.jpg</filename>
<size>
<width>773</width>
<height>1000</height>
<depth>3</depth>
</size>
<object>
<supercategory>table<supercategory>
<name>table</name>
<bndbox>
<xmin>243.93609898386438</xmin>
<ymin>133.85618575895674</ymin>
<xmax>721.0680585873672</xmax>
<ymax>351.1486631451231</ymax>
</bndbox>
</object>
</annotation>
没有标注的文件那就是没有xml
coco.json 文件 coco数据格式
{
"images": [
{
"id": 0,
"width": 1984,
"height": 2806,
"file_name": "0064177888b53c6667f6ce67f2efe82f01c40_0.png",(文件名称!!)
}
],
"annotations": [
{
"id": 0,
"image_id": 50,
"category_id": 1
"area": 100802.70731920577,
"bbox": [
x,
y,
w,
h
],
"iscrowd": 0
}],
"categories": [
{
"supercategory": "Table_title",
"id": 1,
"name": "Table1_title"
}]
}