Introduction
本章介绍的是深度玻尔兹曼机(Deep Boltzmann Machines,DBM),应该算是玻尔兹曼机系列的最后一个模型了。我们前面介绍的三种玻尔兹曼机和今天将要介绍的深度玻尔兹曼机的概率图模型如下图所示,从左往右分别是深度信念网络(Deep Belief Network),限制玻尔兹曼机(Restricted Boltzmann Machine,RBM),和DBM,玻尔兹曼机(General Boltzmann Machine,BM):
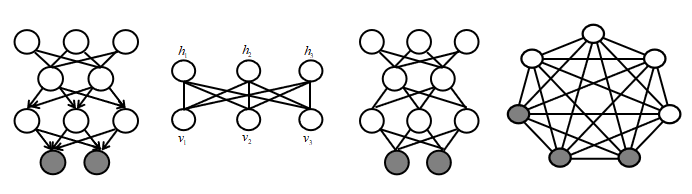
显然,深度玻尔兹曼机和深度信念网络的区别就仅仅在于有向和无向上。其中,RBM,DBM和BM都是玻尔兹曼机,而DBN和玻尔兹曼机就不太一样,实际上是一个混合模型,最上面是RBM,而下面的部分都是有向图。
Boltzmann Machine的发展历史
Boltzmann Machine
最早于1983年诞生的是BM,其概念是来源于Hopfield Network,这个Hopfield Network来源于统计物理学中的Ising Model。看来,机器学习和统计物理还挺有缘的,记得前面见过的吉布斯分布(玻尔兹曼分布)吗,也是来源于统计物理学,包括强化学习中的很多概念也是。BM提出了以后就给出了learning rules。Learning rules就是一个简单的随机梯度上升(Stochastic Gradient Ascend,SGA),SGA的学习规则为:
\[\begin{equation} \triangle w_{ij} = \alpha \left[ \underbrace{\mathbb{E}_{P_{\text{data}}}[v_ih_j]}_{\text{Postive phase}} - \underbrace{\mathbb{E}_{P_{\text{model}}}[v_ih_j]}_{\text{Negative phase}} \right] \end{equation}\] \[\begin{equation} \left\{ \begin{array}{ll} P_{\text{data}} = P_{\text{data}}(v,h) = P_{\text{data}}(v) \cdot P_{\text{model}}(h|v) & \\ P_{\text{model}} = P_{\text{model}}(v,h) & \\ \end{array} \right. \end{equation}\]| 其中,$P_{\text{data}}(v)$表示由$N$个样本组成的经验分布,就是我们的数据,而$P_{\text{model}}(h | v)$是由模型得出的后验分布,$P_{\text{model}}(v,h)$是联合概率分布,也就是模型本身。分布的计算都是通过MCMC采样来完成的,其缺点也很明显,就是无法解决过于复杂的问题,很容易遇到收敛时间过长的问题。所以,后来为了简化模型,提出了只有两层的RBM模型。 |
Restricted Boltzmann Machine
RBM模型相对比较简单。但是Hinton老爷子当时不以为然,觉得RBM模型太简单了,表达力不够好。并于2002年,提出了对比散度(CD)算法,这个算法在之前的“直面配分函数”那章已经做了非常详细的介绍。基于对比散度的采样,实际上就是变了形的Gibbs采样,牺牲了部分精度来提高效率,核心目的就是让采样更加高效。同时,CD算法也给了普通的Boltzmann机的学习算法一些借鉴。然后,后续又发展出了概率对比散度(PCD),一种变形的对比散度,采用的Variational inference来对$P_{\text{model}}(v,h)$进行近似,从而RBM的Learning问题可以得到有效的解决方式,有兴趣的同学可以自己查阅。
Deep Belief Network
因为,RBM的表达能力较弱,所以最简单的思路就是通过叠加多个RBM来增加其层数,从而增加表达能力。但是,增加层数得到的不是Deep Boltzmann Machines,而是Deep Belief Network,具体请详细阅读“深度信念网络”。DBN虽然预训练上是叠加两个RBM而成,但是表现形式并不是玻尔兹曼机。又因为其不是玻尔兹曼机,所以不能用(Stochastic Gradient Ascend,SGA)法来解决。DBN的求解思路为:

算法需要求解的是每一层的权值。第一步则是通过预训练来得到每层的初始值。在后续的Fine-training中,无标签的情况等价于Wake-Sleep算法求解,如果有标签的话大家觉得是不是和神经网络很像,采用BP算法求解。
Deep Boltzmann Machine
2008年以后,诞生了Deep Boltzmann Machine,显然这与DBN有很大的不同之处。在之前介绍的解决Boltzmann Machines的SGA算法,不能解决大规模处理的问题,在DBM的求解中的能力大打折扣。很多研究者都想找到高效的learning rules。其中较好的想法是,先通过预训练来找到一些比较好的权值,然后再使用SGA。大致流程可做如下描述:
如果没有这个预训练的话,效果非常的不好,时间非常的长。因为,权值的初始值没有任何参考,直接就训练太弱了。关于DBM的联合训练方法,就是不通过预训练的方法,这章不作过多介绍。
小结
本小节介绍了四种Boltzmann machine的发展各自的优缺点等。下一小节主要介绍Hinton提出的权值初始化预训练的方法,如何将一层层的RBM进行叠加得到最终的DBM,并介绍其与DBN中的预训练有什么不一样。
参考B站视频【机器学习】【白板推导系列】
更多干货,第一时间更新在以下微信公众号:

您的一点点支持,是我后续更多的创造和贡献

转载到请包括本文地址 更详细的转载事宜请参考文章如何转载/引用