0501
目标检测数据集
数量集图像和目标数量的基本信息,分为4大类,20小类
为什么得到的新坐标减1?VOC的矩形标注坐标是以1为基准的(1-based),而我们在处理图像坐标都是0起始的(0-based)。
 a. Lexical Analysis:
With lexical analysis, we divide a whole chunk of text into paragraphs, sentences, and words. It involves identifying and analyzing words’ structure.
a. Lexical Analysis:
With lexical analysis, we divide a whole chunk of text into paragraphs, sentences, and words. It involves identifying and analyzing words’ structure.
b. Syntactic Analysis: Syntactic analysis involves the analysis of words in a sentence for grammar and arranging words in a manner that shows the relationship among the words. For instance, the sentence “The shop goes to the house” does not pass.
c. Semantic Analysis: Semantic analysis draws the exact meaning for the words, and it analyzes the text meaningfulness. Sentences such as “hot ice-cream” do not pass.
d. Disclosure Integration: Disclosure integration takes into account the context of the text. It considers the meaning of the sentence before it ends. For example: “He works at Google.” In this sentence, “he” must be referenced in the sentence before it.
e. Pragmatic Analysis: Pragmatic analysis deals with overall communication and interpretation of language. It deals with deriving meaningful use of language in various situations.




0513

5014
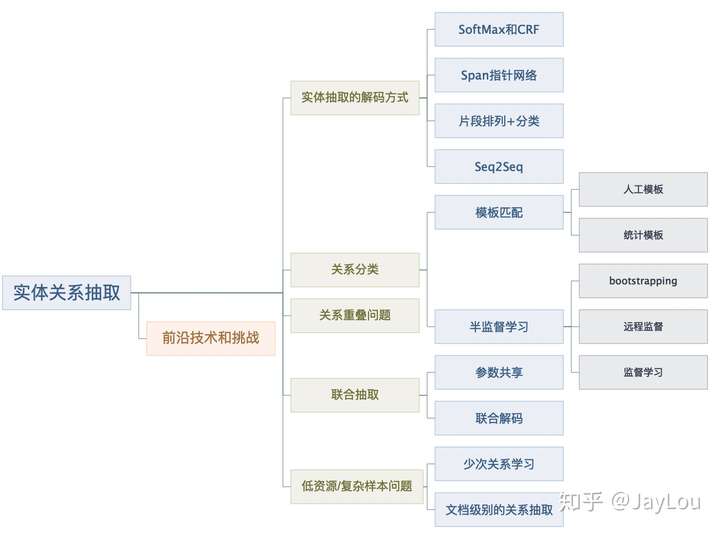
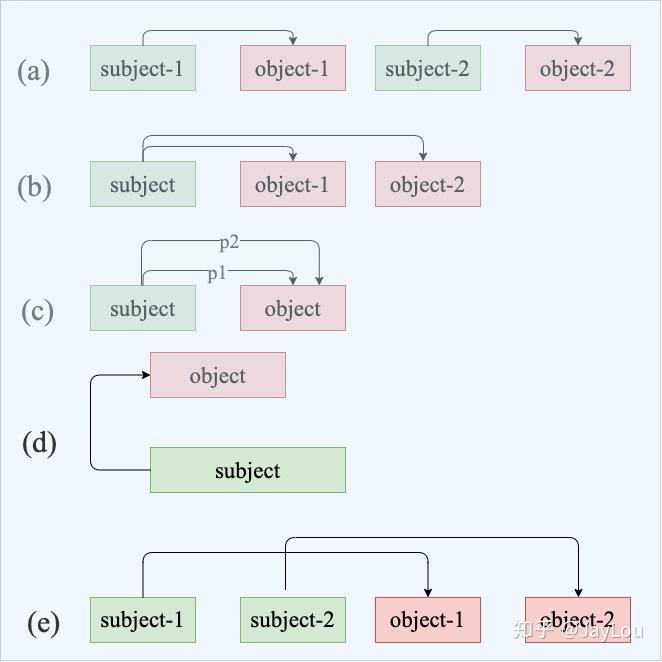
什么是关系重叠&复杂关系问题?
0519


0524
0525
table recognition structure loss comparison
- Pairing Loss for CyclePairing Module

-
focal loss
-
LGPMA

L2

TableFormer

0526
0530
5月居家日报
| 日期 | 目标 | 进展 | 其他事项 |
|---|---|---|---|
| 5.23 | 1. 数据清理:sparse数据集150k数据。2.训练评估阶段:自研算法基于开源数据extractable训练. 3.训练评估阶段:重构数据预测后处理代码,达到每次训练完开源数据就能将自有数据预测出来做badcase分析 | 1. 清理调试中解决一些bug. 2.跟自有数据指标趋势一样(https://wandb.ai/franztao/table_master_lmdb_ResnetExtract_Ranger_0322/runs/3p6fnb3k?workspace=user-franztao) 3.完成20% | 面试实习生 |
| 5.24 | 1.训练评估阶段:自研算法基于开源数据1w数据训练,2.训练评估阶段:重构数据预测后处理代码,达到每次训练完开源数据就能将自有数据预测出来做badcase分析 | 1.数据处理完,当前训练中. 3.完成90% (KnowledgeGraphCommon\models\cv\recognition\table\tgr_tablemaster\mmocr\datasets\ocr_dataset.py) | 飞书培训,ocr表格上线会议, 定位分析线上表格提取问题 |
| 5.25 | 1.训练评估阶段:自研算法基于开源数据1w数据训练,2.训练评估阶段:重构数据预测后处理代码,达到每次训练完开源数据就能将自有数据预测出来做badcase分析.3. 150k 开源数据预处理中(在跑,已过1天)4. 算法设计阶段:TSR算法loss调研和分析 | 1.1w数据训练,复现实验效果. 2.完成95% ,研究如何预测出图片存入wandb,便于界面形式分析badcase,4.修改开源方案box loss L1成其他类型再进行实验 | 飞书培训,面试实习生 |
| 5.26 | 1.训练评估阶段:重构数据预测后处理代码,达到每次训练完开源数据就能将自有数据预测出来做badcase分析 2.调研”检索图片文件系统” | 2.检索图片系统,https://github.com/ProvenanceLabs/image-match | 早会,表格识别需求评审 |
| 5.27 | 1.产品体验 2.下版本开发设计 | 1.体验产品,分析badcase,2.进行下版本开发,代码中 | 早上请假 |
| 5.30 | 1.产品体验 | 1.产品体验,跟开发确定若干问题,接口修改开发中 | |
| 5.31 | 1.一键识别端到端时间预估 2. 自研表格 | 1.一键识别端到端时间预估,代码完成 2.分析loss下降但是指标未上升的原因 | 实习生面试 |
| 6.1 | 1.一键识别端到端时间预估 2.自研表格 | 1.补充mask部分 2. 分析loss下降但是指标未上升的原因 | |
| 6.2 | 请假一天 | ||
| 6.6 | 1.接口变更 2. 自研表格 | 实习生面试。接口定位 | |
| 6.7 | 1.tsr 性能测试2. 自研表格 | 沟通交流培训 | |
| 6.8 | 1.自研tsr与extractable在开源数据上的效果评估。2.实习生工作交接 | makush定位两个接口定位,实习生代码 | 实习生面试 |
| 6.9 | 1. 自研表格 | 定位和处理makush项目定位问题。分析开源数据extractable与selfstudy的badcase | 周会。实习生面试 |
| 6.10 | 1. 自研表格 | ||