简介背景
历史由来
从古老石块上,人类记录信息的形式就有表格的呈现形式
 到现在为止Spreadsheets工具来电子化处理表格
到现在为止Spreadsheets工具来电子化处理表格
价值
表格是各类文档中常见的页面元素,随着各类文档的爆炸性增长,如何高效地从文档中找到表格并获取内容与结构信息即表格识别,成为了一个亟需解决的问题。对表格结构的还原和内容的识别,能帮助计算机更好的理解表格,在教学内容生产、智能解答等场景下,具有非常重要的应用价值。随着深度学习技术的飞速发展,目标检测、OCR和文档结构识别等技术也取得了许多新的进展,为表格识别提供了多种可能的解决方案。
学术上的价值
CV目标检测上的细分领域,当前还不太卷。表格中的文本解析,让这个任务又是极好的多模态任务。
工业上的价值
在提高生产效率、调整产业结构、提高产品服务质量、降低人工运营成本等战略目标的驱动下,我国各行各业都在从传统模式向数字化、网络化、智能化转变。
定义
表格结构识别是表格区域检测之后的任务,其目标是识别出表格的布局结构、层次结构等,将表格视觉信息转换成可重建表格的结构描述信息。这些表格结构描述信息包括:单元格的具体位置、单元格之间的关系、单元格的行列位置等。在当前的研究中,表格结构信息主要包括以下两类描述形式:1)单元格的列表(包含每个单元格的位置、单元格的行列信息、单元格的内容);2)HTML代码或Latex代码(包含单元格的位置信息,有些也会包含单元格的内容)。
表格数据呈现形式的本质
一句话概括就是:Meaning in Tables Meaning = Language + Layout

表格数据中呈现的语义逻辑
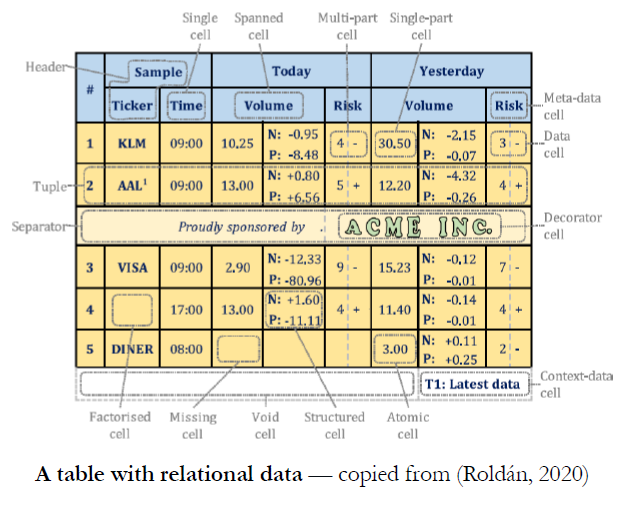
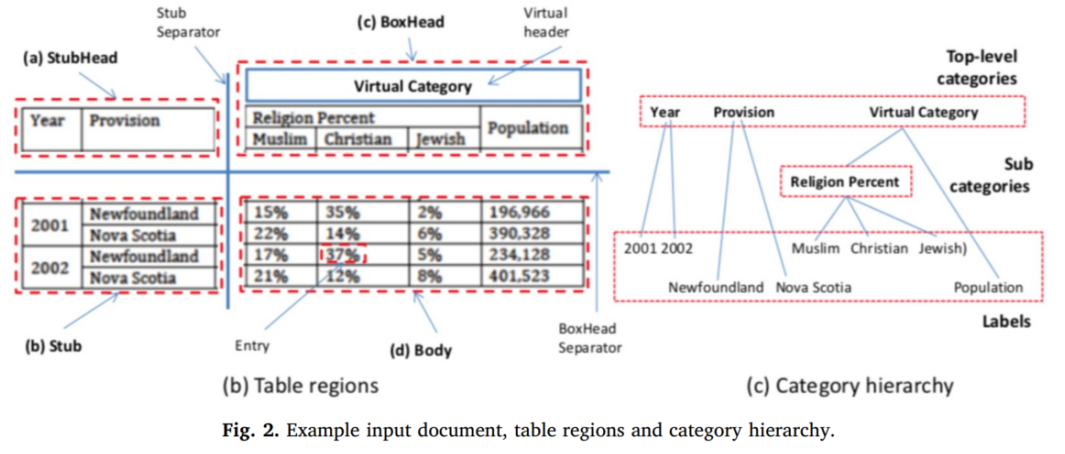
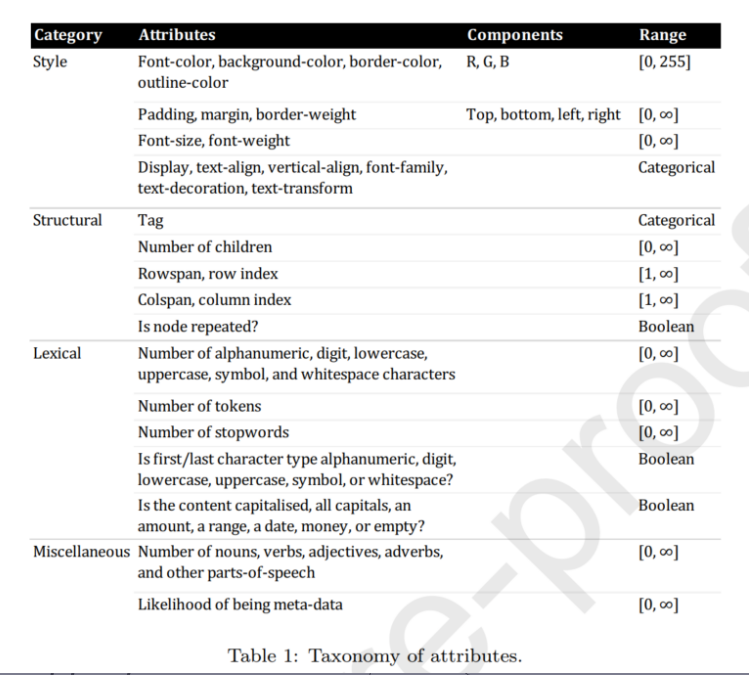
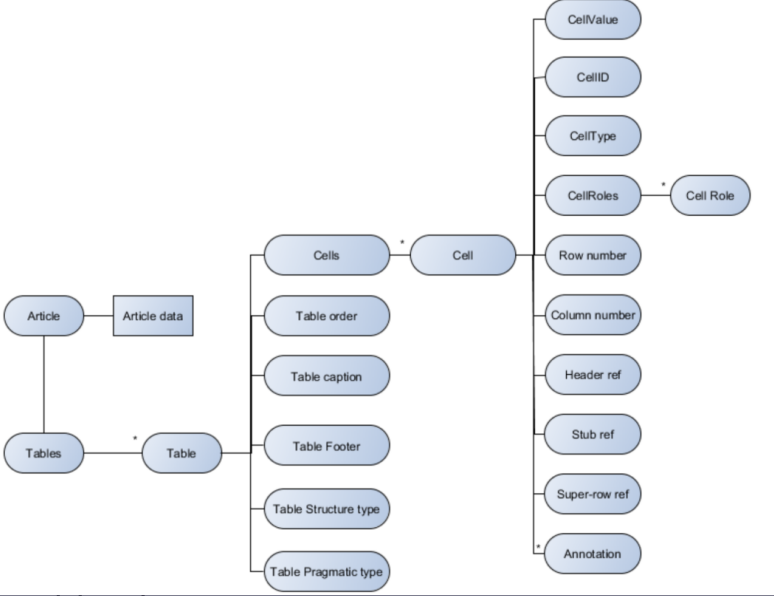
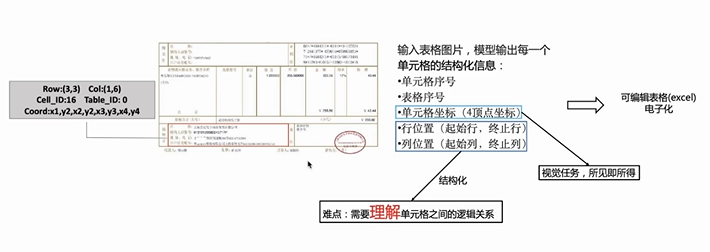
表格数据存储格式
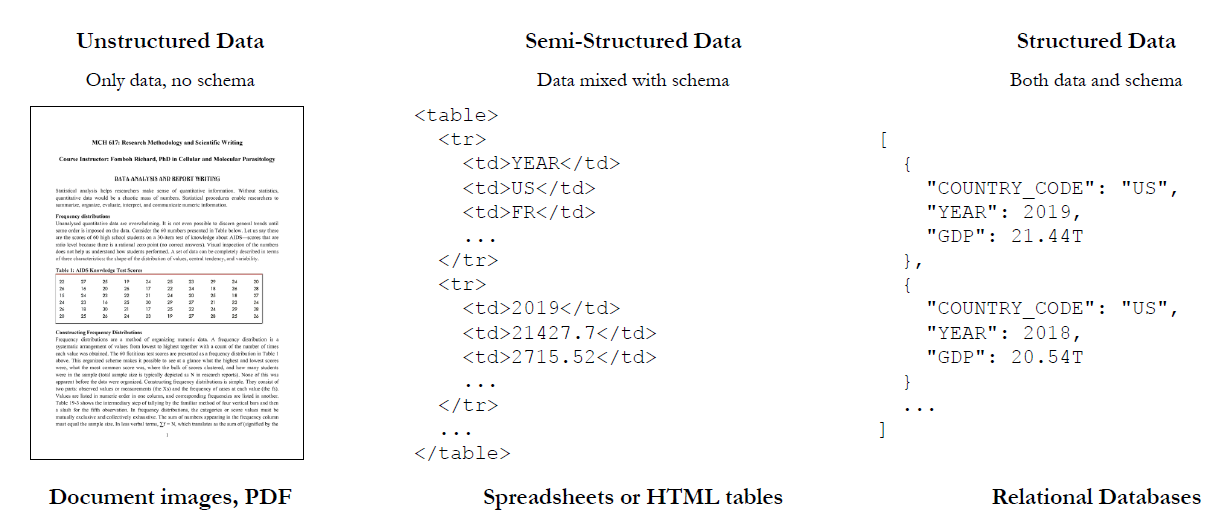



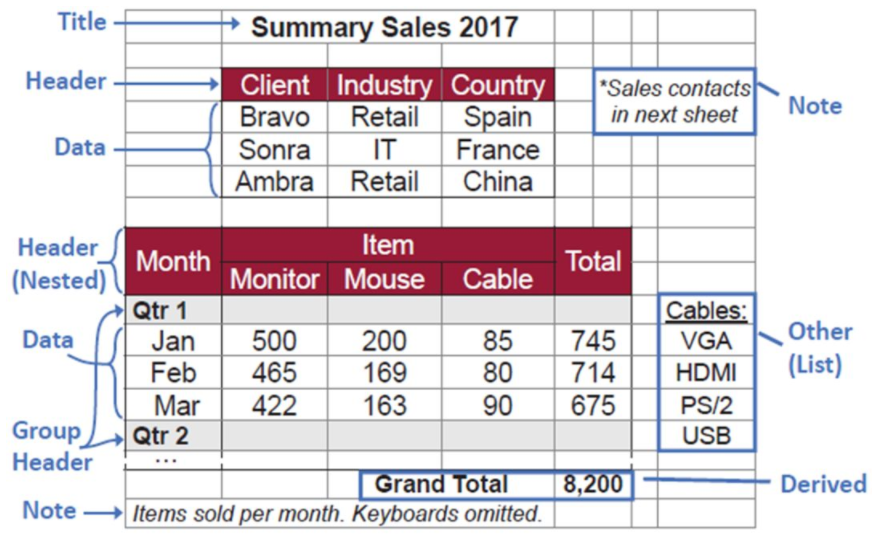
表格分类
存储格式
pdf
图片
展现形式
垂直
水平
旋转X度
记录方式
电子记录
手写
扫描
表格内容
单表
多表
格子形式
Lattice : For tables formed with lines.
border
Stream : For tables formed with whitespaces.
borderless
逻辑结构
同一列里展示两列数据
两列上面有共同的主列
图片质量
整体:分辨率/清晰度
局部:噪音程度/类型
文档类型
文档来源
研究领域
Document AI任务描述及相关子任务
表格结构识别是属于document AI任务的子任务,从整体document AI任务看表格结构识别在技术链上的定位
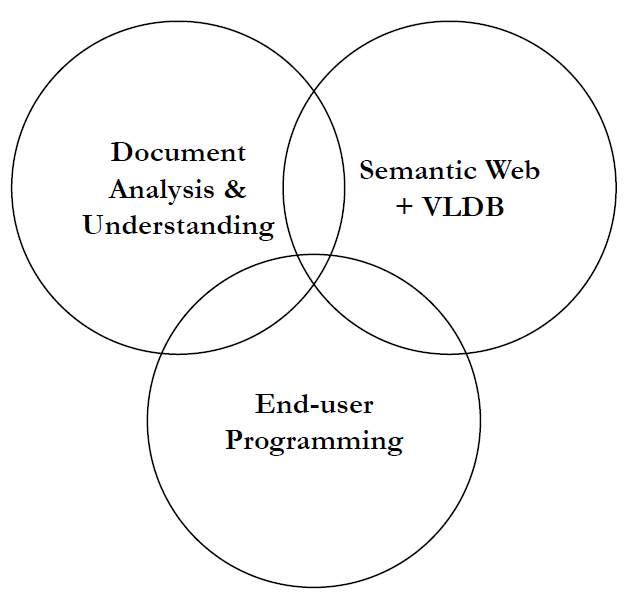
1. Document analysis and understanding
其中5个子问题如下
Table detection
Structure Recognition
Functional Analysis
Structural Analysis
Interpretation
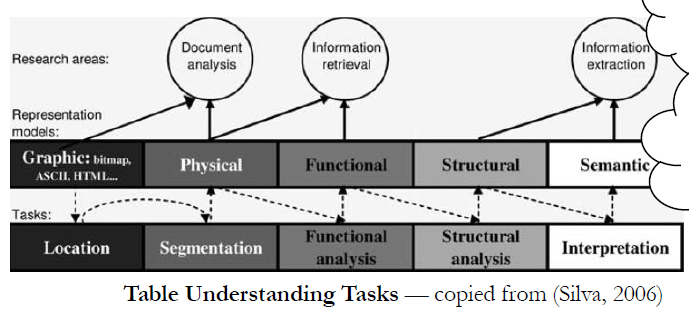
2. semantic web + Volume large database
其中3个子问题如下
Entity Linking
Column Type Identification
Relation Extraction
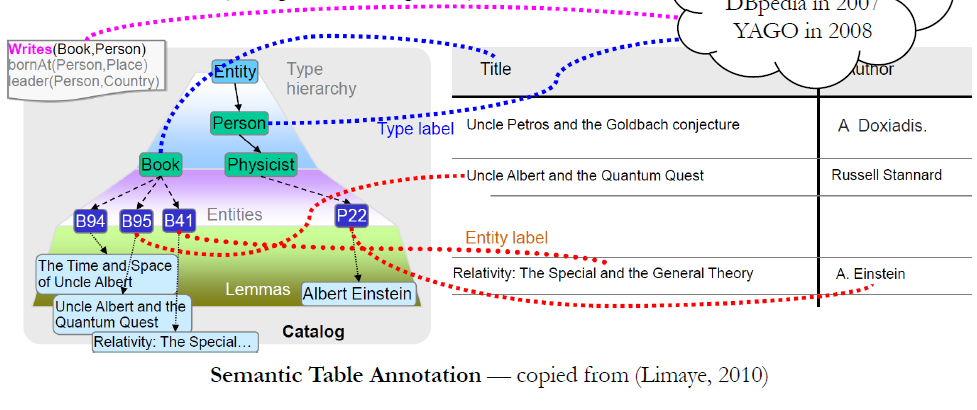
3. semantic table interpretation
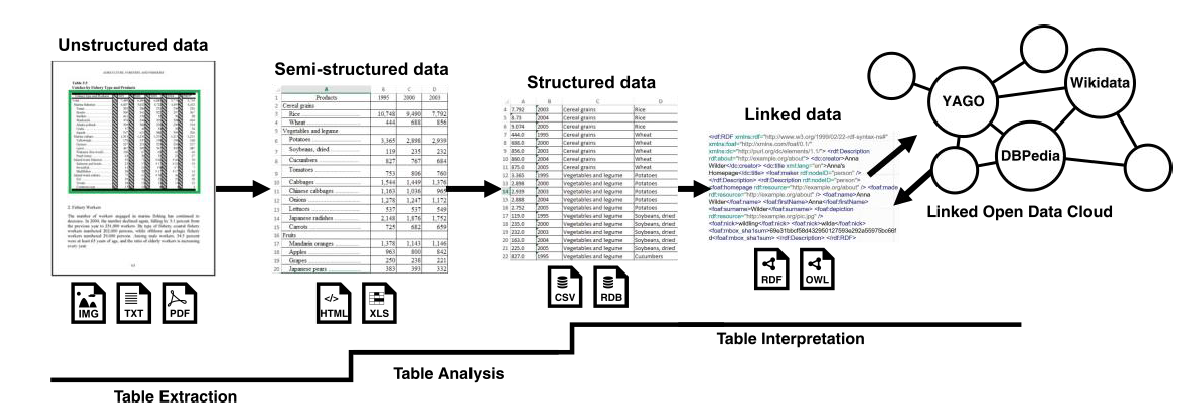
评估指标 metric
1.格子bbox metric
-
P R Recall
-
map@IOU coco标准
-
GriTS
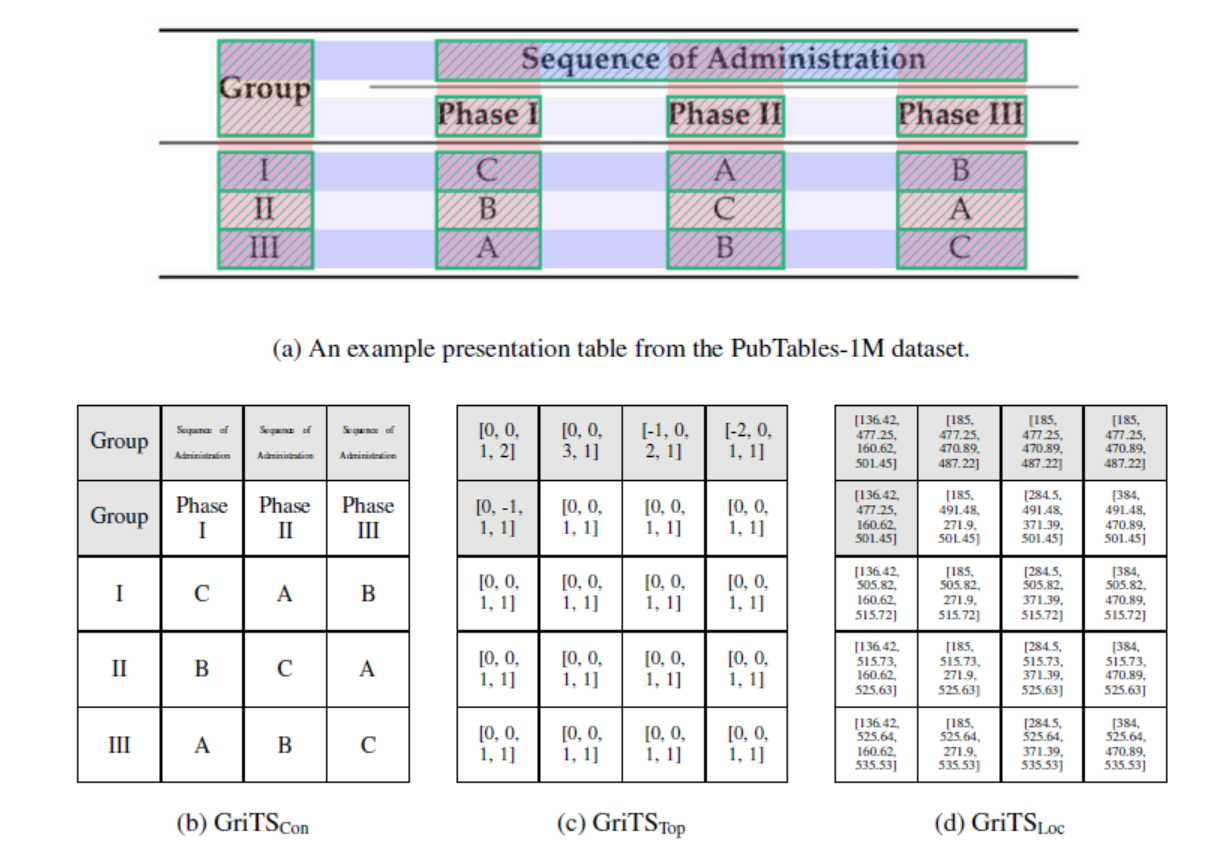
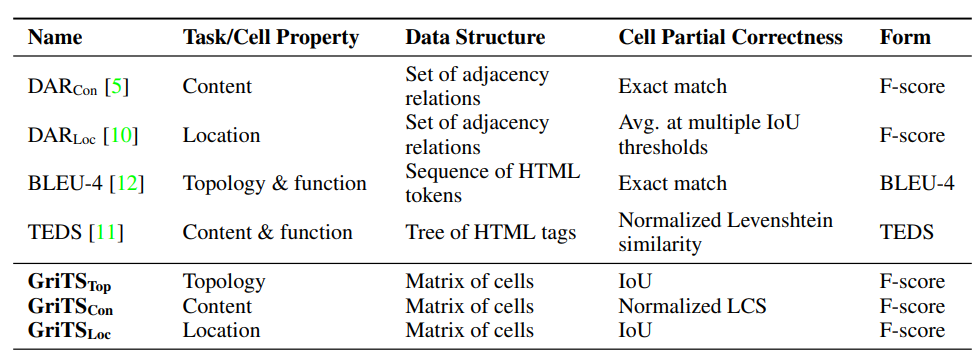
(“grits”) computes the grid table similarity (GriTS) metrics for table structure recognition. GriTS is a measure of table cell correctness and is defined as the average correctness of each cell averaged over all tables. GriTS can measure the correctness of predicted cells based on: 1. cell topology alone, 2. cell topology and the reported bounding box location of each cell, or 3. cell topology and the reported text content of each cell. For more details on GriTS
- STIOU
-
TEDS

2.格子中文本的评估指标
-
普通文本
- one 全对准确率: 每张图片版面上有多个文本时候,每个文本都对的张数占总的张数的比例; 标签全对准确率:每张图片版面上有多个文本时候,文本对的个数占总的文本个数的比例;
- 平均编辑距离:平均编辑距离越小说明识别率越高。平均编辑距离主要衡量整行或整篇文章的指标,可以同时反应识别错,漏识别和多识别的情况;
- 字符识别准确率,即识别对的字符数占总识别出来字符数的比例,可以反应识别错和多识别的情况,但无法反应漏识别的情况;
- 字符识别召回率,即识别对的字符数占实际字符数的比例,可以反应识别错和漏识别的情况,但是没办法反应多识别的情况,可以配套字符识别准确率一起使用;
- 文本行定位为的准确率和召回率,同字符识别的准确率和召回率。主要反应文本行定位的指标,是ocr算法的重要指标; two 第一种是字符准确率,单字识别率,就是按单字算,一百个字里错5个字,识别率95%。
- 第二种是字段准确率,整行识别率,一个字段算一个整体,假如100个字分为20个字段,里面错了5个字,分布在4个字段里,那么识别率是16/20=80%。
- 第三种是整张准确率。通常在票据证件里面有这种计算方式,假设一张票据上有20字,4个字段,5张票上100个字,20字段,错了5个字,分布在4个字段里,分布在3张票据上。那么识别率只有2/5=40%。而且票据字段越多,容易出错的概率越高,整张识别率这个要求就越严苛。实测过程中也会有一些特别约定,说整张识别里错一两个字可以忽略的,这种再另说。 同样是100字错5个,用字符、字段、整张准确率来测算的结果是完全不同的,所以对比不同OCR算法时候一定要看清描述的是单字识别率、整行识别率还是整张识别率。一样的识别率99%,整张识别率可比单字识别率的含金量要大得多。
-
latex文本
AA: Alpha-Numeric Characters Prediction Accuracy, LTA: LaTeX Token Accuracy, LSA: LaTeX Symbol Accuracy, SA: Non-LaTeX Symbol Prediction Accuracy, EM: Exact Match Accuracy, EM@95%: Exact Match Accuracy @95% similarity.
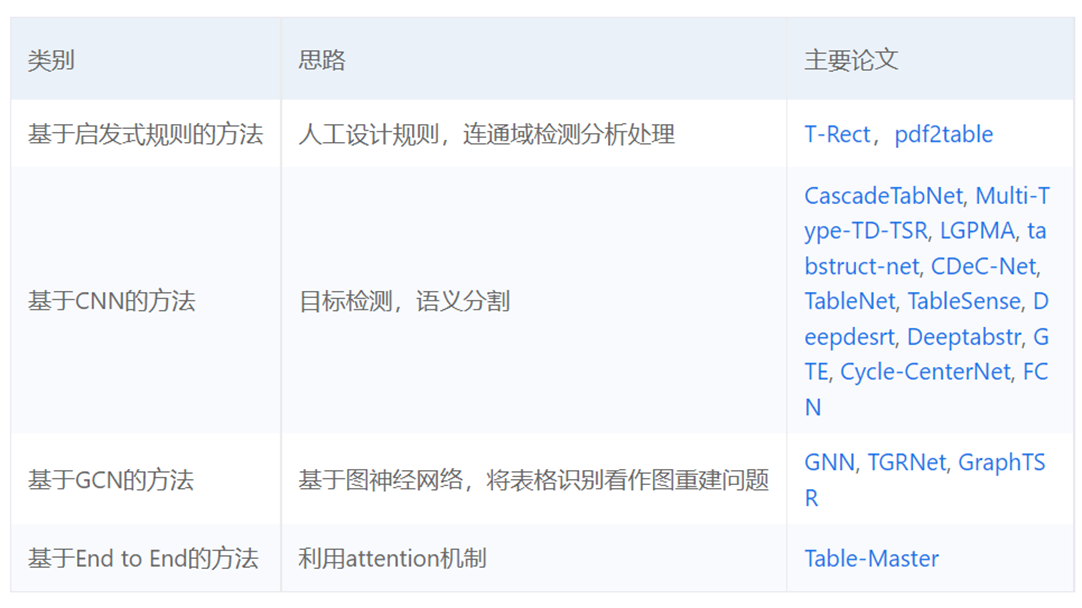
相关技术分类
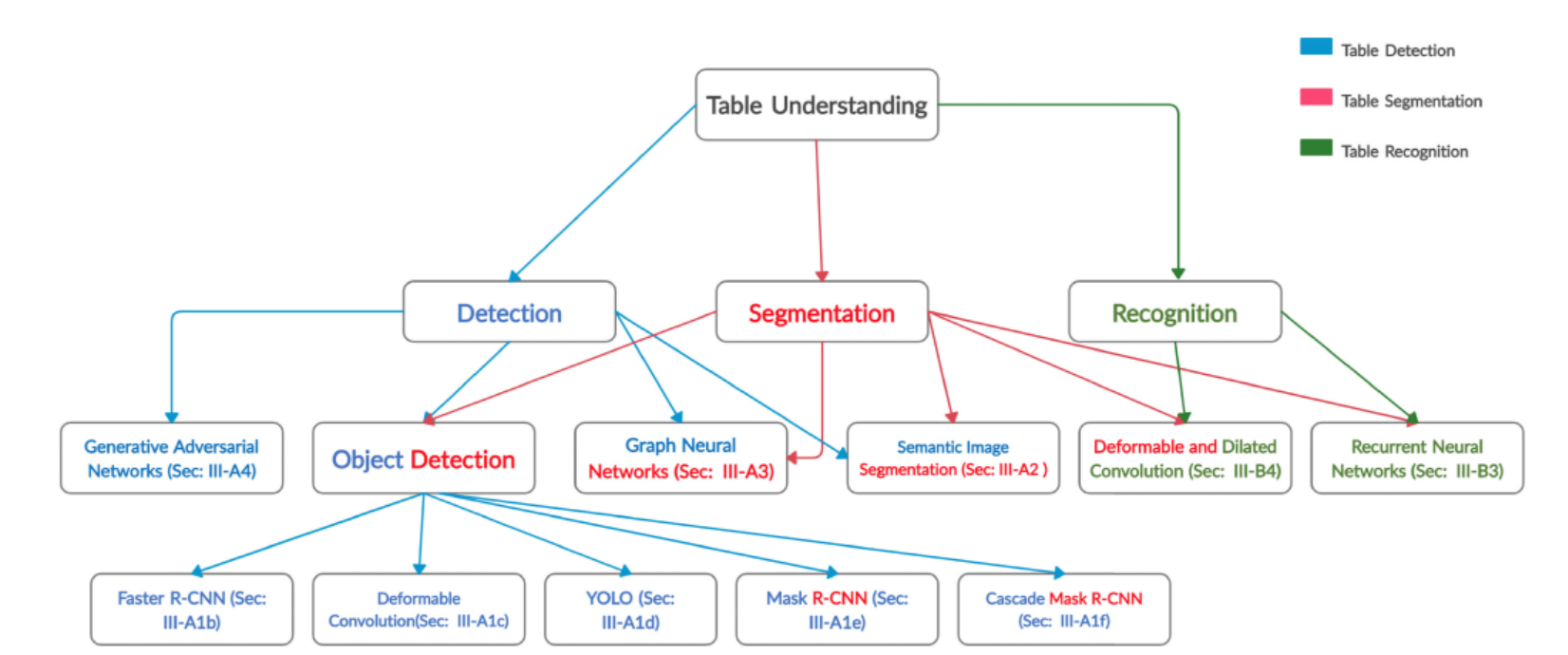
表格识别各技术的进展情况
-
基于启发式规则的方法
-
基于CNN的方法
-
基于GCN的方法
-
基于End to End的方法
 1)利用OCR检测文本,从文本框的空间排布信息推导出有哪些行、有哪些列、哪些单元格需合并,由此生成电子表格;
1)运用图像形态学变换、纹理提取、边缘检测等手段,提取表格线,再由表格线推导行、列、合并单元格的信息;
2,3)神经网络端到端学习,代表工作是TableBank,使用image to text技术,将表格图片转为某种结构化描述语言(比如html定义表格结构的标签)。
缺陷
1)利用OCR检测文本,从文本框的空间排布信息推导出有哪些行、有哪些列、哪些单元格需合并,由此生成电子表格;
1)运用图像形态学变换、纹理提取、边缘检测等手段,提取表格线,再由表格线推导行、列、合并单元格的信息;
2,3)神经网络端到端学习,代表工作是TableBank,使用image to text技术,将表格图片转为某种结构化描述语言(比如html定义表格结构的标签)。
缺陷
思路1)极度依赖OCR检测结果和人工设计的规则,对于不同样式的表格,需做针对性开发,推广性差; 思路2)依赖传统图像处理算法,在鲁棒性方面较欠缺,并且对于没有可见线的表格,传统方法很吃力,很难把所有行/列间隙提取出来; 思路3)解决方案没有次第,一旦出现bad case,无法从中间步骤快速干预修复,只能重新调整模型(还不一定能调好),看似省事,实则不适合工程落地。
基于CNN的方法
Mask R-CNN architecture for table cell structure detection
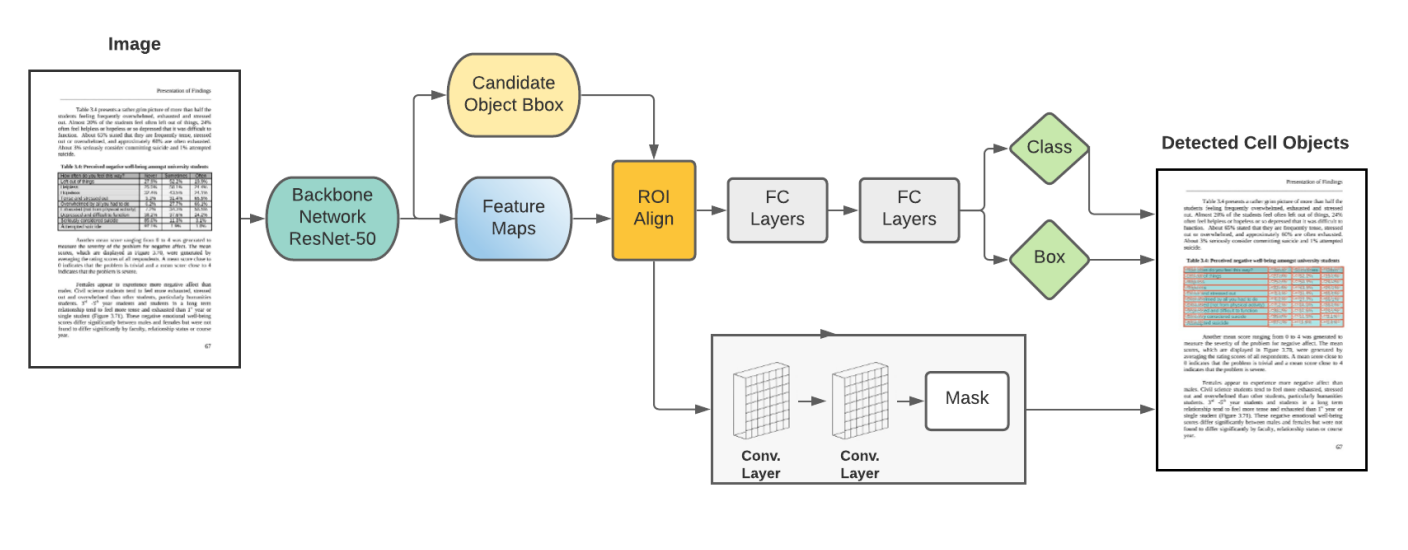
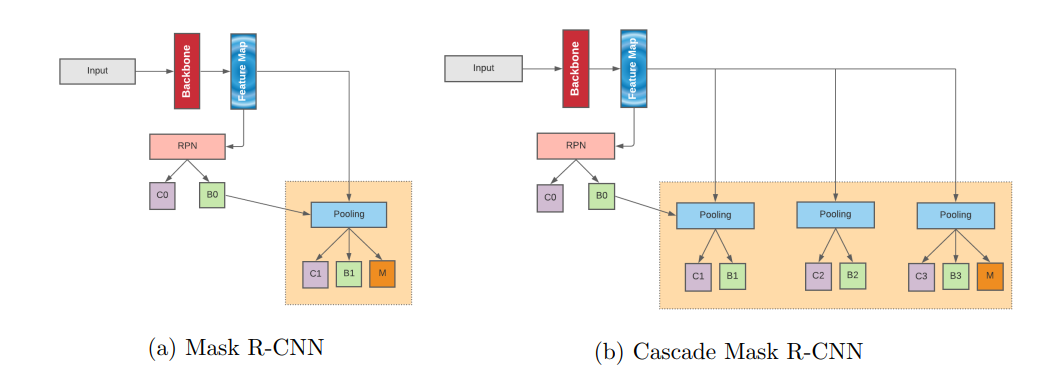
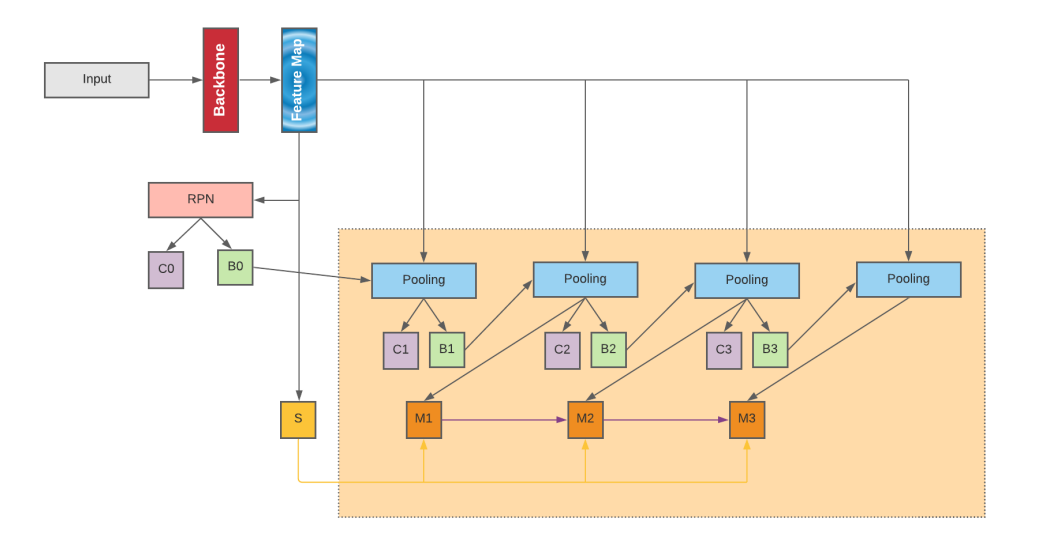
disadvantage: 1)数据漂移性 2) 识别的框会依次影响
基于GCN的方法
基于End to End的方法
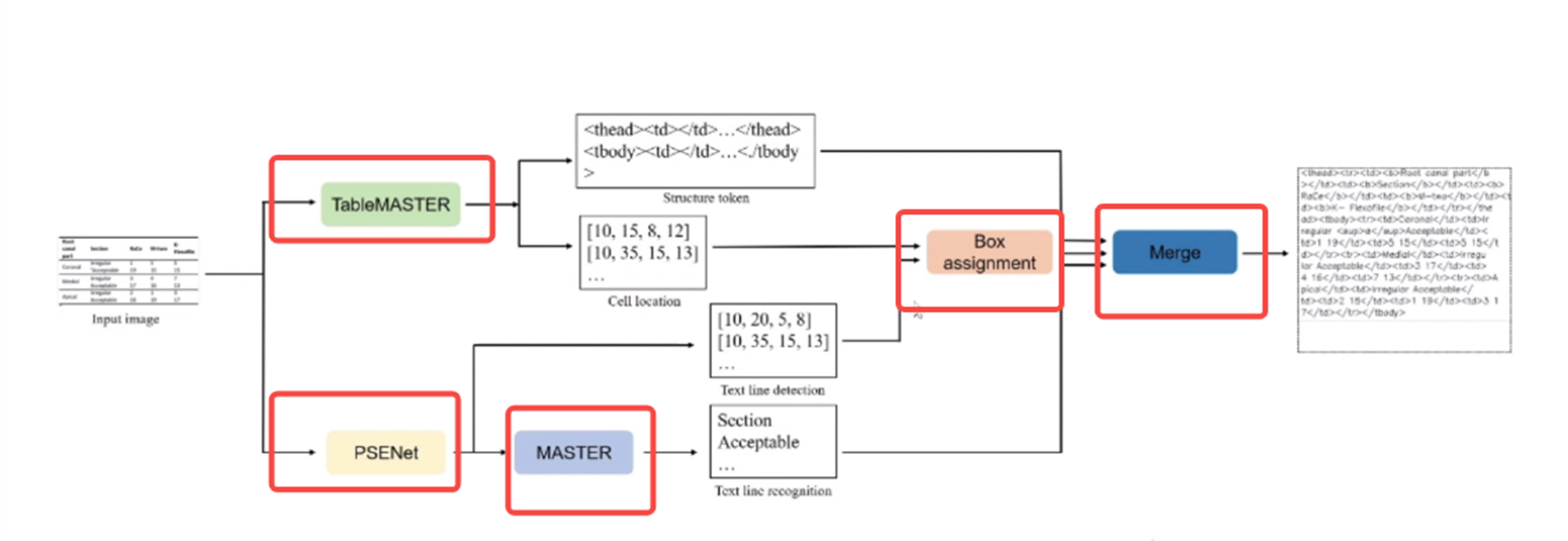
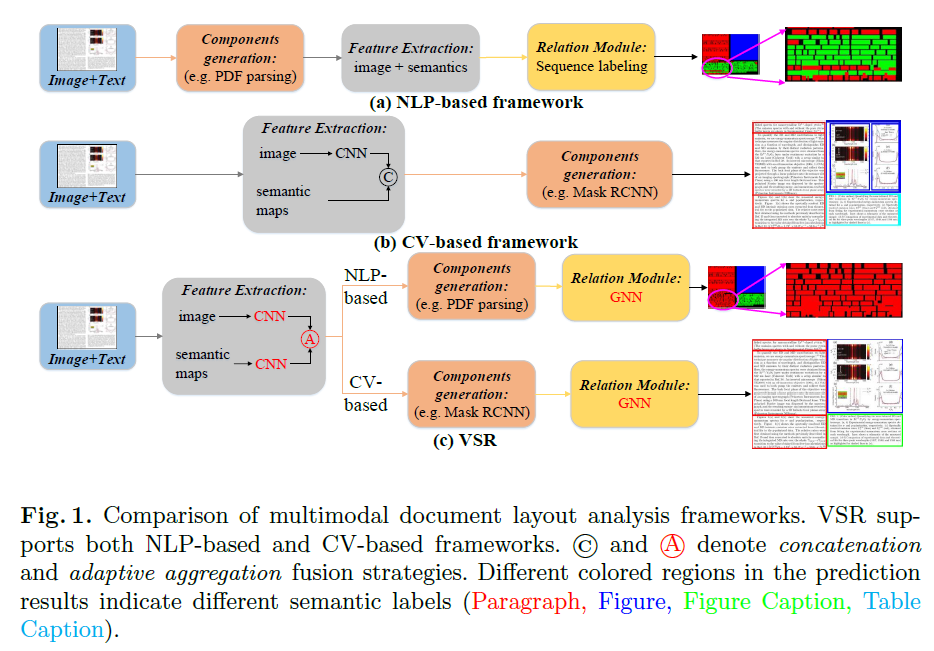
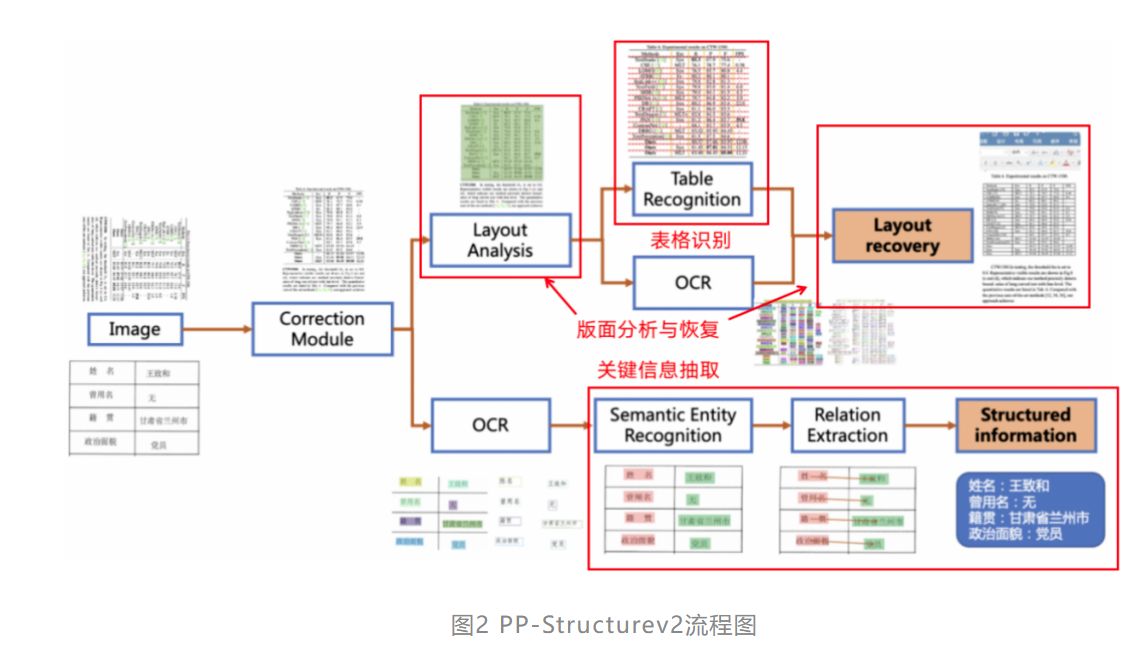
识别效果如下

###
相关损失函数
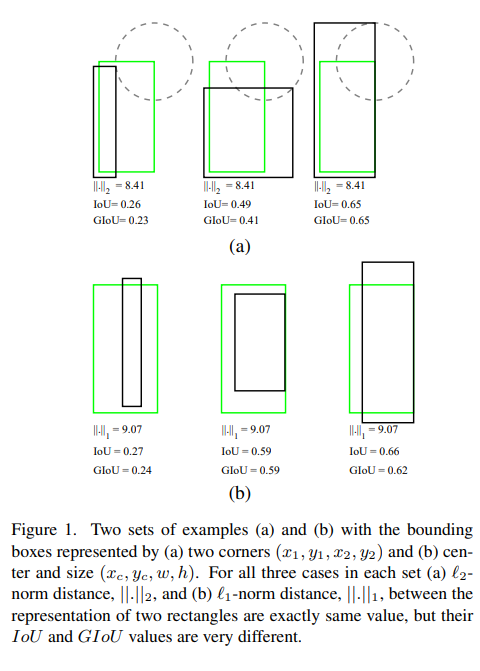
从L1 loss到EIoU loss,目标检测边框回归的损失函数一览
当前TableMaster用L1 loss出现:损失函数会在稳定值附近波动,难以收敛到更高精度。
1. Papers
A curated list of resources dedicated to table recognition ,借鉴(Awesome-Table-Recognition)
- *CODE means official code and CODE means not official code












数据集的汇总
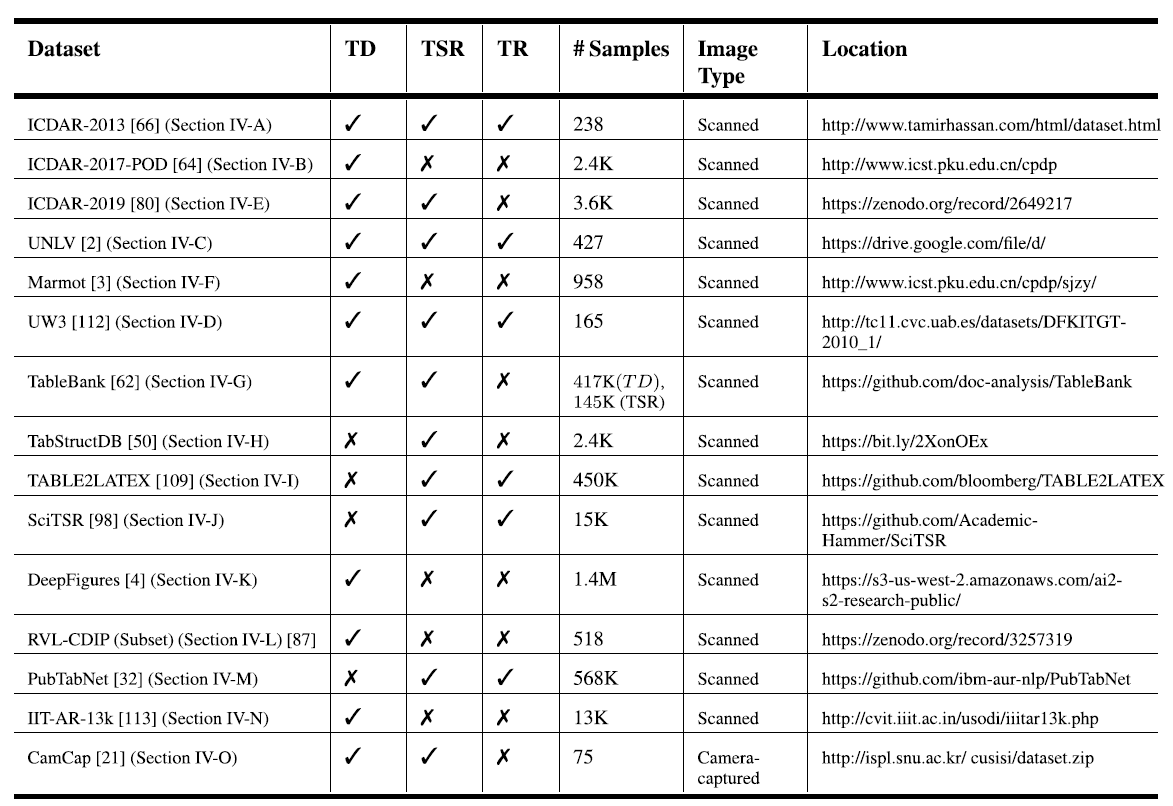
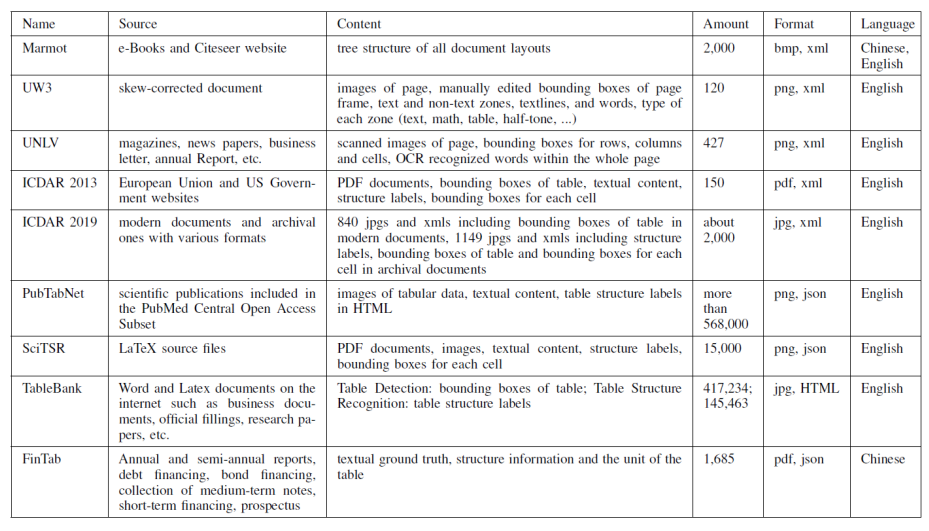
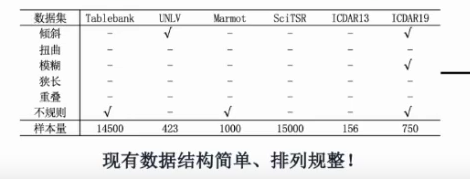
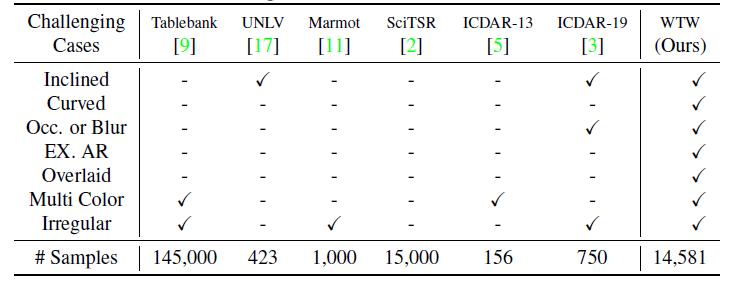
竞赛
ICDAR
| year | picture | 备注 | size | metric |
|---|---|---|---|---|
| 2013 |  |
表格检测,表格格子识别 | 150 | IOU@AP |
| 2019 |   |
The participating methods will be evaluated on a modern dataset and archival documents with printed and handwritten tables present. 表格格子关系预测 | 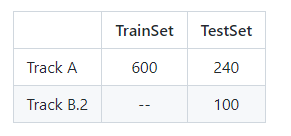 |
P,R,F1 |
| 2021 |  |
表格格子识别,表格结构识别 | 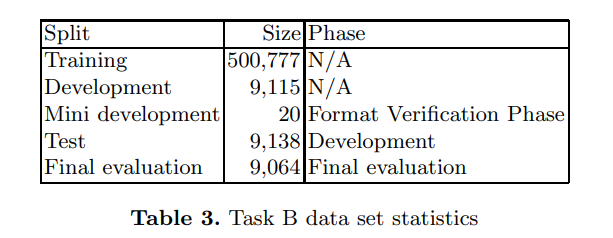 |
TEDS |
2. Datasets
2.1 Introduction
| Dataset | Description | dataset link |
|---|---|---|
| TableBank | English TableBank is a new image-based table detection and recognition dataset built with novel weak supervision from Word and Latex documents on the internet, contains 417K high-quality labeled tables.It only contain cell Topology groudtruth | TableBank |
| SciTSR | *English SciTSR is a large-scale table structure recognition dataset, which contains 15,000 tables in PDF format and their corresponding structure labels obtained from LaTeX source files.It contain cell Topology, cell content groudtruth | SciTSR |
| PubTabNet | English PubTabNet is a large dataset for image-based table recognition, containing 568k+ images of tabular data annotated with the corresponding HTML representation of the tables.It contain cell Topology, cell content and non-blank cell location groudtruth | PubTabNet |
| FinTabNet | English This dataset contains complex tables from the annual reports of S&P 500 companies with detailed table structure annotations to help train and test structure recognition. | FinTabNet |
| PubTables-1M | English A large, detailed, high-quality dataset for training and evaluating a wide variety of models for the tasks of table detection, table structure recognition, and functional analysis. | PubTables-1M |
| WTW | English and Chinese WTW-Dataset is the first wild table dataset for table detection and table structure recongnition tasks, which is constructed from photoing, scanning and web pages, covers 7 challenging cases like: (1)Inclined tables, (2) Curved tables, (3) Occluded tables or blurredtables (4) Extreme aspect ratio tables (5) Overlaid tables, (6) Multi-color tables and (7) Irregular tables in table structure recognition.It contain cell Topology, all cell location groudtruth | WTW |
| TNCR | English a new table dataset with varying image quality collected from open access websites.TNCR contains 9428 labeled tables with approximately 6621 images.their classification into 5 different classes(Full Lined,Merged Cells,No lines,Partial Lined,Partial Lined Merged Cells). | TNCR |
| TAL_OCR_TABLE | Chinese TAL_OCR_TABLE dataset come from TAL Form Recognition Technology Challenge.The data of comes from the real homework of students in the education scene and the scene of the test paper. It contain 16k train image and 4k test imageIt contain cell Topology, cell content and all cell location groudtruth | TAL_OCR_TABLE |
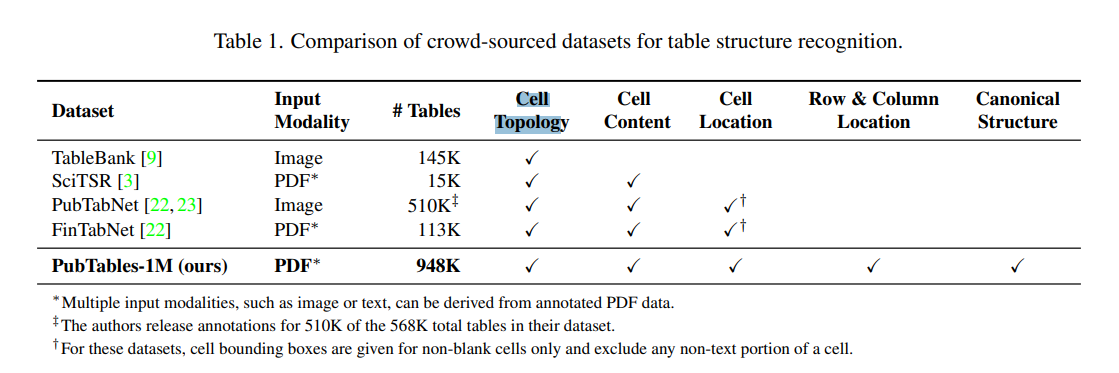
2.2 Comparison of datasets for table structure recognition.
| Dataset | Cell Topology | Cell content | Cell Location | Table Location |
|---|---|---|---|---|
| TableBank | ✓ | ✕ | ✕ | ✓ |
| SciTSR | ✓ | ✓ | ✕ | ✓ |
| PubTabNet | ✓ | ✓ | ✓† | ✓ |
| FinTabNet | ✓ | ✓ | ✓† | ✓ |
| PubTables-1M | ✓ | ✓ | ✓ | ✓ |
| WTW | ✓ | ✕ | ✓ | ✓ |
| TNCR | ✕ | ✕ | ✕ | ✓ |
| TAL_OCR_TABLE | ✓ | ✓ | ✓ | ✓ |
† For these datasets, cell bounding boxes are given for non-blank cells only and exclude any non-text portion of a cell.
badcase数据集
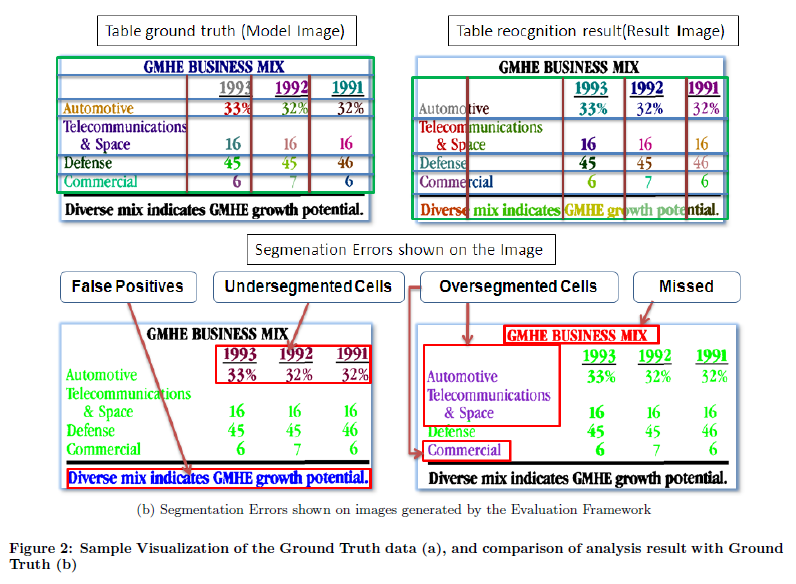
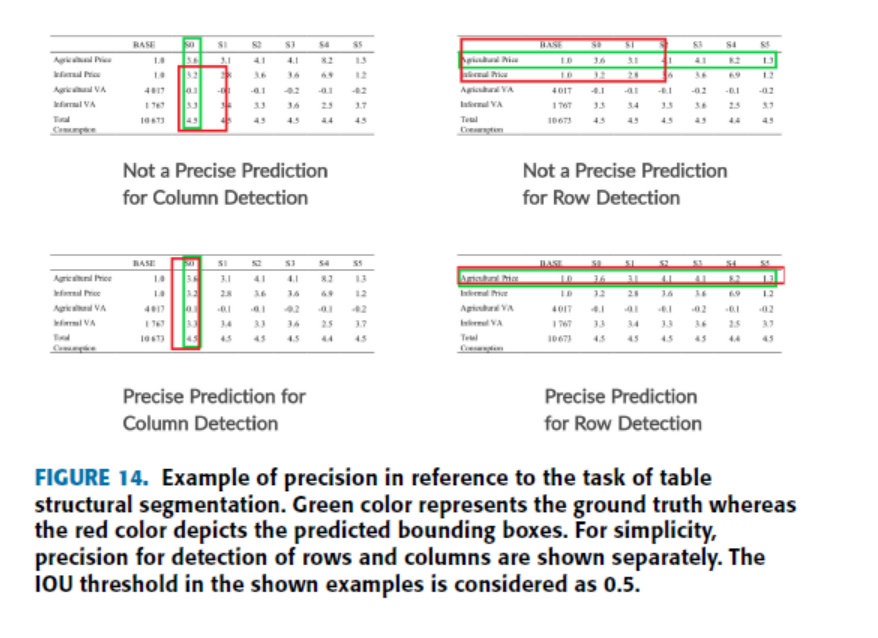
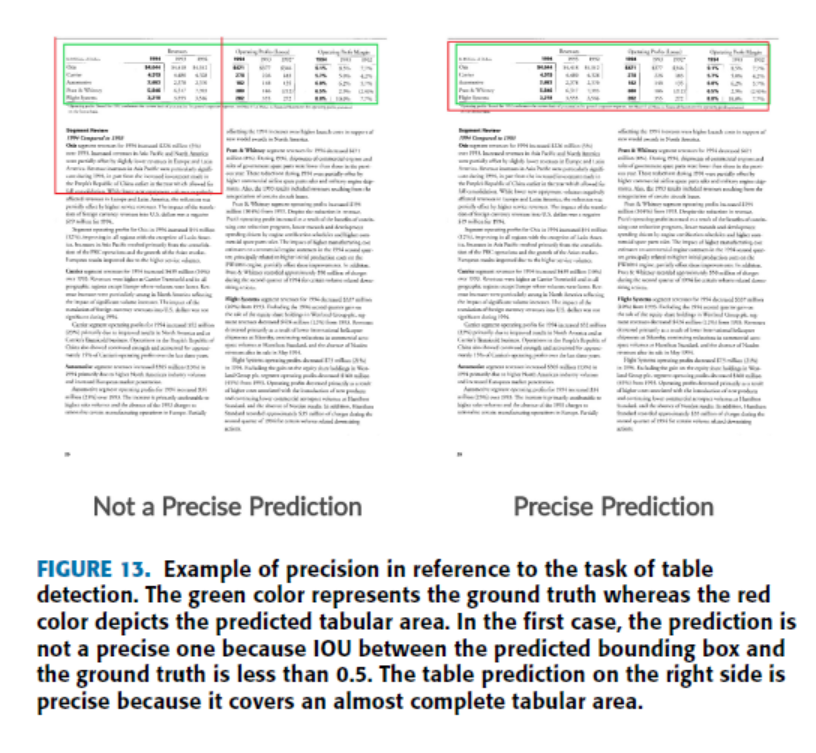
#
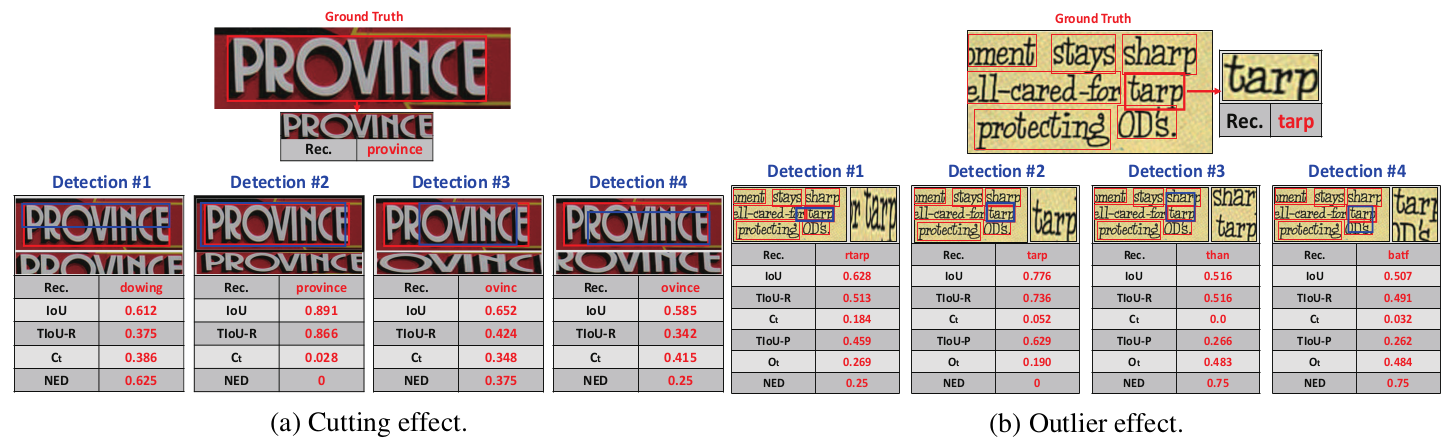
IOU框各场景分析
利用两个 IoU 阈值,前景阈值 (Tf) 和背景阈值 (Tb),我们可以定义以下错误类型(在 TIDE 论文的第 2.2 节中有更详细的解释):
-
分类错误 (CLS):IoU >= Tf 用于不正确类的目标(即,定位正确但分类错误)。
-
定位误差 (LOC):Tb <= IoU < Tf 用于正确类别的目标(即,分类正确但定位不正确)。
-
Cls 和 Loc 错误 (CLS & LOC):Tb <= IoU < Tf 用于不正确类的目标(即,分类和定位不正确)。
-
重复检测错误 (DUP):IoU >= Tf 表示正确类别的目标,但另一个得分较高的检测已经与目标匹配(即,如果不是得分较高的检测,那将是正确的)。
-
背景误差 (BKG):所有目标的 IoU < Tb(即,检测到的背景为前景)。
-
丢失目标错误(MISS):分类或定位错误尚未涵盖的所有未检测到的目标(假阴性)。
Resourse
github
https://github.com/shahrukhqasim/TIES-2.0 Code for: S.R. Qasim, H. Mahmood, and F. Shafait, Rethinking Table Recognition using Graph Neural Networks (2019) TIES was my undergraduate thesis, Table Information Extraction System. I picked the name from there and made it 2.0 from there.
https://github.com/Irene323/GFTE A GCN-based table structure recognition method, which integrates position feature, text feature and image feature together.
https://github.com/jainammm/TableNet About Unofficial implementation of “TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images”
https://github.com/eihli/image-table-ocr Turn images of tables into CSV data. Detect tables from images and run OCR on the cells.
https://github.com/HazyResearch/TreeStructure Fonduer has been successfully extended to perform information extraction from richly formatted data such as tables. A crucial step in this process is the construction of the hierarchical tree of context objects such as text blocks, figures, tables, etc. The system currently uses PDF to HTML conversion provided by Adobe Acrobat converter. Adobe Acrobat converter is not an open source tool and this can be very inconvenient for Fonduer users. We therefore need to build our own module as replacement to Adobe Acrobat. Several open source tools are available for pdf to html conversion but these tools do not preserve the cell structure in a table. Our goal in this project is to develop a tool that extracts text, figures and tables in a pdf document and maintains the structure of the document using a tree data structure.
https://github.com/mawanda-jun/TableTrainNet Table recognition inside douments using neural networks
https://github.com/doc-analysis/TableBank TableBank is a new image-based table detection and recognition dataset built with novel weak supervision from Word and Latex documents on the internet, contains 417K high-quality labeled tables.
https://github.com/cseas/ocr-table This project aims to extract tables from scanned image PDFs using Optical Character Recognition.
https://github.com/eihli/image-table-ocr Turn images of tables into CSV data. Detect tables from images and run OCR on the cells.
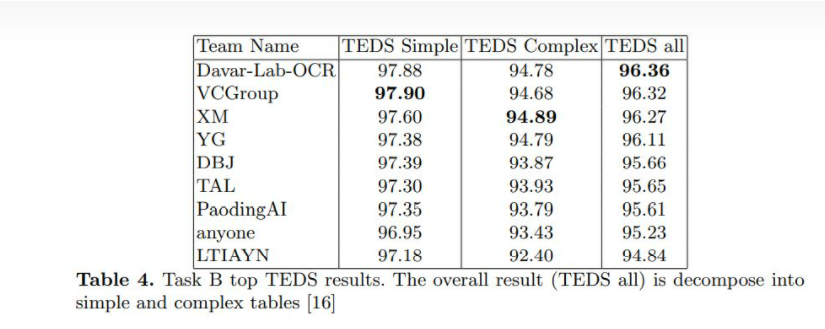
https://github.com/JiaquanYe/TableMASTER-mmocr 2nd solution of ICDAR 2021 Competition on Scientific Literature Parsing, Task B.
##
Other technical solutions
PRCV2021 Table Recognition Technology Challenge
-
Competition First Place Solution
-
Competition Second Place Method
-
Competition Third Place Method
-
ICDAR 2021 Competition on Scientfic Literature Parsing TaskB: Table Recognition to HTML
-
-
Competition First Place Solution
-
Competition Second Place Method